Aggregating Low Rank Adapters in Federated Fine-tuning
作者: Evelyn Trautmann, Ian Hales, Martin F. Volk
分类: cs.LG, cs.AI
发布日期: 2025-01-10
备注: presented at conference https://flta-conference.org/flta-2024-detailed-program/
💡 一句话要点
提出一种新的联邦微调中低秩适配器聚合方法,提升GLUE基准性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 参数高效微调 低秩适配器 LoRA 模型聚合
📋 核心要点
- 联邦学习中微调大型语言模型面临通信成本高昂的挑战,参数高效微调方法(PEFT)成为关键。
- 论文提出一种新的低秩适配器(LoRA)聚合方法,旨在提升联邦微调的效率和性能。
- 通过在GLUE基准数据集上的实验,验证了所提出的聚合方法在联邦微调中的有效性。
📝 摘要(中文)
大规模语言模型的微调需要大量的计算和内存资源,因此成本很高。当在联邦数据集上训练时,还需要增加通信量。因此,参数高效方法(PEFT)变得越来越重要。在这种背景下,使用低秩适配方法(LoRA)进行微调已经取得了非常好的结果。LoRA方法在联邦学习中的应用,特别是适配矩阵的聚合,是当前的研究领域。在本文中,我们提出了一种新的聚合方法,并将其与不同的现有低秩适配器聚合方法进行比较,这些适配器在大型机器学习模型的联邦微调中进行训练,并评估它们在选定的GLUE基准数据集上的性能。
🔬 方法详解
问题定义:联邦学习场景下,直接微调大型语言模型参数量巨大,通信成本高昂。现有的联邦学习方法在聚合LoRA适配器时,可能导致性能下降,无法充分利用各个客户端的知识。
核心思路:论文的核心思路是设计一种更有效的LoRA适配器聚合方法,以更好地融合各个客户端学习到的知识,从而提升联邦微调的性能。具体来说,该方法旨在克服现有聚合方法在处理异构数据时可能遇到的问题。
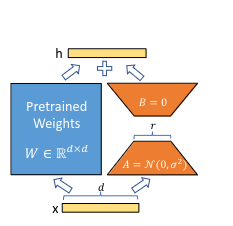
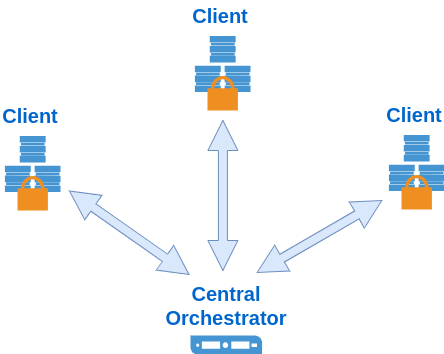
技术框架:论文提出的方法属于联邦学习框架下的模型聚合策略。整体流程包括:1) 各个客户端使用本地数据对LoRA适配器进行微调;2) 将微调后的LoRA适配器参数上传到服务器;3) 服务器使用提出的聚合方法对接收到的LoRA适配器参数进行聚合;4) 将聚合后的LoRA适配器参数下发到各个客户端,用于下一轮的训练。
关键创新:论文的关键创新在于提出了一种新的LoRA适配器聚合方法。虽然摘要中没有明确说明具体方法,但可以推断该方法可能考虑了客户端数据的异构性,并设计了一种更鲁棒的聚合策略,以避免简单平均等方法可能带来的性能损失。与现有方法的本质区别在于聚合策略的不同,旨在更有效地融合各个客户端的知识。
关键设计:由于论文摘要中没有提供具体的算法细节,因此关于关键参数设置、损失函数和网络结构等技术细节未知。未来的论文全文阅读需要关注这些细节。
🖼️ 关键图片

📊 实验亮点
论文通过在GLUE基准数据集上进行实验,验证了所提出的聚合方法的有效性。虽然摘要中没有提供具体的性能数据和提升幅度,但可以推断该方法在某些GLUE任务上取得了比现有方法更好的结果。未来的论文全文阅读需要关注具体的实验设置、对比基线和性能指标。
🎯 应用场景
该研究成果可应用于各种需要联邦学习的场景,例如医疗健康、金融风控等。在这些场景中,数据分布在不同的机构或设备上,无法直接共享,但可以通过联邦学习的方式进行联合训练,提升模型的性能和泛化能力。该研究可以降低联邦学习的通信成本,提高训练效率,促进联邦学习的广泛应用。
📄 摘要(原文)
Fine-tuning large language models requires high computational and memory resources, and is therefore associated with significant costs. When training on federated datasets, an increased communication effort is also needed. For this reason, parameter-efficient methods (PEFT) are becoming increasingly important. In this context, very good results have already been achieved by fine-tuning with low-rank adaptation methods (LoRA). The application of LoRA methods in Federated Learning, and especially the aggregation of adaptation matrices, is a current research field. In this article, we propose a novel aggregation method and compare it with different existing aggregation methods of low rank adapters trained in a federated fine-tuning of large machine learning models and evaluate their performance with respect to selected GLUE benchmark datasets.