Counterfactually Fair Reinforcement Learning via Sequential Data Preprocessing
作者: Jitao Wang, Chengchun Shi, John D. Piette, Joshua R. Loftus, Donglin Zeng, Zhenke Wu
分类: stat.ML, cs.CY, cs.LG, stat.ME
发布日期: 2025-01-10 (更新: 2025-01-14)
💡 一句话要点
提出基于序贯数据预处理的因果公平强化学习框架,解决多阶段决策中的偏差问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 公平性 因果推理 反事实公平 序贯决策 数据预处理 医疗健康 偏差消除
📋 核心要点
- 强化学习在医疗领域的应用可能导致对特定群体的过度优待,加剧社会经济弱势群体的不公平。
- 论文提出基于反事实公平性的序贯数据预处理方法,旨在消除强化学习策略中的偏差,实现公平决策。
- 实验结果表明,该方法在仿真和真实数据集上均能有效控制不公平性,并提升整体策略价值。
📝 摘要(中文)
本研究针对强化学习在医疗健康领域的应用中,策略可能不成比例地将有效干预分配给某一子群体,从而加剧社会经济弱势群体的不公平现象这一问题,提出了一种通用的公平序贯决策框架。该框架基于因果推理中的反事实公平性(CF)概念,对最优CF策略进行了理论刻画并证明了其平稳性,从而简化了最优CF策略的搜索过程,使其能够利用现有的强化学习算法。此外,该理论还促使研究者提出了一种序贯数据预处理算法,以在加性噪声假设下实现CF决策。通过仿真验证了该策略学习方法在控制不公平性和实现最优价值方面的有效性。在减少阿片类药物滥用的数字健康数据集上的分析表明,该方法显著提高了公平获得咨询的机会。
🔬 方法详解
问题定义:在多阶段决策场景下,强化学习策略可能对不同子群体产生差异化的效果,导致某些社会经济弱势群体无法公平地获得有效的干预措施。现有方法难以有效解决这种在序贯决策中产生的偏差,并且这些偏差可能会自我强化,造成严重的负面影响。
核心思路:论文的核心思路是利用反事实公平性(Counterfactual Fairness, CF)的概念,通过干预因果图中的敏感属性,来评估和消除策略中的偏差。具体而言,目标是学习一个策略,使得在干预敏感属性后,策略对所有个体的效果分布尽可能一致,从而实现公平的决策。
