Rethinking Adversarial Attacks in Reinforcement Learning from Policy Distribution Perspective
作者: Tianyang Duan, Zongyuan Zhang, Zheng Lin, Yue Gao, Ling Xiong, Yong Cui, Hongbin Liang, Xianhao Chen, Heming Cui, Dong Huang
分类: cs.LG, cs.AI
发布日期: 2025-01-07 (更新: 2025-01-08)
备注: 10 pages, 2 figures, 2 tables
💡 一句话要点
提出分布感知投影梯度下降攻击以解决DRL中的对抗攻击问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 对抗攻击 深度强化学习 策略分布 机器人导航 鲁棒性评估
📋 核心要点
- 现有对抗攻击方法主要针对单个动作样本,无法有效影响整体策略分布,尤其在连续动作空间中表现不佳。
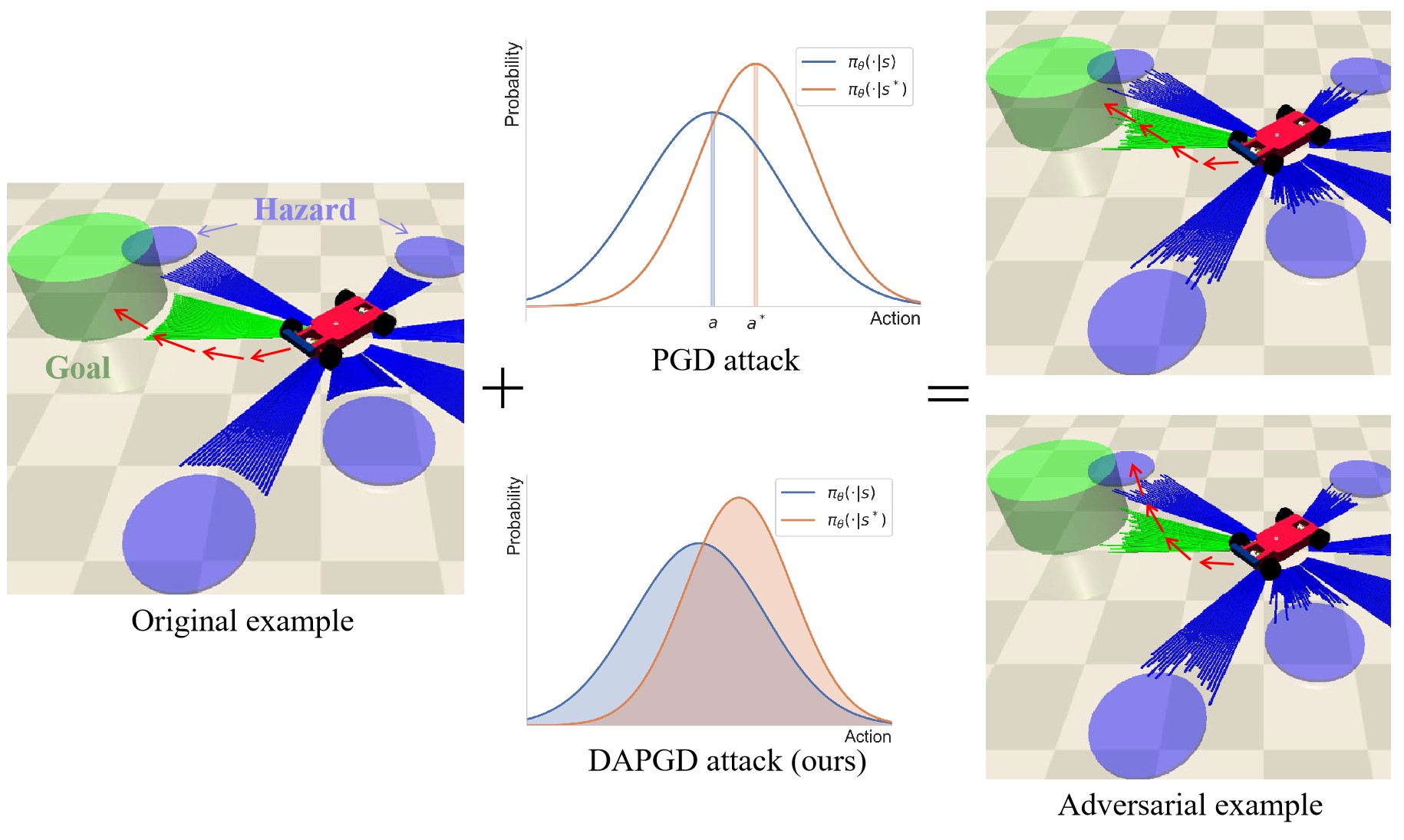
- 本文提出的DAPGD方法通过利用分布相似性来进行攻击,关注整个策略分布而非单个样本,从而提升攻击效果。
- 实验结果显示,DAPGD在三个机器人导航任务中表现优异,平均奖励下降幅度比最佳基线高出22.03%,展现出更强的攻击能力。
📝 摘要(中文)
深度强化学习(DRL)在实际应用中面临观察信号的不确定性和不准确性。对抗攻击是一种有效评估DRL代理鲁棒性的方法。然而,现有针对单个采样动作的攻击方法对整体策略分布的影响有限,尤其是在连续动作空间中。为了解决这些局限性,本文提出了分布感知投影梯度下降攻击(DAPGD),该方法利用分布相似性作为梯度扰动输入,攻击策略网络,从而利用整个策略分布而非单个样本。实验结果表明,DAPGD在三个机器人导航任务中相比基线取得了最先进的结果,平均奖励下降幅度比最佳基线高出22.03%。
🔬 方法详解
问题定义:本文旨在解决现有对抗攻击方法在深度强化学习中的不足,特别是其对整体策略分布影响的局限性。现有方法主要集中在单个动作样本,导致在连续动作空间中效果不佳。
核心思路:提出的DAPGD方法通过引入分布相似性作为梯度扰动输入,攻击策略网络,关注整个策略分布的变化。这种设计使得攻击更加全面,能够有效识别和利用策略分布中的微小差异。
技术框架:DAPGD的整体架构包括三个主要模块:首先,计算当前策略分布与目标策略分布之间的相似性;其次,利用Bhattacharyya距离来量化这种相似性;最后,基于相似性计算的梯度进行策略网络的扰动。
关键创新:DAPGD的核心创新在于其利用分布相似性进行攻击的思路,与传统方法仅依赖单个样本的方式本质上不同。这种方法能够更敏感地捕捉到策略分布中的细微变化,从而提升攻击效果。
关键设计:在技术细节上,DAPGD使用了Bhattacharyya距离作为衡量策略相似性的指标,确保了对策略分布的敏感检测。此外,损失函数的设计也考虑了整体策略分布的影响,使得攻击更加有效。
