Analyzing Memorization in Large Language Models through the Lens of Model Attribution
作者: Tarun Ram Menta, Susmit Agrawal, Chirag Agarwal
分类: cs.LG, cs.AI
发布日期: 2025-01-09
💡 一句话要点
通过模型归因分析大型语言模型中的记忆现象
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 记忆 模型归因 注意力机制 Transformer 泛化能力 隐私保护
📋 核心要点
- 大型语言模型存在记忆训练数据的问题,可能导致隐私泄露和版权侵犯,需要深入研究其内在机制。
- 该论文通过归因技术,系统性地干预LLM架构中的注意力模块,分析其对记忆和泛化性能的影响。
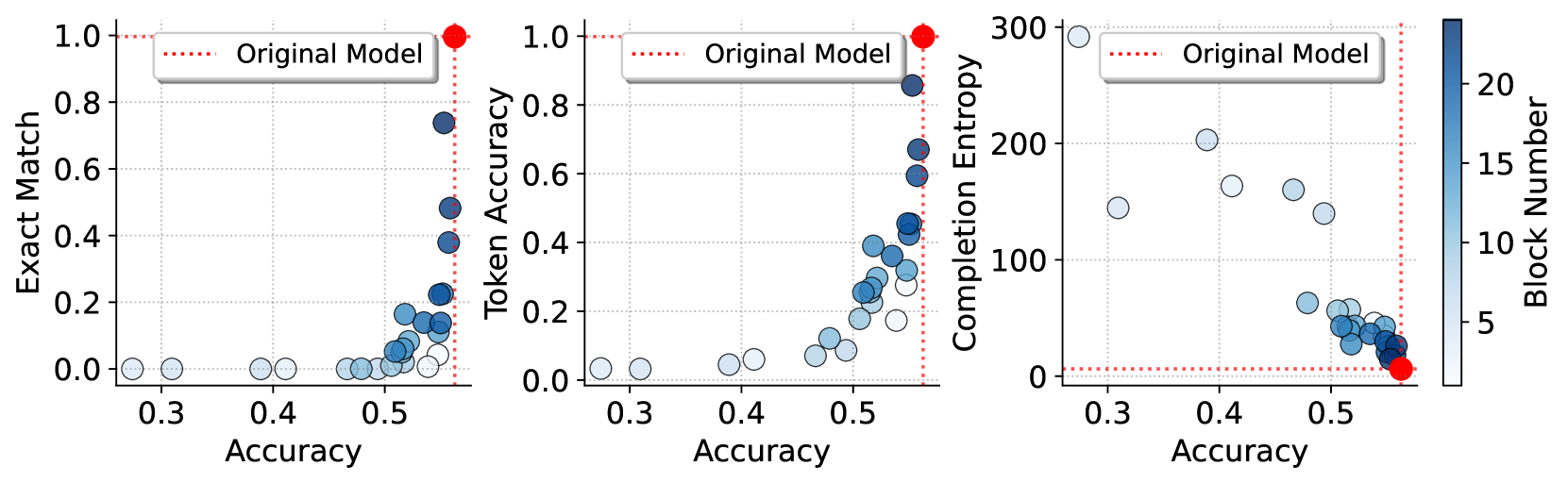
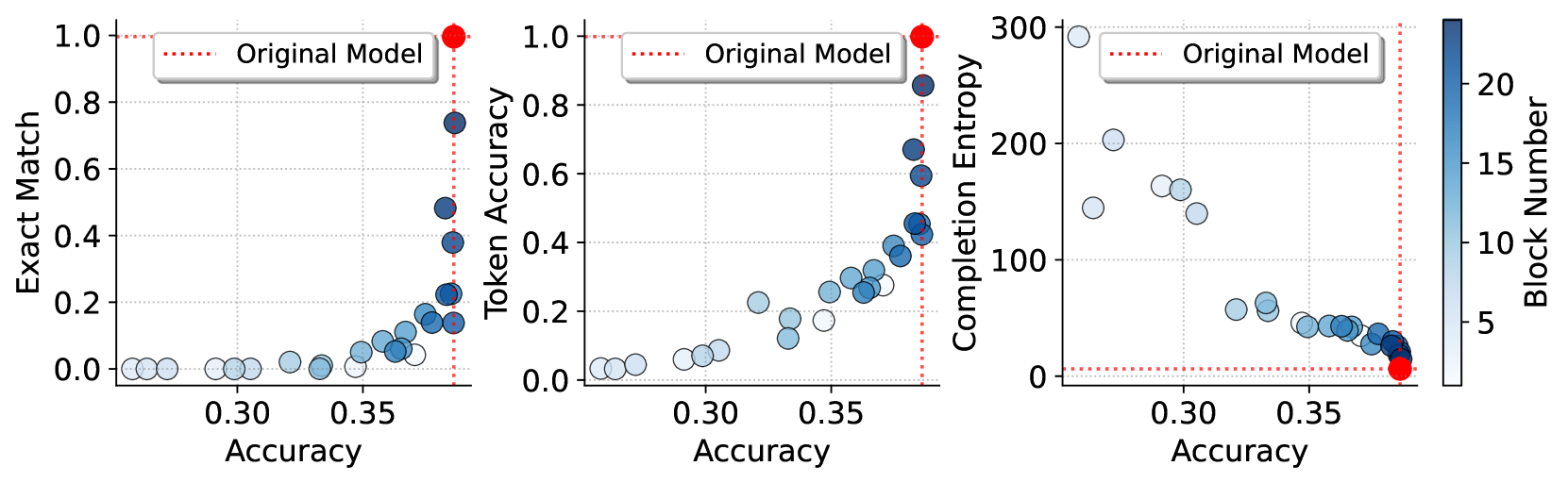
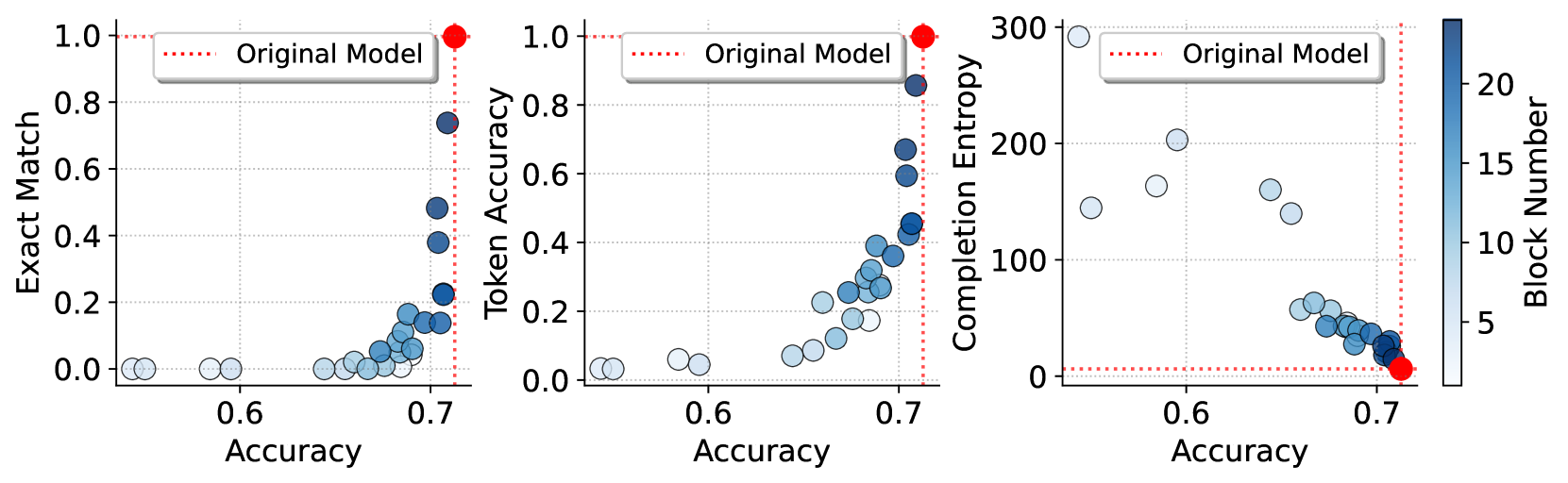
- 实验结果表明,深层Transformer块的注意力模块主要负责记忆,而浅层块对泛化和推理能力至关重要。
📝 摘要(中文)
大型语言模型(LLM)在现代应用中日益普及,但常常会记忆训练数据,导致隐私泄露和版权问题。现有研究主要集中于事后分析,例如提取记忆内容或开发记忆指标,而忽略了探索导致记忆的底层架构因素。本文从架构角度研究记忆现象,分析不同层级的注意力模块如何影响模型的记忆和泛化性能。通过归因技术,系统性地干预LLM架构,绕过特定块的注意力模块,同时保留其他组件(如层归一化和MLP变换)。我们提供了定理,从数学角度分析了干预机制,界定了有无归因时层输出的差异。理论和实验分析表明,更深层Transformer块中的注意力模块主要负责记忆,而较早的块对于模型的泛化和推理能力至关重要。通过在不同LLM家族(Pythia和GPTNeo)和五个基准数据集上的综合实验验证了我们的发现。我们的研究为缓解LLM中的记忆现象提供了一种实用的方法,同时保留其性能,有助于在实际应用中更安全、更合乎伦理地部署。
🔬 方法详解
问题定义:大型语言模型(LLM)在训练过程中会记忆部分训练数据,这带来了隐私泄露和版权风险。现有的研究主要集中在事后分析,例如检测模型是否记住了特定的数据样本,或者评估模型的记忆程度。然而,这些方法缺乏对LLM内部架构如何影响记忆行为的深入理解,无法从根本上解决记忆问题。
核心思路:该论文的核心思路是通过分析LLM内部不同层级的注意力模块对记忆和泛化性能的贡献,来理解LLM的记忆机制。通过有选择性地干预LLM的注意力模块,并观察模型性能的变化,可以推断出不同模块在记忆和泛化中所扮演的角色。这种方法类似于医学上的病灶定位,通过观察切除不同脑区后对认知功能的影响来理解大脑的工作机制。
