More is not always better? Enhancing Many-Shot In-Context Learning with Differentiated and Reweighting Objectives
作者: Xiaoqing Zhang, Ang Lv, Yuhan Liu, Flood Sung, Wei Liu, Jian Luan, Shuo Shang, Xiuying Chen, Rui Yan
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-01-07 (更新: 2025-05-27)
备注: 14 pages, 8 figures, 11 tables
🔗 代码/项目: GITHUB
💡 一句话要点
提出DrICL方法,通过差异化和重加权目标增强大语言模型的多样本上下文学习能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 上下文学习 多样本学习 大语言模型 差异化学习 重加权 噪声数据 ICL-50基准
📋 核心要点
- 现有上下文学习方法在样本数量增加时性能下降,主要原因是次优的优化目标和数据噪声。
- DrICL通过差异化学习优化全局NLL目标,并动态调整样本权重,以减轻噪声影响。
- 论文构建了包含50个任务的多样本ICL基准ICL-50,实验证明DrICL能显著提升多样本学习性能。
📝 摘要(中文)
大型语言模型(LLMs)擅长少样本上下文学习(ICL),无需参数更新。然而,随着ICL演示从少到多,性能趋于稳定并最终下降。我们确定了这种趋势的两个主要原因:次优的负对数似然(NLL)优化目标和增量数据噪声。为了解决这些问题,我们引入了DrICL,一种通过差异化和重加权目标来增强模型性能的新型优化方法。全局地,DrICL利用差异化学习来优化NLL目标,确保多样本性能超过零样本水平。局部地,它通过利用受强化学习启发的累积优势来动态调整多样本演示的权重,从而减轻噪声数据的影响。由于缺乏具有多样化多样本分布的多任务数据集,我们开发了多样本ICL基准(ICL-50),这是一个包含50个任务的大规模基准,涵盖了1到350个样本数,序列长度高达8,000个token,用于微调和评估。实验结果表明,通过DrICL增强的LLM在各种任务的多样本设置中取得了显著的改进,包括领域内和领域外场景。我们发布了代码和数据集,希望促进多样本ICL的进一步研究。
🔬 方法详解
问题定义:论文旨在解决大语言模型在多样本上下文学习(ICL)中,随着样本数量增加,性能不升反降的问题。现有的负对数似然(NLL)优化目标在多样本场景下表现次优,且大量样本中不可避免地存在噪声数据,这些噪声会干扰模型的学习,导致性能下降。
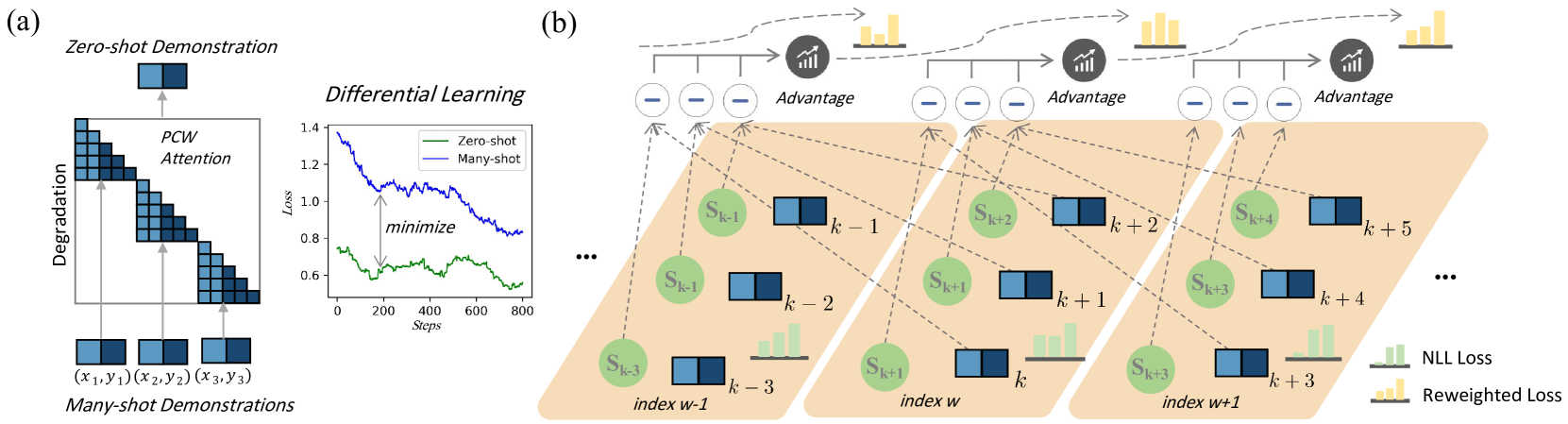
核心思路:论文的核心思路是通过差异化学习和重加权机制来优化多样本ICL。差异化学习旨在全局层面优化NLL目标,确保多样本学习优于零样本学习。重加权机制则在局部层面动态调整每个样本的权重,降低噪声样本的影响,提升模型对有效信息的利用率。
技术框架:DrICL的整体框架包含两个主要部分:差异化NLL优化和动态样本重加权。首先,通过差异化学习策略,调整NLL损失函数的计算方式,使得模型更关注多样本学习带来的增益。其次,利用受强化学习启发的累积优势思想,为每个样本动态分配权重。权重高的样本对损失函数的贡献更大,从而引导模型学习更可靠的知识。
关键创新:DrICL的关键创新在于将差异化学习和动态重加权机制结合起来,分别从全局和局部层面优化多样本ICL。差异化学习确保多样本学习的有效性,而动态重加权则降低了噪声样本的干扰。此外,构建了大规模多样本ICL基准ICL-50,为相关研究提供了数据支撑。
关键设计:在差异化学习方面,具体如何调整NLL损失函数,论文中可能涉及对不同样本的梯度进行缩放或调整。在动态重加权方面,累积优势的具体计算方式,例如如何定义奖励函数、如何进行优势估计等,是关键的技术细节。此外,ICL-50基准的构建,包括任务的选择、样本的生成和标注等,也需要精心设计。
🖼️ 关键图片
