Context-Alignment: Activating and Enhancing LLM Capabilities in Time Series
作者: Yuxiao Hu, Qian Li, Dongxiao Zhang, Jinyue Yan, Yuntian Chen
分类: cs.LG, cs.CL, stat.AP
发布日期: 2025-01-07 (更新: 2026-01-07)
备注: This paper has been accepted by ICLR 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出Context-Alignment框架,激活并增强LLM在时间序列任务中的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时间序列预测 大型语言模型 上下文对齐 少样本学习 图神经网络
📋 核心要点
- 现有方法在激活LLM的时间序列能力时,过度依赖token级别对齐,忽略了LLM对语言逻辑和结构的深层理解。
- Context-Alignment框架通过结构对齐和逻辑对齐,将时间序列数据与LLM熟悉的语言环境对齐,使LLM能够理解时间序列的上下文信息。
- 实验表明,FSCA方法在少样本和零样本时间序列预测任务中表现出色,验证了Context-Alignment框架的有效性。
📝 摘要(中文)
本文提出Context-Alignment (CA) 框架,旨在激活和增强大型语言模型(LLM)在时间序列(TS)任务中的能力。现有方法侧重于token级别的对齐,忽略了LLM在自然语言处理方面的固有优势,即对语言逻辑和结构的深刻理解。CA通过将时间序列与LLM熟悉的语言环境中的语言成分对齐,使LLM能够理解时间序列数据的上下文,从而激活其能力。具体而言,这种上下文级别的对齐包括结构对齐和逻辑对齐,通过应用于时间序列-语言多模态输入的双尺度上下文对齐图神经网络(DSCA-GNN)实现。结构对齐利用双尺度节点来描述时间序列-语言中的分层结构,使LLM能够将长时间序列数据视为一个整体语言成分,同时保留内在的token特征。逻辑对齐使用有向边来引导逻辑关系,确保上下文语义的连贯性。基于DSCA-GNN框架,我们提出了一种CA的实例化方法,称为Few-Shot prompting Context-Alignment (FSCA),以增强预训练LLM处理时间序列任务的能力。FSCA可以灵活地、重复地集成到预训练LLM的各个层中,以提高对逻辑和结构的感知,从而提高性能。大量实验表明了FSCA的有效性以及Context-Alignment在各项任务中的重要性,尤其是在少样本和零样本预测中,证实了Context-Alignment提供了强大的上下文先验知识。
🔬 方法详解
问题定义:现有方法在利用LLM处理时间序列任务时,主要关注token级别的对齐,这忽略了LLM在理解语言逻辑和结构方面的强大能力。这些方法无法充分利用LLM的上下文理解能力,导致在少样本或零样本场景下表现不佳。因此,需要一种新的方法,能够更好地激活LLM在时间序列任务中的潜力。
核心思路:本文的核心思路是将时间序列数据与LLM熟悉的语言环境进行对齐,即Context-Alignment。通过将时间序列数据转化为LLM能够理解的语言结构和逻辑关系,使LLM能够利用其固有的语言理解能力来处理时间序列任务。这种方法旨在弥合时间序列数据和自然语言之间的语义鸿沟,从而激活LLM的潜力。
技术框架:Context-Alignment框架主要包含两个关键组成部分:结构对齐和逻辑对齐。这两个部分通过双尺度上下文对齐图神经网络(DSCA-GNN)实现。DSCA-GNN接收时间序列-语言多模态输入,利用双尺度节点描述时间序列-语言中的分层结构,并使用有向边引导逻辑关系。在此基础上,提出了Few-Shot prompting Context-Alignment (FSCA) 方法,将Context-Alignment集成到预训练LLM中,以增强其处理时间序列任务的能力。FSCA可以灵活地集成到LLM的各个层中。
关键创新:该论文的关键创新在于提出了Context-Alignment这一新的范式,它强调将时间序列数据与LLM熟悉的语言环境对齐,而不是仅仅关注token级别的对齐。与现有方法相比,Context-Alignment能够更好地利用LLM的语言理解能力,从而在时间序列任务中取得更好的性能。DSCA-GNN的设计也是一个创新点,它能够有效地捕捉时间序列数据中的结构和逻辑关系。
关键设计:DSCA-GNN使用双尺度节点来描述时间序列-语言中的分层结构,其中一种尺度的节点表示token级别的特征,另一种尺度的节点表示更高层次的结构信息。有向边的设计用于表示时间序列数据中的逻辑关系,例如因果关系或时间依赖关系。FSCA通过few-shot prompting的方式,引导LLM学习时间序列数据的上下文信息。具体的参数设置和损失函数等技术细节在论文中进行了详细描述。
🖼️ 关键图片


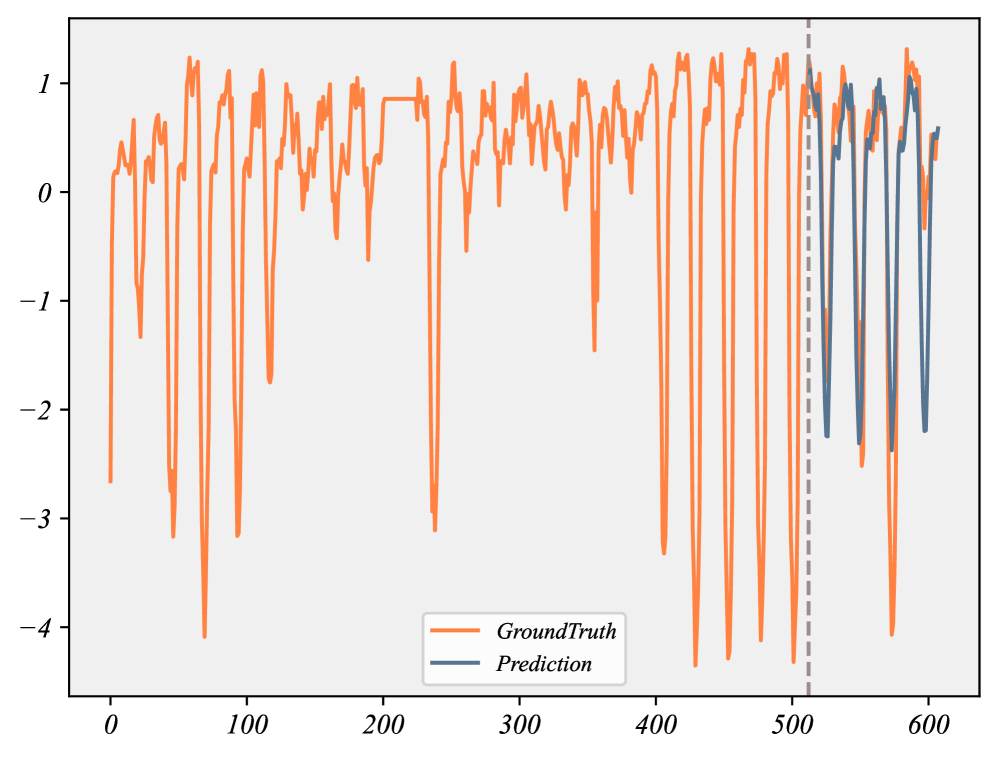
📊 实验亮点
