RAG-Check: Evaluating Multimodal Retrieval Augmented Generation Performance
作者: Matin Mortaheb, Mohammad A. Amir Khojastepour, Srimat T. Chakradhar, Sennur Ulukus
分类: cs.LG, cs.CV, cs.IR, cs.IT
发布日期: 2025-01-07
💡 一句话要点
提出RAG-Check框架,用于评估多模态检索增强生成系统的性能,关注检索相关性和生成正确性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态RAG 检索增强生成 性能评估 相关性得分 正确性得分 幻觉检测 视觉语言模型
📋 核心要点
- 多模态RAG系统存在检索到不相关信息和生成幻觉内容的问题,降低了系统的可靠性。
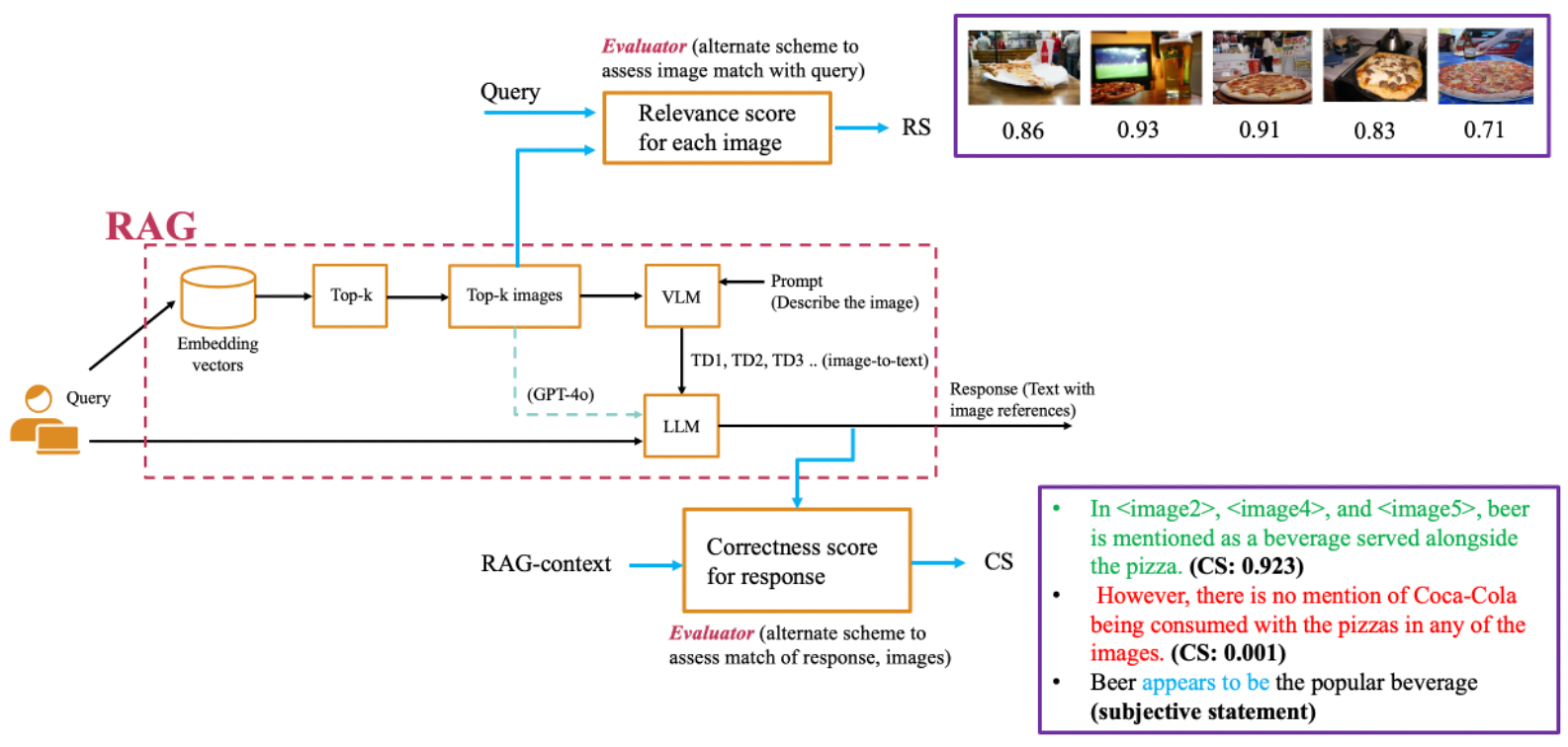
- 提出RAG-Check框架,通过相关性得分(RS)和正确性得分(CS)来评估检索和生成过程的质量。
- 实验结果表明,提出的RS和CS模型与人类判断具有较高的一致性,能够有效评估RAG系统的性能。
📝 摘要(中文)
检索增强生成(RAG)通过利用外部知识来指导响应生成,从而改进大型语言模型(LLM),减少幻觉。然而,RAG,特别是多模态RAG,可能会引入新的幻觉来源:(i)检索过程可能从数据库中选择不相关的片段(例如,文档、图像)作为原始上下文,以及(ii)检索到的图像通过视觉-语言模型(VLM)被处理成基于文本的上下文,或者直接被多模态语言模型(MLLM)(如GPT-4o)使用,这可能会产生幻觉。为了解决这个问题,我们提出了一个新颖的框架来评估多模态RAG的可靠性,使用两个性能指标:(i)相关性得分(RS),评估检索到的条目与查询的相关性,以及(ii)正确性得分(CS),评估生成的响应的准确性。我们使用ChatGPT衍生的数据库和人工评估器样本来训练RS和CS模型。结果表明,两个模型在测试数据上都达到了约88%的准确率。此外,我们构建了一个包含5000个样本的人工标注数据库,评估检索到的片段的相关性和响应语句的正确性。我们的RS模型在检索中比CLIP更频繁地与人类偏好一致(高出20%),并且我们的CS模型与人类偏好匹配约91%的时间。最后,我们使用RS和CS评估了各种RAG系统的选择和生成性能。
🔬 方法详解
问题定义:论文旨在解决多模态检索增强生成(RAG)系统中存在的两个主要问题:一是检索到的信息与用户查询的相关性不足,二是生成的回答中存在不准确或虚假的内容(即幻觉)。现有方法难以有效评估和解决这些问题,缺乏可靠的评估指标和工具。