🖼️ 关键图片

📊 实验亮点
实验结果表明,DAPGD在三个机器人导航任务中表现优异,平均奖励下降幅度比最佳基线高出22.03%。这一结果展示了DAPGD在对抗攻击中的有效性,超越了现有的攻击方法,具有显著的性能提升。
🎯 应用场景
该研究的潜在应用领域包括机器人导航、自动驾驶和智能控制系统等,能够帮助提升这些系统在面对对抗性环境时的鲁棒性和安全性。未来,DAPGD方法有望被广泛应用于强化学习的安全性评估和防御机制的设计中,推动智能系统的可靠性提升。
📄 摘要(原文)
Deep Reinforcement Learning (DRL) suffers from uncertainties and inaccuracies in the observation signal in realworld applications. Adversarial attack is an effective method for evaluating the robustness of DRL agents. However, existing attack methods targeting individual sampled actions have limited impacts on the overall policy distribution, particularly in continuous action spaces. To address these limitations, we propose the Distribution-Aware Projected Gradient Descent attack (DAPGD). DAPGD uses distribution similarity as the gradient perturbation input to attack the policy network, which leverages the entire policy distribution rather than relying on individual samples. We utilize the Bhattacharyya distance in DAPGD to measure policy similarity, enabling sensitive detection of subtle but critical differences between probability distributions. Our experiment results demonstrate that DAPGD achieves SOTA results compared to the baselines in three robot navigation tasks, achieving an average 22.03% higher reward drop compared to the best baseline.