Hierarchical Reinforcement Learning for Optimal Agent Grouping in Cooperative Systems
作者: Liyuan Hu
分类: cs.LG, cs.AI, cs.MA
发布日期: 2025-01-11
备注: 9 pages, 2 figures
💡 一句话要点
提出一种层级强化学习方法,解决合作多智能体系统中的最优分组问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 层级强化学习 多智能体系统 智能体分组 合作博弈 CTDE 置换不变神经网络 Option-Critic
📋 核心要点
- 现有方法在合作多智能体系统中难以同时优化智能体分组和个体策略,面临着探索空间大、协调困难等挑战。
- 该论文提出一种层级强化学习框架,将分组决策置于高层,个体动作置于低层,从而解耦问题,降低复杂性。
- 通过CTDE范式、置换不变网络和改进的option-critic算法,实现高效的集中式训练和可扩展的分布式执行。
📝 摘要(中文)
本文提出了一种层级强化学习(RL)方法,用于解决合作多智能体系统中的智能体分组或配对问题。目标是同时学习最优分组策略和智能体策略。通过采用层级RL框架,我们将分组的高层决策与智能体的低层动作区分开来。我们的方法利用CTDE(集中式训练,分布式执行)范式,确保高效学习和可扩展执行。我们结合了置换不变神经网络来处理智能体之间的同质性和合作,从而实现有效的协调。改进了option-critic算法来管理层级决策过程,从而实现动态和最优的策略调整。
🔬 方法详解
问题定义:论文旨在解决合作多智能体系统中智能体的最优分组问题。现有方法通常难以同时学习分组策略和个体策略,导致训练效率低下,难以扩展到大规模智能体系统。此外,智能体之间的同质性和合作关系也增加了学习的难度。
