Multi-Modal One-Shot Federated Ensemble Learning for Medical Data with Vision Large Language Model
作者: Naibo Wang, Yuchen Deng, Shichen Fan, Jianwei Yin, See-Kiong Ng
分类: cs.LG, cs.AI
发布日期: 2025-01-06
💡 一句话要点
FedMME:利用视觉大语言模型的多模态单次联邦集成学习框架,提升医疗数据诊断精度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 多模态学习 视觉大语言模型 医学图像分析 单次联邦学习
📋 核心要点
- 现有联邦学习方法通信开销大,且医学诊断依赖单一模态数据,限制了诊断准确性和全面性。
- 提出FedMME框架,利用视觉大语言模型提取医学图像文本特征,融合多模态信息提升诊断。
- 实验表明,FedMME在多个数据集上显著优于现有单次联邦学习方法,例如在RSNA数据集上提升超过17.5%。
📝 摘要(中文)
联邦学习因其在保护数据隐私的同时促进协作模型训练的能力,在医学领域引起了广泛关注。然而,传统的联邦学习方法通常需要多次通信,导致显著的通信开销和延迟,尤其是在带宽受限的环境中。单次联邦学习通过在单轮通信中进行模型训练和聚合来解决这些问题,从而降低通信成本并保护隐私。其中,单次联邦集成学习结合了独立训练的客户端模型,使用投票等集成技术,进一步提高了在非独立同分布(non-IID)数据场景下的性能。另一方面,现有的医疗保健机器学习方法主要使用单模态数据(例如,医学图像或文本报告),这限制了它们的诊断准确性和全面性。因此,提出了多模态数据的集成来解决这些缺点。本文介绍了一种创新的单次多模态联邦集成学习框架FedMME,该框架利用多模态数据进行医学图像分析。具体来说,FedMME利用视觉大语言模型从医学图像生成文本报告,使用BERT模型从这些报告中提取文本特征,并将这些特征与视觉特征融合,以提高诊断准确性。实验结果表明,在各种数据分布的四个数据集上,与现有的医疗保健场景中的单次联邦学习方法相比,我们的方法表现出卓越的性能。例如,在应用Dirichlet分布(α = 0.3)时,它在RSNA数据集上的准确率超过了现有的单次联邦学习方法17.5%以上。
🔬 方法详解
问题定义:现有联邦学习方法在医学图像分析中存在通信开销大和诊断准确性不足的问题。传统的联邦学习需要多轮通信,导致延迟高,不适用于带宽受限的环境。此外,现有方法通常只使用单一模态的数据(如医学图像或文本报告),忽略了多模态信息融合的潜力,限制了诊断的准确性和全面性。
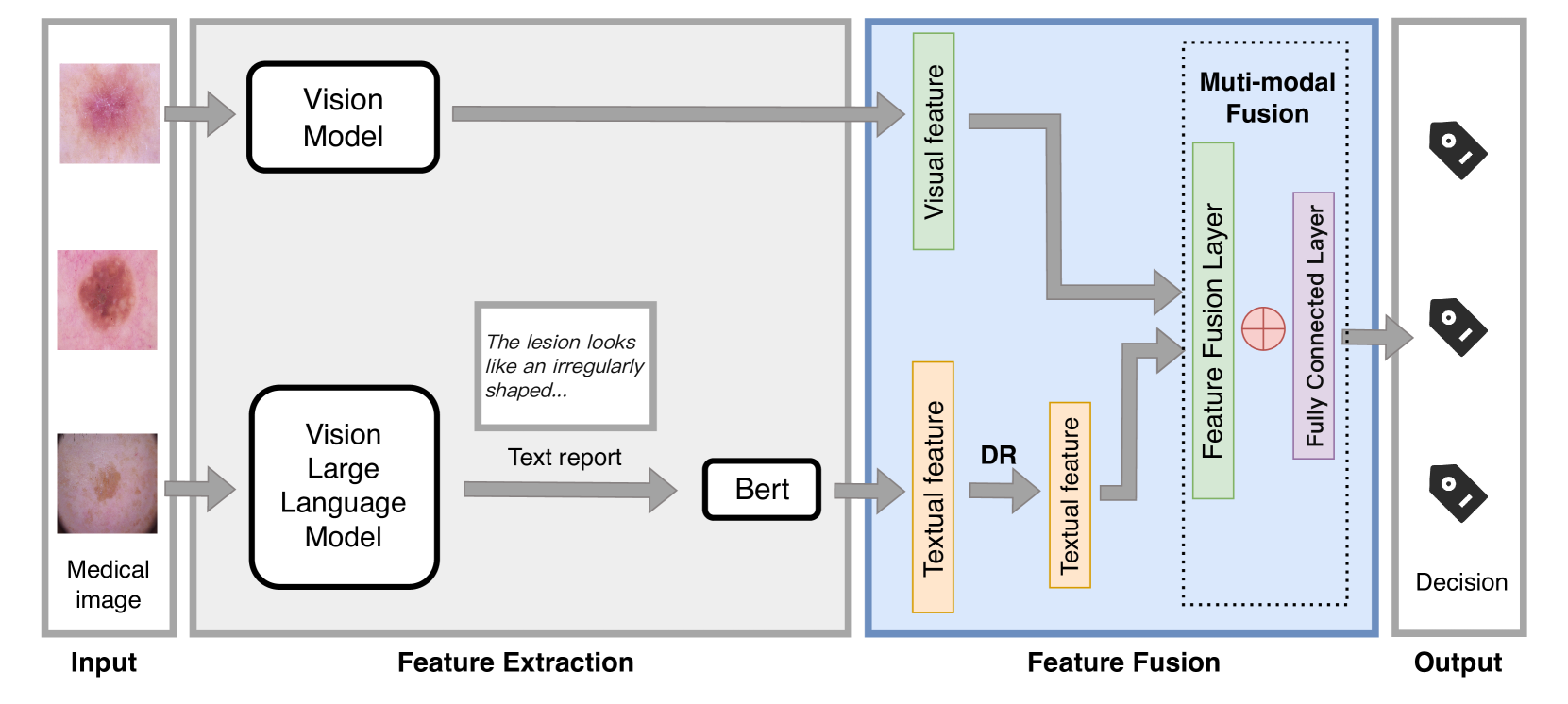
核心思路:FedMME的核心思路是利用单次联邦学习减少通信开销,并融合多模态数据(医学图像和文本报告)以提高诊断准确性。通过视觉大语言模型将医学图像转化为文本报告,再提取文本特征,与图像特征融合,从而利用更全面的信息进行诊断。
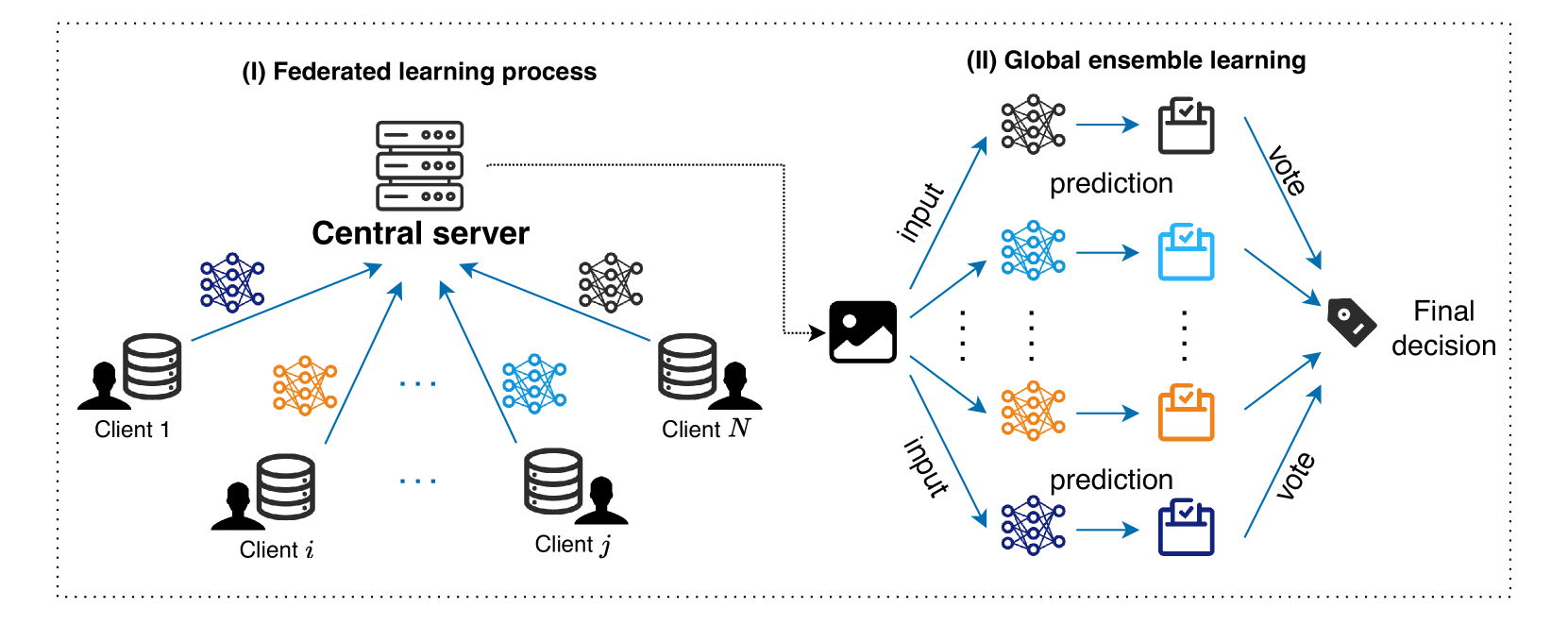
