Align-Pro: A Principled Approach to Prompt Optimization for LLM Alignment
作者: Prashant Trivedi, Souradip Chakraborty, Avinash Reddy, Vaneet Aggarwal, Amrit Singh Bedi, George K. Atia
分类: cs.LG, cs.AI
发布日期: 2025-01-07
备注: 27 pages, Accepted in AAAI 2025
💡 一句话要点
Align-Pro:一种基于原则的LLM对齐提示优化方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 LLM对齐 提示优化 优化理论 理论分析
📋 核心要点
- 现有LLM对齐方法(如RLHF)计算成本高,且在模型参数不可访问时失效。
- 论文将提示优化形式化为优化问题,并从理论上分析其最优性,填补了理论空白。
- 实验证明,即使无法进行参数微调,提示优化也能有效对齐LLM,具有实际应用价值。
📝 摘要(中文)
随着大型语言模型(LLM)日益融入社会和决策过程,使其与人类价值观对齐至关重要。传统的对齐方法,如基于人类反馈的强化学习(RLHF),通过微调模型参数来实现对齐,但这些方法通常计算成本高昂,且当模型被冻结或无法修改参数时,不切实际。相比之下,提示优化是LLM对齐的一种可行替代方案。虽然现有文献已显示提示优化具有经验上的前景,但其理论基础仍未得到充分探索。我们通过将提示优化公式化为一个优化问题来弥补这一差距,并尝试提供对此类框架最优性的理论见解。为了分析提示优化的性能,我们研究了理论次优性界限,并提供了关于提示优化如何依赖于给定的提示器和目标模型的见解。我们还通过在各种数据集上的实验提供了经验验证,证明即使在参数微调不可行的情况下,提示优化也能有效地对齐LLM。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)与人类价值观对齐的问题。现有方法,如基于人类反馈的强化学习(RLHF),需要对模型参数进行微调,这在计算上非常昂贵,并且当模型被冻结或无法访问参数时是不可行的。因此,需要一种无需微调模型参数即可实现对齐的方法。
核心思路:论文的核心思路是将提示优化(Prompt Optimization)视为一个优化问题,通过优化提示来引导LLM产生符合人类价值观的输出。这种方法无需修改模型参数,因此适用于模型被冻结或无法微调的场景。论文旨在从理论上分析提示优化的最优性,并提供关于提示优化性能的理论保证。
技术框架:论文没有明确提出一个具体的架构或流程图,而是侧重于理论分析。其核心在于将提示优化问题建模为一个优化问题,并研究其理论性质。主要涉及以下几个方面:1) 形式化提示优化问题;2) 推导理论次优性界限,分析提示优化性能;3) 研究提示优化对提示器(Prompter)和目标模型(Target Model)的依赖性。
关键创新:论文最重要的创新点在于从理论上分析了提示优化的最优性。现有研究主要集中在经验验证,而该论文首次尝试从理论上理解提示优化,并提供了关于其性能的理论保证。这有助于更好地理解提示优化,并为设计更有效的提示优化算法提供理论指导。
关键设计:论文的关键设计在于将提示优化问题形式化为一个优化问题,并利用优化理论的工具来分析其性能。具体的技术细节包括:1) 定义合适的损失函数来衡量LLM输出与人类价值观的偏差;2) 推导理论次优性界限,分析提示优化性能;3) 研究提示优化对提示器和目标模型的依赖性。论文没有涉及具体的网络结构或参数设置,而是侧重于理论分析。
🖼️ 关键图片

📊 实验亮点