核心思路:论文的核心思路是通过构建两个评估模型,即相关性得分(RS)模型和正确性得分(CS)模型,来量化RAG系统的检索质量和生成质量。RS模型评估检索到的信息与查询的相关程度,CS模型评估生成回答的准确性。通过这两个指标,可以全面评估RAG系统的性能。
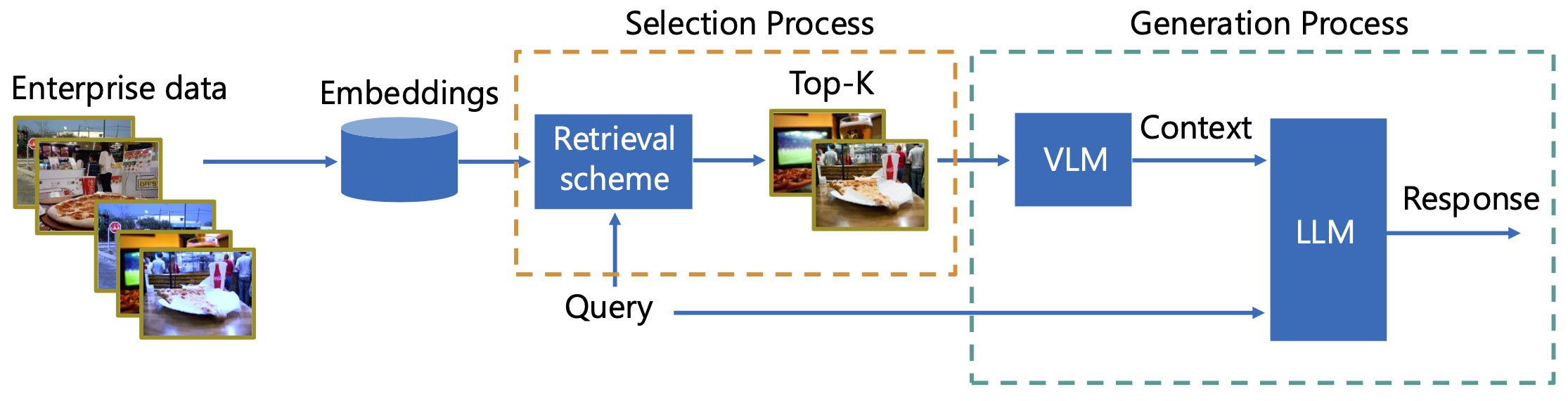
技术框架:RAG-Check框架包含以下主要模块:1) 数据收集与标注:构建包含查询、检索到的信息、生成回答以及人工标注的数据集。2) 模型训练:使用标注数据训练RS和CS模型,使其能够自动评估检索相关性和生成正确性。3) 性能评估:使用训练好的RS和CS模型评估不同的RAG系统,并与人工评估结果进行对比。
关键创新:论文的关键创新在于提出了一个完整的评估框架,能够同时评估多模态RAG系统的检索质量和生成质量。RS和CS模型的训练依赖于ChatGPT生成的数据和人工标注数据,使得评估结果更贴近人类的判断标准。此外,论文还构建了一个大规模的人工标注数据集,为RAG系统的评估提供了宝贵资源。
关键设计:RS和CS模型的具体实现细节未知,但可以推测其可能基于Transformer架构,并采用分类或回归任务进行训练。损失函数可能包括交叉熵损失或均方误差损失。数据集的构建和标注过程至关重要,需要保证标注质量和数据多样性。
🖼️ 关键图片

📊 实验亮点
RS和CS模型在测试数据上达到了约88%的准确率。RS模型在检索相关性判断上比CLIP模型更符合人类偏好(高出20%)。CS模型在生成正确性判断上与人类偏好匹配度高达91%。这些结果表明,RAG-Check框架能够有效评估多模态RAG系统的性能。
🎯 应用场景
该研究成果可应用于各种需要利用多模态信息进行问答或内容生成的场景,例如智能客服、教育辅助、医疗诊断等。通过RAG-Check框架,可以有效评估和优化RAG系统的性能,提高生成内容的质量和可靠性,减少幻觉现象。
📄 摘要(原文)
Retrieval-augmented generation (RAG) improves large language models (LLMs) by using external knowledge to guide response generation, reducing hallucinations. However, RAG, particularly multi-modal RAG, can introduce new hallucination sources: (i) the retrieval process may select irrelevant pieces (e.g., documents, images) as raw context from the database, and (ii) retrieved images are processed into text-based context via vision-language models (VLMs) or directly used by multi-modal language models (MLLMs) like GPT-4o, which may hallucinate. To address this, we propose a novel framework to evaluate the reliability of multi-modal RAG using two performance measures: (i) the relevancy score (RS), assessing the relevance of retrieved entries to the query, and (ii) the correctness score (CS), evaluating the accuracy of the generated response. We train RS and CS models using a ChatGPT-derived database and human evaluator samples. Results show that both models achieve ~88% accuracy on test data. Additionally, we construct a 5000-sample human-annotated database evaluating the relevancy of retrieved pieces and the correctness of response statements. Our RS model aligns with human preferences 20% more often than CLIP in retrieval, and our CS model matches human preferences ~91% of the time. Finally, we assess various RAG systems' selection and generation performances using RS and CS.