技术框架:FedMME框架包含以下主要模块:1)客户端本地训练:每个客户端使用本地数据独立训练模型。2)视觉大语言模型:利用视觉大语言模型从医学图像生成文本报告。3)文本特征提取:使用BERT模型从文本报告中提取文本特征。4)多模态特征融合:将图像特征和文本特征进行融合。5)模型集成:使用集成学习技术(如投票)将各个客户端的模型进行集成。
关键创新:FedMME的关键创新在于:1) 提出了一种基于视觉大语言模型的多模态联邦学习框架,能够有效融合医学图像和文本报告的信息。2) 采用单次联邦学习,显著降低了通信开销。3) 通过多模态特征融合和模型集成,提高了诊断的准确性和鲁棒性。与现有方法的本质区别在于,FedMME充分利用了多模态数据,并在保证隐私的前提下,实现了高效的联邦学习。
关键设计:在视觉大语言模型方面,具体选择的模型未知,但需要能够有效生成医学图像的文本描述。BERT模型的选择需要考虑其在医学文本处理方面的性能。多模态特征融合的方式可能包括简单的拼接、加权平均或更复杂的注意力机制。模型集成可以使用简单的投票机制,也可以使用更高级的集成方法,例如stacking。损失函数的选择需要根据具体的诊断任务进行调整,例如可以使用交叉熵损失函数。
🖼️ 关键图片
📊 实验亮点
实验结果表明,FedMME在四个医学图像数据集上均取得了优于现有单次联邦学习方法的结果。例如,在RSNA数据集上,当使用Dirichlet分布(α = 0.3)模拟非独立同分布数据时,FedMME的准确率比现有方法提高了超过17.5%。这表明FedMME在实际医疗场景中具有显著的优势。
🎯 应用场景
FedMME框架可应用于多种医学图像分析任务,例如疾病诊断、病灶检测和病情评估。该框架能够在保护患者隐私的前提下,整合来自不同医疗机构的数据,提高诊断的准确性和效率。未来,该研究可以扩展到其他医学领域,例如基因组学和蛋白质组学,实现更全面的多模态数据分析。
📄 摘要(原文)
Federated learning (FL) has attracted considerable interest in the medical domain due to its capacity to facilitate collaborative model training while maintaining data privacy. However, conventional FL methods typically necessitate multiple communication rounds, leading to significant communication overhead and delays, especially in environments with limited bandwidth. One-shot federated learning addresses these issues by conducting model training and aggregation in a single communication round, thereby reducing communication costs while preserving privacy. Among these, one-shot federated ensemble learning combines independently trained client models using ensemble techniques such as voting, further boosting performance in non-IID data scenarios. On the other hand, existing machine learning methods in healthcare predominantly use unimodal data (e.g., medical images or textual reports), which restricts their diagnostic accuracy and comprehensiveness. Therefore, the integration of multi-modal data is proposed to address these shortcomings. In this paper, we introduce FedMME, an innovative one-shot multi-modal federated ensemble learning framework that utilizes multi-modal data for medical image analysis. Specifically, FedMME capitalizes on vision large language models to produce textual reports from medical images, employs a BERT model to extract textual features from these reports, and amalgamates these features with visual features to improve diagnostic accuracy. Experimental results show that our method demonstrated superior performance compared to existing one-shot federated learning methods in healthcare scenarios across four datasets with various data distributions. For instance, it surpasses existing one-shot federated learning approaches by more than 17.5% in accuracy on the RSNA dataset when applying a Dirichlet distribution with ($α$ = 0.3).