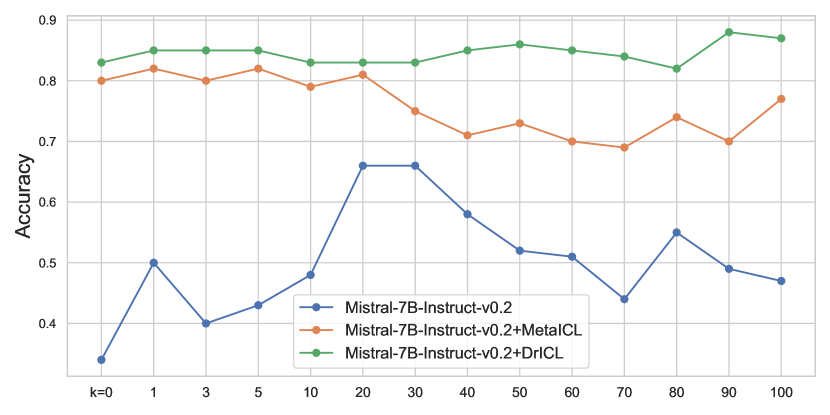

📊 实验亮点
实验结果表明,DrICL方法在多个任务上显著提升了多样本ICL的性能。例如,在ICL-50基准测试中,DrICL在多个任务上超越了现有的基线方法,尤其是在样本数量较多时,性能提升更为明显。论文还验证了DrICL在领域外场景下的泛化能力,证明了其具有良好的实用价值。
🎯 应用场景
该研究成果可应用于各种需要利用大量上下文信息进行预测或决策的场景,例如智能客服、信息检索、文本摘要、代码生成等。通过提升模型在多样本条件下的学习能力,可以有效提高这些应用场景的性能和用户体验,并为未来的大语言模型应用提供更强的基础。
📄 摘要(原文)
Large language models (LLMs) excel at few-shot in-context learning (ICL) without requiring parameter updates. However, as ICL demonstrations increase from a few to many, performance tends to plateau and eventually decline. We identify two primary causes for this trend: the suboptimal negative log-likelihood (NLL) optimization objective and the incremental data noise. To address these issues, we introduce \textit{DrICL}, a novel optimization method that enhances model performance through \textit{Differentiated} and \textit{Reweighting} objectives. Globally, DrICL utilizes differentiated learning to optimize the NLL objective, ensuring that many-shot performance surpasses zero-shot levels. Locally, it dynamically adjusts the weighting of many-shot demonstrations by leveraging cumulative advantages inspired by reinforcement learning, thereby mitigating the impact of noisy data. Recognizing the lack of multi-task datasets with diverse many-shot distributions, we develop the \textit{Many-Shot ICL Benchmark} (ICL-50)-a large-scale benchmark of 50 tasks that cover shot numbers from 1 to 350 within sequences of up to 8,000 tokens-for both fine-tuning and evaluation purposes. Experimental results demonstrate that LLMs enhanced with DrICL achieve significant improvements in many-shot setups across various tasks, including both in-domain and out-of-domain scenarios. We release the code and dataset hoping to facilitate further research in many-shot ICL\footnote{https://github.com/xiaoqzhwhu/DrICL}.