Seeing the Whole in the Parts in Self-Supervised Representation Learning
作者: Arthur Aubret, Céline Teulière, Jochen Triesch
分类: cs.LG, cs.CV
发布日期: 2025-01-06
备注: 20 pages
💡 一句话要点
CO-SSL通过对齐局部与全局表征,提升自监督学习的性能和鲁棒性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 自监督学习 对比学习 局部全局对齐 图像表征 鲁棒性
📋 核心要点
- 现有的自监督学习方法主要通过掩码图像部分区域或激进裁剪图像来建模视觉特征的空间共现关系,存在一定的局限性。
- CO-SSL的核心思想是对齐图像的局部表征(在池化之前)和全局表征,从而学习更有效的视觉特征。
- 实验结果表明,CO-SSL在多个数据集上优于现有方法,并在ImageNet-1K上取得了显著的性能提升,同时展现出更强的鲁棒性。
📝 摘要(中文)
本文提出了一种新的建模空间共现关系的方法,用于自监督学习(SSL)。该方法通过对齐局部表征(池化前)与全局图像表征来学习视觉特征。作者提出了一系列实例判别方法,统称为CO-SSL,并在多个数据集上验证了其有效性,包括ImageNet-1K,在100个预训练epoch后达到了71.5%的Top-1准确率。此外,CO-SSL对噪声破坏、内部破坏、小型对抗攻击和大型训练裁剪尺寸具有更强的鲁棒性。分析表明,CO-SSL学习了高度冗余的局部表征,这解释了其鲁棒性。总而言之,这项工作表明,对齐局部和全局表征可能是无监督类别学习的一个强大原则。
🔬 方法详解
问题定义:现有的自监督学习方法,如基于掩码图像建模和对比学习的方法,在学习图像表征时,可能无法充分捕捉局部特征与全局上下文之间的关系。这些方法对噪声和对抗攻击的鲁棒性也存在不足。因此,需要一种更有效的方法来建模图像的空间共现关系,提高自监督学习的性能和鲁棒性。
核心思路:CO-SSL的核心思路是通过对齐图像的局部表征和全局表征,来学习更具判别性和鲁棒性的视觉特征。这种方法能够让模型同时关注图像的局部细节和全局结构,从而更好地理解图像的内容。对齐局部和全局表征可以促使模型学习到更丰富的特征表达,从而提升模型的泛化能力。
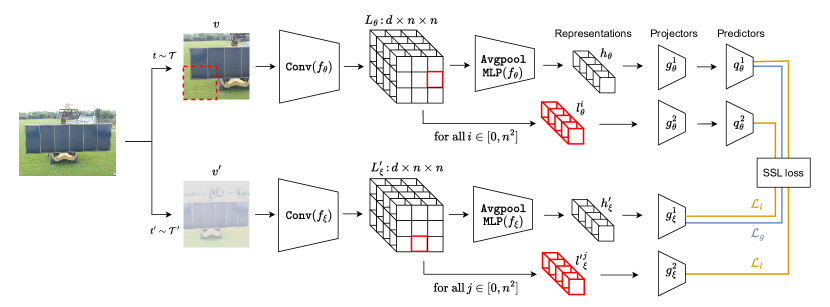
技术框架:CO-SSL的技术框架主要包含以下几个步骤:首先,对输入图像进行预处理,例如随机裁剪和颜色抖动。然后,使用一个卷积神经网络提取图像的局部特征。接下来,对局部特征进行全局平均池化,得到全局图像表征。同时,保留未经池化的局部特征。最后,使用对比学习的目标函数,对齐局部特征和全局表征。
关键创新:CO-SSL最重要的技术创新点在于其对齐局部表征和全局表征的思想。与以往只关注局部或全局特征的方法不同,CO-SSL同时考虑了图像的局部细节和全局结构,从而学习到更有效的视觉特征。此外,CO-SSL还通过学习高度冗余的局部表征,提高了模型的鲁棒性。
关键设计:CO-SSL的关键设计包括:1) 使用ResNet等卷积神经网络作为特征提取器;2) 使用InfoNCE损失函数作为对比学习的目标函数,鼓励局部特征与对应的全局表征对齐,同时排斥与其他图像的全局表征对齐;3) 通过实验选择合适的局部特征提取层,以平衡局部细节和全局上下文;4) 使用较大的训练裁剪尺寸,以提高模型的鲁棒性。
🖼️ 关键图片

📊 实验亮点
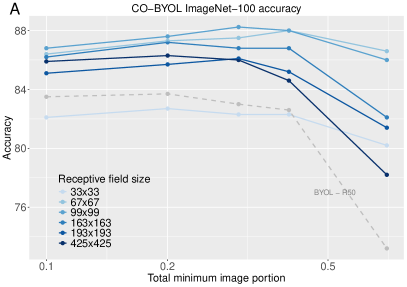
CO-SSL在ImageNet-1K数据集上取得了显著的性能提升,在100个预训练epoch后达到了71.5%的Top-1准确率,优于之前的自监督学习方法。此外,CO-SSL对噪声破坏、内部破坏、小型对抗攻击和大型训练裁剪尺寸表现出更强的鲁棒性。实验结果表明,CO-SSL能够学习到更具判别性和鲁棒性的视觉特征。
🎯 应用场景
CO-SSL具有广泛的应用前景,可以应用于图像分类、目标检测、图像分割等计算机视觉任务。其学习到的鲁棒性表征使其在噪声环境、对抗攻击等场景下具有优势。该方法还可以应用于医学图像分析、遥感图像处理等领域,为这些领域提供更有效的特征提取方法。
📄 摘要(原文)
Recent successes in self-supervised learning (SSL) model spatial co-occurrences of visual features either by masking portions of an image or by aggressively cropping it. Here, we propose a new way to model spatial co-occurrences by aligning local representations (before pooling) with a global image representation. We present CO-SSL, a family of instance discrimination methods and show that it outperforms previous methods on several datasets, including ImageNet-1K where it achieves 71.5% of Top-1 accuracy with 100 pre-training epochs. CO-SSL is also more robust to noise corruption, internal corruption, small adversarial attacks, and large training crop sizes. Our analysis further indicates that CO-SSL learns highly redundant local representations, which offers an explanation for its robustness. Overall, our work suggests that aligning local and global representations may be a powerful principle of unsupervised category learning.