实验结果表明,FSCA方法在少样本和零样本时间序列预测任务中取得了显著的性能提升。具体而言,FSCA在多个benchmark数据集上超越了现有的时间序列预测方法,尤其是在数据量较少的情况下,提升幅度更为明显。这些结果验证了Context-Alignment框架的有效性,并表明其能够为LLM提供强大的上下文先验知识。
🎯 应用场景
Context-Alignment框架具有广泛的应用前景,可应用于金融预测、医疗诊断、工业监控等领域。通过利用LLM强大的语言理解能力,可以提高时间序列预测的准确性和鲁棒性,从而为决策提供更可靠的依据。该研究的未来影响在于,它为利用LLM解决时间序列问题提供了一种新的思路,有望推动时间序列分析领域的发展。
📄 摘要(原文)
Recently, leveraging pre-trained Large Language Models (LLMs) for time series (TS) tasks has gained increasing attention, which involves activating and enhancing LLMs' capabilities. Many methods aim to activate LLMs' capabilities based on token-level alignment, but overlook LLMs' inherent strength in natural language processing -- \textit{their deep understanding of linguistic logic and structure rather than superficial embedding processing.} We propose Context-Alignment (CA), a new paradigm that aligns TS with a linguistic component in the language environments familiar to LLMs to enable LLMs to contextualize and comprehend TS data, thereby activating their capabilities. Specifically, such context-level alignment comprises structural alignment and logical alignment, which is achieved by Dual-Scale Context-Alignment GNNs (DSCA-GNNs) applied to TS-language multimodal inputs. Structural alignment utilizes dual-scale nodes to describe hierarchical structure in TS-language, enabling LLMs to treat long TS data as a whole linguistic component while preserving intrinsic token features. Logical alignment uses directed edges to guide logical relationships, ensuring coherence in the contextual semantics. Following the DSCA-GNNs framework, we propose an instantiation method of CA, termed Few-Shot prompting Context-Alignment (FSCA), to enhance the capabilities of pre-trained LLMs in handling TS tasks. FSCA can be flexibly and repeatedly integrated into various layers of pre-trained LLMs to improve awareness of logic and structure, thereby enhancing performance. Extensive experiments show the effectiveness of FSCA and the importance of Context-Alignment across tasks, particularly in few-shot and zero-shot forecasting, confirming that Context-Alignment provides powerful prior knowledge on context. The code is open-sourced at https://github.com/tokaka22/ICLR25-FSCA.