ChronoSense: Exploring Temporal Understanding in Large Language Models with Time Intervals of Events
作者: Duygu Sezen Islakoglu, Jan-Christoph Kalo
分类: cs.LG, cs.CL
发布日期: 2025-01-06 (更新: 2025-07-21)
备注: Accepted to ACL 2025. Results on a larger test set. 13 pages, 2 figures
🔗 代码/项目: GITHUB
💡 一句话要点
ChronoSense:构建时序理解基准,评估大语言模型对事件时间间隔的理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 时序理解 时间间隔关系 Allen关系 基准数据集
📋 核心要点
- 现有大语言模型在时序推理方面存在不足,尤其是在理解Allen时间间隔关系等基本概念上。
- ChronoSense基准旨在通过16个任务,系统评估LLM对事件时间间隔关系的识别和时间算术能力。
- 实验结果表明,现有LLM在处理不同类型的Allen关系时表现差异显著,可能依赖记忆而非推理。
📝 摘要(中文)
大语言模型(LLMs)在各种自然语言处理任务中取得了显著成功,但在推理和算术方面仍然面临重大挑战。时序推理是自然语言理解的关键组成部分,受到了越来越多的研究关注。然而,对Allen的时间间隔关系(例如,之前、之后、期间)——时序关系的一个基本框架——的全面测试仍未得到充分探索。为了填补这一空白,我们提出了ChronoSense,一个新的基准,用于评估LLMs的时序理解能力。它包括16个任务,侧重于识别两个时间事件之间的Allen关系和时间算术,使用来自Wikidata的抽象事件和真实世界数据。我们使用这个基准评估了七个最新的LLMs的性能,结果表明模型对Allen关系的处理方式各不相同,即使是对称关系也是如此。此外,研究结果表明,模型可能依赖于记忆来回答与时间相关的问题。总的来说,模型较低的性能突出了LLMs中改进时序理解的必要性,ChronoSense为该领域未来的研究提供了一个强大的框架。我们的数据集和源代码可在https://github.com/duyguislakoglu/chronosense获得。
🔬 方法详解
问题定义:论文旨在解决大语言模型在时序理解方面的不足,特别是对Allen时间间隔关系的理解。现有方法缺乏对LLM时序推理能力的全面评估,无法准确衡量模型对时间关系的掌握程度。此外,现有方法难以区分模型是真正理解了时间关系,还是仅仅依靠记忆来回答问题。
核心思路:论文的核心思路是构建一个专门用于评估LLM时序理解能力的基准数据集ChronoSense。该基准包含多种类型的任务,涵盖了Allen时间间隔关系和时间算术,旨在全面考察模型对时间关系的理解和推理能力。通过分析模型在不同任务上的表现,可以深入了解模型在时序理解方面的优势和不足。
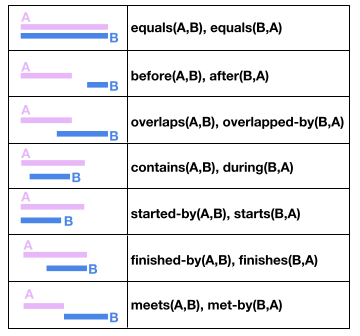
技术框架:ChronoSense基准包含16个任务,这些任务可以分为两类:识别两个时间事件之间的Allen关系和时间算术。任务数据来源于抽象事件和Wikidata的真实世界数据。研究人员使用该基准评估了七个最新的LLM,并分析了它们在不同任务上的表现。评估指标主要关注模型在识别Allen关系和进行时间算术时的准确率。
关键创新:该论文的关键创新在于构建了一个专门用于评估LLM时序理解能力的基准数据集ChronoSense。与现有方法相比,ChronoSense更加全面和系统地考察了模型对时间关系的理解和推理能力。此外,ChronoSense还包含了真实世界数据,可以更好地评估模型在实际应用中的表现。
关键设计:ChronoSense基准的关键设计包括:1) 任务的多样性,涵盖了所有13种Allen时间间隔关系和时间算术;2) 数据的多样性,包括抽象事件和真实世界数据;3) 评估指标的全面性,关注模型在识别Allen关系和进行时间算术时的准确率。具体参数设置和网络结构取决于被评估的LLM。
🖼️ 关键图片

📊 实验亮点
实验结果表明,现有LLM在ChronoSense基准上的表现不佳,突出了模型在时序理解方面的不足。不同模型对Allen关系的处理方式差异显著,即使是对称关系也是如此。研究还发现,模型可能依赖于记忆来回答与时间相关的问题,而非进行真正的推理。这些发现表明,需要进一步研究和改进LLM的时序理解能力。
🎯 应用场景
该研究成果可应用于提升大语言模型在需要时序推理的自然语言处理任务中的性能,例如事件预测、故事理解、医疗诊断等。通过使用ChronoSense基准,可以更好地评估和改进LLM的时序理解能力,从而提高其在实际应用中的可靠性和准确性。未来,该基准可以扩展到更复杂的时序推理场景,例如多事件链推理和时间不确定性处理。
📄 摘要(原文)
Large Language Models (LLMs) have achieved remarkable success in various NLP tasks, yet they still face significant challenges in reasoning and arithmetic. Temporal reasoning, a critical component of natural language understanding, has raised increasing research attention. However, comprehensive testing of Allen's interval relations (e.g., before, after, during) -- a fundamental framework for temporal relationships -- remains underexplored. To fill this gap, we present ChronoSense, a new benchmark for evaluating LLMs' temporal understanding. It includes 16 tasks, focusing on identifying the Allen relation between two temporal events and temporal arithmetic, using both abstract events and real-world data from Wikidata. We assess the performance of seven recent LLMs using this benchmark and the results indicate that models handle Allen relations, even symmetrical ones, quite differently. Moreover, the findings suggest that the models may rely on memorization to answer time-related questions. Overall, the models' low performance highlights the need for improved temporal understanding in LLMs and ChronoSense offers a robust framework for future research in this area. Our dataset and the source code are available at https://github.com/duyguislakoglu/chronosense.