技术框架:该框架包含以下几个主要步骤:1) 理论分析:对最优CF策略进行理论刻画,证明其平稳性,这使得可以使用现有的强化学习算法来寻找最优CF策略。2) 序贯数据预处理:基于理论分析,提出一种序贯数据预处理算法,该算法在加性噪声假设下,通过调整数据分布来消除偏差。3) 策略学习:利用预处理后的数据,使用现有的强化学习算法学习CF策略。4) 评估:在仿真和真实数据集上评估CF策略的公平性和有效性。
关键创新:该论文的关键创新在于:1) 提出了一个通用的公平序贯决策框架,该框架可以应用于各种强化学习算法。2) 对最优CF策略进行了理论刻画,并证明了其平稳性,这为寻找最优CF策略提供了理论基础。3) 提出了一种序贯数据预处理算法,该算法可以有效地消除数据中的偏差。
关键设计:论文假设存在加性噪声,并基于此设计了序贯数据预处理算法。该算法通过调整状态和奖励来消除偏差。具体的参数设置和损失函数取决于所使用的强化学习算法。论文中使用了Q-learning算法进行实验验证。
🖼️ 关键图片
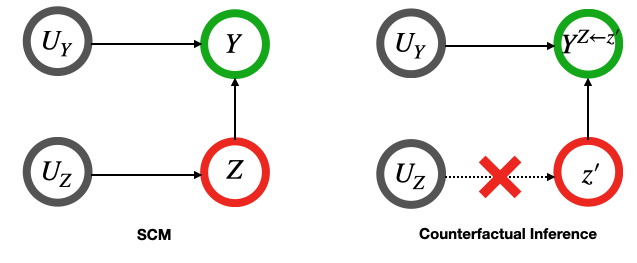
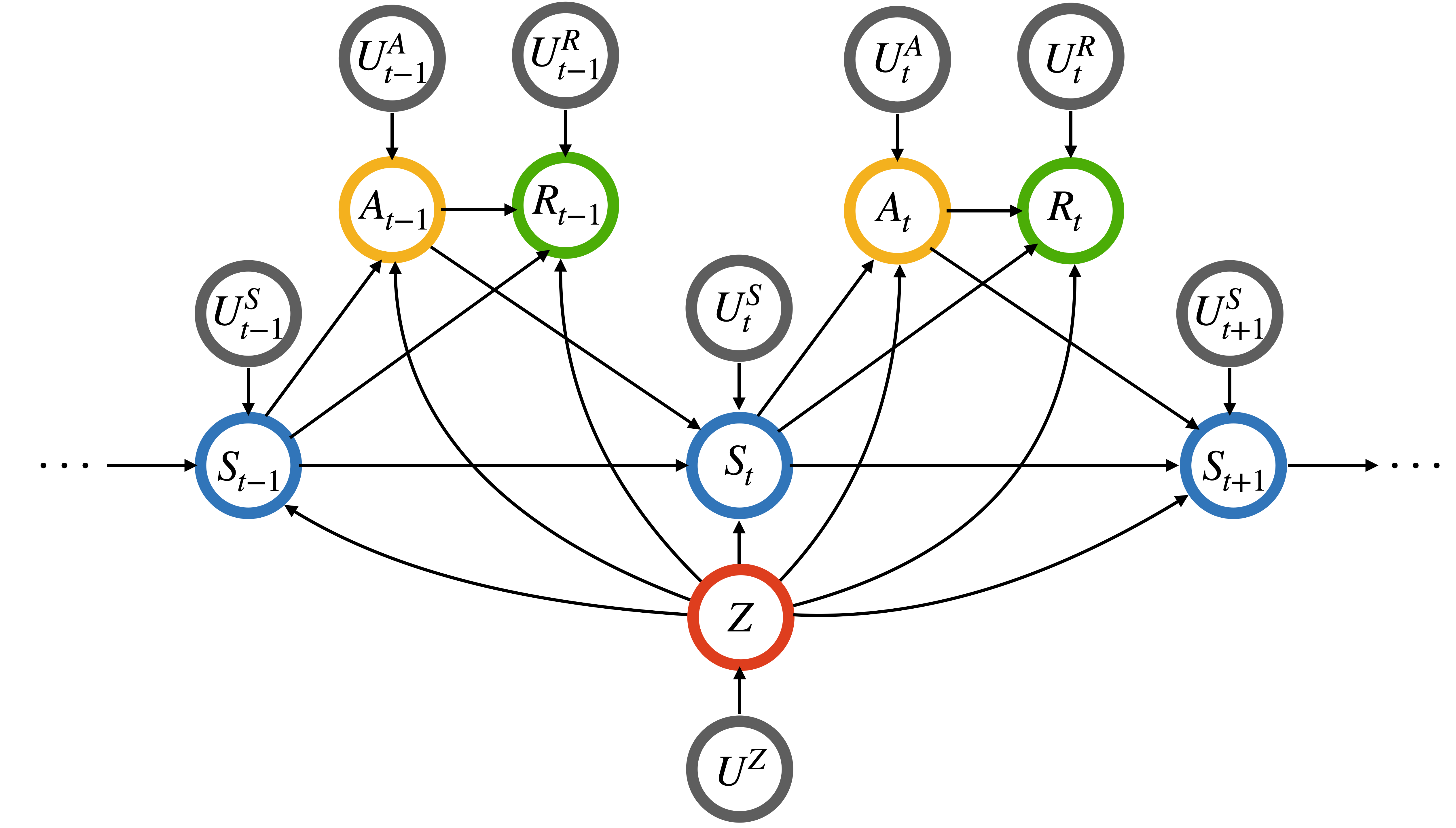
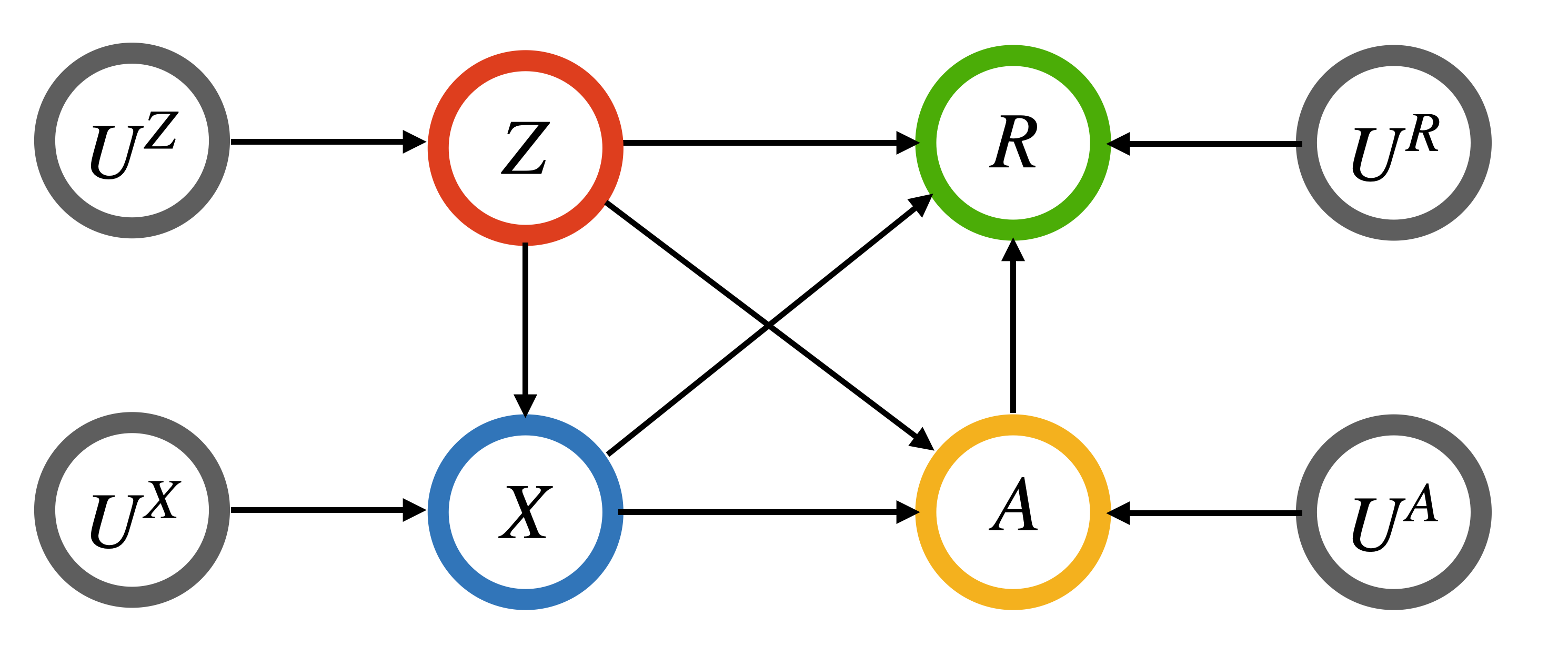
📊 实验亮点
实验结果表明,该方法在仿真环境中能够有效地控制不公平性,并达到接近最优的策略价值。在数字健康数据集上的分析显示,该方法显著提高了弱势群体获得咨询服务的机会。例如,与基线方法相比,该方法能够使更多有阿片类药物滥用风险的患者获得及时的心理咨询,从而降低滥用风险。
🎯 应用场景
该研究成果可广泛应用于医疗健康领域,例如个性化治疗方案推荐、资源分配优化等,尤其是在需要考虑公平性的场景下。通过消除算法偏差,确保不同社会经济背景的患者都能公平地获得优质的医疗服务,从而提升整体的医疗质量和社会公平性。此外,该方法也可推广到其他涉及序贯决策和公平性考量的领域,如教育、金融等。
📄 摘要(原文)
When applied in healthcare, reinforcement learning (RL) seeks to dynamically match the right interventions to subjects to maximize population benefit. However, the learned policy may disproportionately allocate efficacious actions to one subpopulation, creating or exacerbating disparities in other socioeconomically-disadvantaged subgroups. These biases tend to occur in multi-stage decision making and can be self-perpetuating, which if unaccounted for could cause serious unintended consequences that limit access to care or treatment benefit. Counterfactual fairness (CF) offers a promising statistical tool grounded in causal inference to formulate and study fairness. In this paper, we propose a general framework for fair sequential decision making. We theoretically characterize the optimal CF policy and prove its stationarity, which greatly simplifies the search for optimal CF policies by leveraging existing RL algorithms. The theory also motivates a sequential data preprocessing algorithm to achieve CF decision making under an additive noise assumption. We prove and then validate our policy learning approach in controlling unfairness and attaining optimal value through simulations. Analysis of a digital health dataset designed to reduce opioid misuse shows that our proposal greatly enhances fair access to counseling.