核心思路:论文的核心思路是将智能体分组问题分解为高层决策和低层动作执行两个层次。高层负责选择最优的分组方式,低层负责执行个体智能体的具体动作。通过这种分层结构,可以有效地降低问题的复杂性,并实现更好的策略学习。
技术框架:整体框架采用层级强化学习结构,包含一个高层option-critic控制器和一个低层智能体策略网络。高层控制器负责选择不同的分组option,低层智能体根据当前分组option执行动作。整个训练过程采用CTDE范式,即集中式训练,分布式执行。在训练阶段,所有智能体的信息都被用于策略学习,而在执行阶段,每个智能体只根据自身观测做出决策。
关键创新:论文的关键创新在于将层级强化学习应用于智能体分组问题,并结合了置换不变神经网络和改进的option-critic算法。置换不变神经网络可以有效地处理智能体之间的同质性,保证分组策略的公平性。改进的option-critic算法可以更好地管理层级决策过程,实现动态和最优的策略调整。
关键设计:论文采用了置换不变神经网络来处理智能体之间的同质性,具体来说,使用了Deep Sets架构。损失函数包括option-critic的策略梯度损失和值函数损失。网络结构方面,高层控制器和低层智能体策略网络都采用了多层感知机(MLP)。具体的参数设置(如学习率、折扣因子等)未知。
🖼️ 关键图片
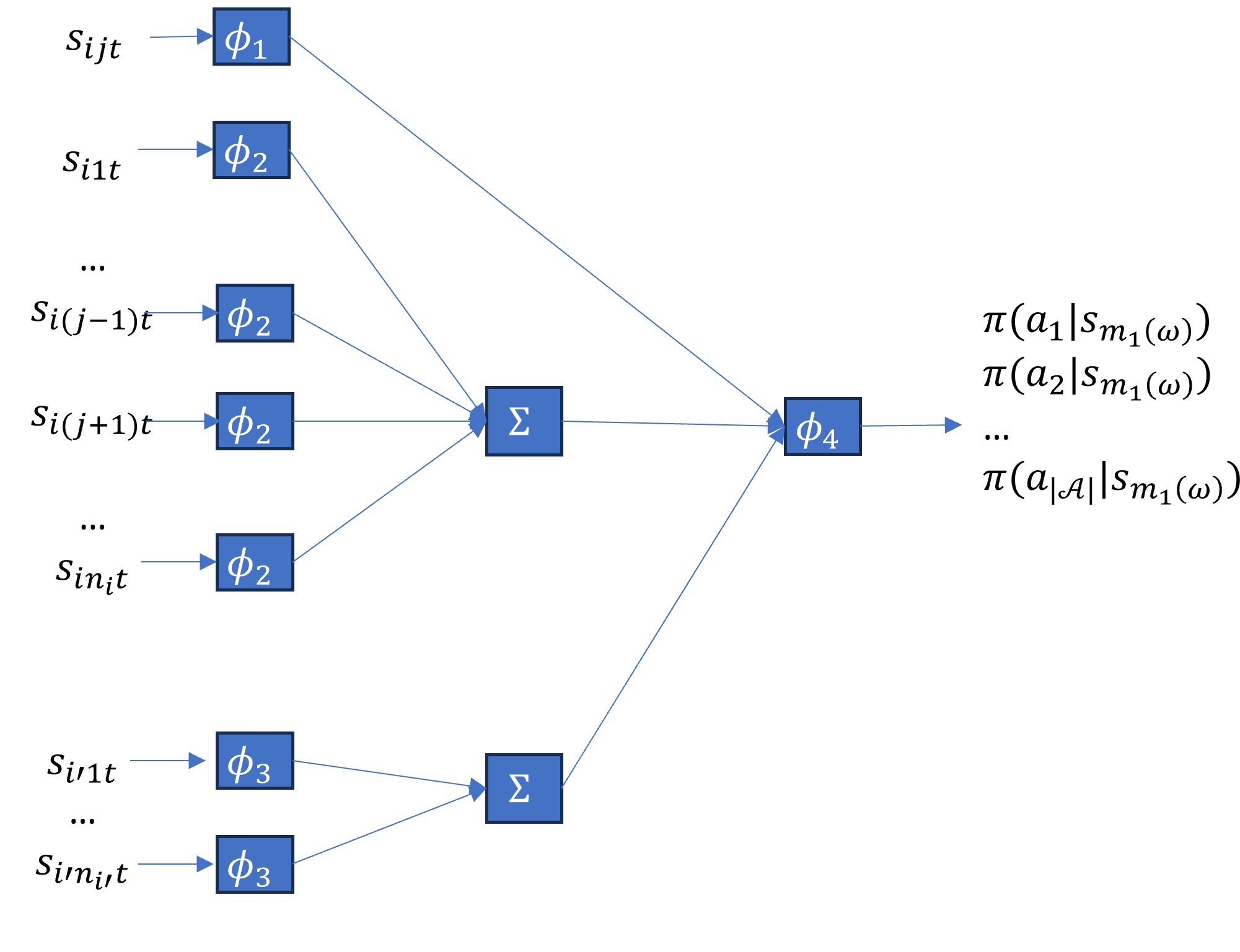
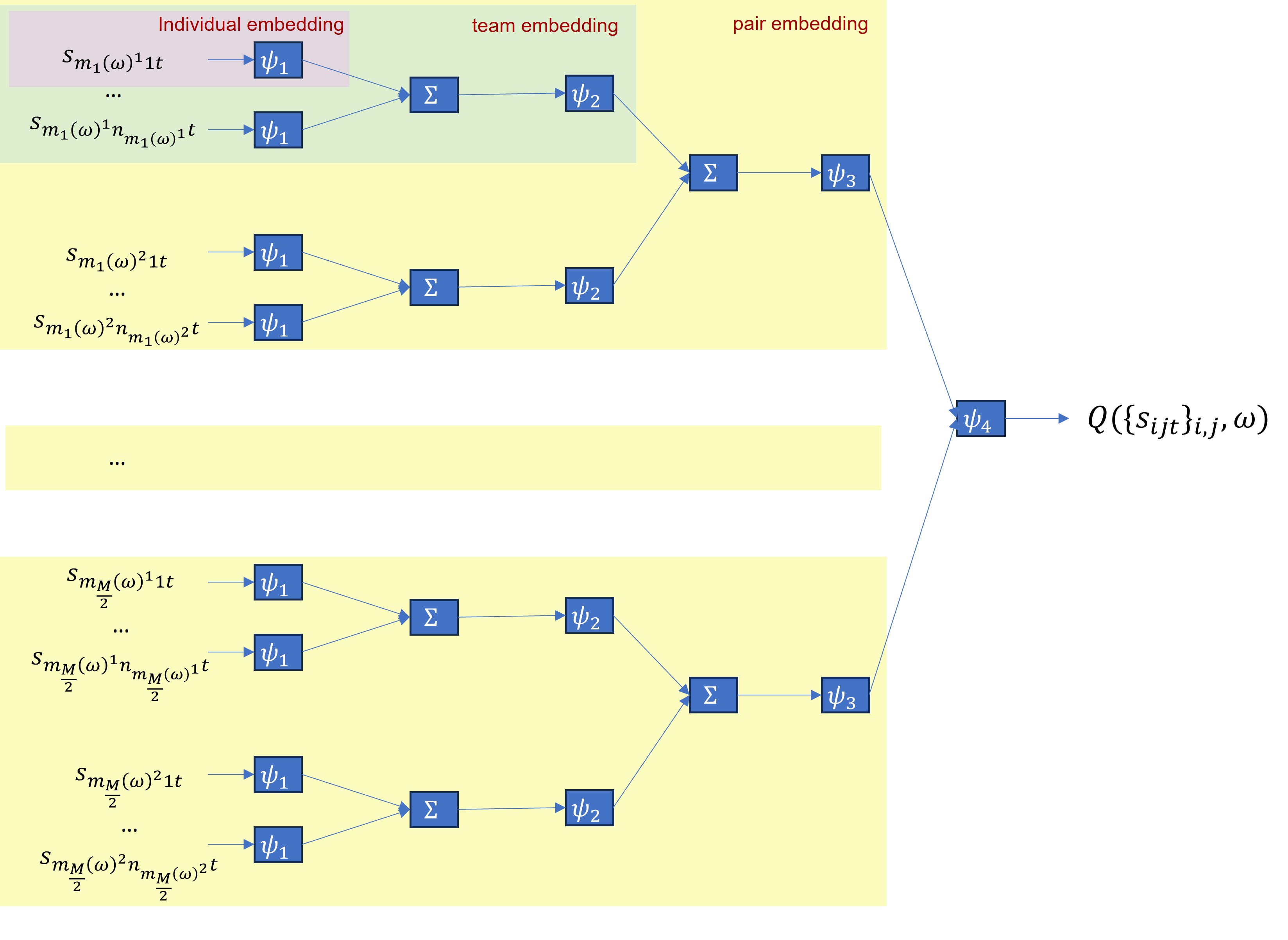
📊 实验亮点
论文通过实验验证了所提出方法的有效性。实验结果表明,该方法在智能体分组任务中取得了显著的性能提升,优于现有的基线方法。具体的性能数据和提升幅度未知,但摘要表明该方法能够实现动态和最优的策略调整。
🎯 应用场景
该研究成果可应用于机器人编队、交通调度、资源分配等领域。例如,在机器人编队中,可以根据任务需求动态调整机器人的分组,提高任务完成效率。在交通调度中,可以将车辆分组,优化交通流量,减少拥堵。该研究具有重要的实际应用价值和潜在的未来影响。
📄 摘要(原文)
This paper presents a hierarchical reinforcement learning (RL) approach to address the agent grouping or pairing problem in cooperative multi-agent systems. The goal is to simultaneously learn the optimal grouping and agent policy. By employing a hierarchical RL framework, we distinguish between high-level decisions of grouping and low-level agents' actions. Our approach utilizes the CTDE (Centralized Training with Decentralized Execution) paradigm, ensuring efficient learning and scalable execution. We incorporate permutation-invariant neural networks to handle the homogeneity and cooperation among agents, enabling effective coordination. The option-critic algorithm is adapted to manage the hierarchical decision-making process, allowing for dynamic and optimal policy adjustments.