技术框架:该论文的技术框架主要包括以下几个步骤:1) 选择目标LLM架构(如Pythia和GPTNeo);2) 设计干预策略,即选择性地绕过特定Transformer块中的注意力模块,同时保留其他组件(如层归一化和MLP变换);3) 使用归因技术,量化每个注意力模块对模型输出的贡献;4) 在多个基准数据集上评估干预后的模型性能,包括记忆指标和泛化指标;5) 基于实验结果,分析不同层级的注意力模块对记忆和泛化性能的影响。
关键创新:该论文最重要的技术创新点在于,它将模型归因技术应用于分析LLM的记忆机制。与以往的事后分析方法不同,该论文从架构层面入手,通过干预LLM的内部结构来研究记忆现象。这种方法能够更深入地理解LLM的记忆机制,并为缓解记忆问题提供更有效的解决方案。此外,论文还提供了对干预机制的数学分析,从理论上支持了实验结果。
关键设计:论文的关键设计包括:1) 使用注意力模块旁路作为干预手段,能够精确控制干预的范围和强度;2) 使用多种记忆和泛化指标,全面评估干预后的模型性能;3) 在不同LLM家族和数据集上进行实验,验证结果的泛化性;4) 提供了定理来分析干预机制,从数学上界定了有无归因时层输出的差异。
🖼️ 关键图片
📊 实验亮点
实验结果表明,深层Transformer块的注意力模块主要负责记忆,而浅层块对泛化和推理能力至关重要。通过绕过深层注意力模块,可以在一定程度上缓解LLM的记忆问题,同时保持其泛化性能。例如,在某些数据集上,通过干预深层注意力模块,可以在记忆指标上取得显著降低,而泛化性能几乎没有下降。
🎯 应用场景
该研究成果可应用于开发更安全、更合乎伦理的LLM。通过了解不同层级注意力模块对记忆和泛化的影响,可以设计出能够有效缓解记忆问题,同时保持甚至提升模型性能的LLM架构。这对于保护用户隐私、避免版权纠纷以及提高LLM在实际应用中的可靠性具有重要意义。未来的研究可以进一步探索其他架构因素对记忆的影响,并开发更精细的干预策略。
📄 摘要(原文)
Large Language Models (LLMs) are prevalent in modern applications but often memorize training data, leading to privacy breaches and copyright issues. Existing research has mainly focused on posthoc analyses, such as extracting memorized content or developing memorization metrics, without exploring the underlying architectural factors that contribute to memorization. In this work, we investigate memorization from an architectural lens by analyzing how attention modules at different layers impact its memorization and generalization performance. Using attribution techniques, we systematically intervene in the LLM architecture by bypassing attention modules at specific blocks while keeping other components like layer normalization and MLP transformations intact. We provide theorems analyzing our intervention mechanism from a mathematical view, bounding the difference in layer outputs with and without our attributions. Our theoretical and empirical analyses reveal that attention modules in deeper transformer blocks are primarily responsible for memorization, whereas earlier blocks are crucial for the models generalization and reasoning capabilities. We validate our findings through comprehensive experiments on different LLM families (Pythia and GPTNeo) and five benchmark datasets. Our insights offer a practical approach to mitigate memorization in LLMs while preserving their performance, contributing to safer and more ethical deployment in real world applications.