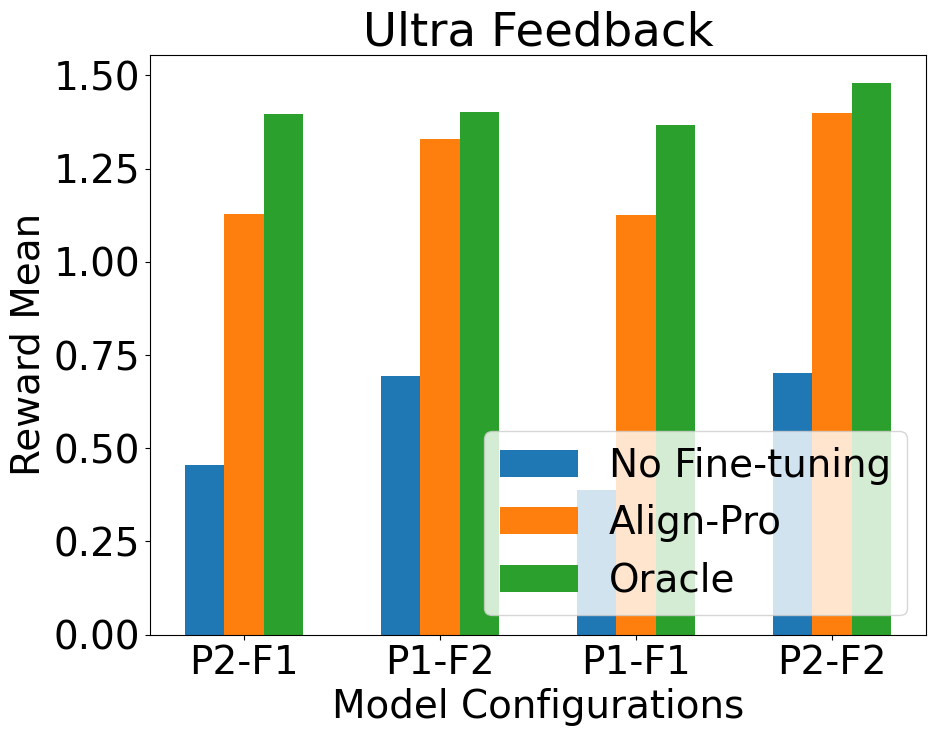
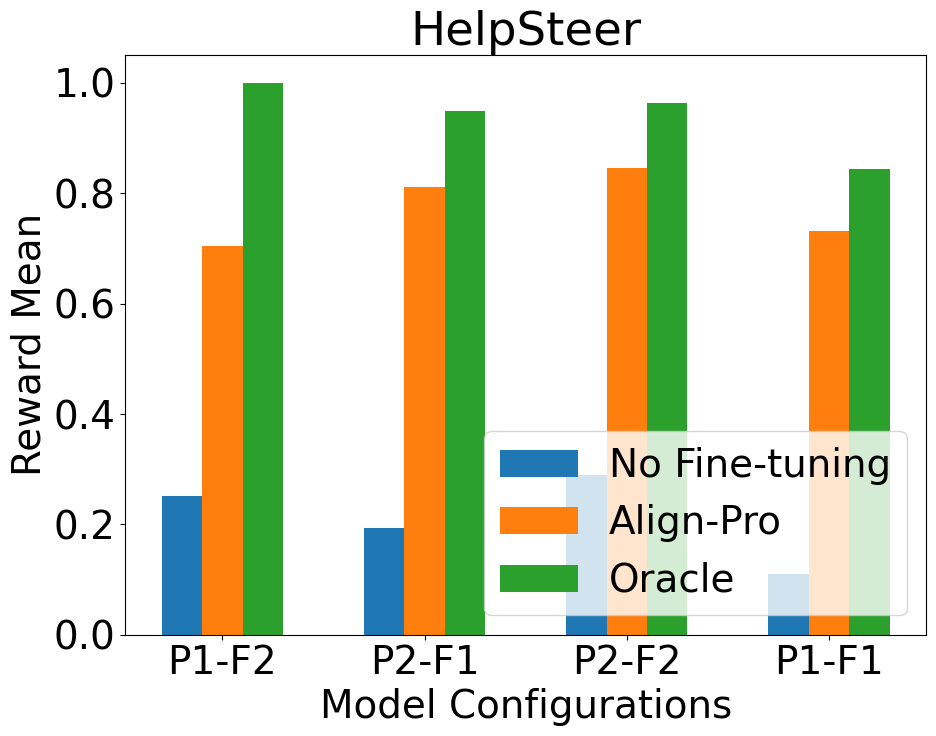
论文通过在各种数据集上的实验验证了提示优化的有效性,证明即使在参数微调不可行的情况下,提示优化也能有效地对齐LLM。虽然论文没有给出具体的性能数据和提升幅度,但实验结果表明提示优化是一种可行的LLM对齐方法,尤其是在模型被冻结或无法微调的场景下。
🎯 应用场景
该研究成果可应用于各种需要LLM与人类价值观对齐的场景,例如:自动内容生成、智能客服、决策支持系统等。通过提示优化,可以引导LLM生成更安全、更符合伦理道德的输出,从而提高LLM在实际应用中的可靠性和安全性。未来的研究可以进一步探索更有效的提示优化算法,并将其应用于更广泛的领域。
📄 摘要(原文)
The alignment of large language models (LLMs) with human values is critical as these models become increasingly integrated into various societal and decision-making processes. Traditional methods, such as reinforcement learning from human feedback (RLHF), achieve alignment by fine-tuning model parameters, but these approaches are often computationally expensive and impractical when models are frozen or inaccessible for parameter modification. In contrast, prompt optimization is a viable alternative to RLHF for LLM alignment. While the existing literature has shown empirical promise of prompt optimization, its theoretical underpinning remains under-explored. We address this gap by formulating prompt optimization as an optimization problem and try to provide theoretical insights into the optimality of such a framework. To analyze the performance of the prompt optimization, we study theoretical suboptimality bounds and provide insights in terms of how prompt optimization depends upon the given prompter and target model. We also provide empirical validation through experiments on various datasets, demonstrating that prompt optimization can effectively align LLMs, even when parameter fine-tuning is not feasible.