Randomly Sampled Language Reasoning Problems Elucidate Limitations of In-Context Learning
作者: Kavi Gupta, Kate Sanders, Armando Solar-Lezama
分类: cs.LG
发布日期: 2025-01-06 (更新: 2025-09-10)
备注: 10 pages, 4 figures, 2 tables
💡 一句话要点
通过随机语言推理问题揭示了上下文学习的局限性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 上下文学习 新颖性 泛化能力 语言推理 n-gram模型 随机语言
📋 核心要点
- 大型语言模型在处理新颖性问题时表现不佳,现有研究主要集中在复杂任务的扰动上。
- 论文通过随机生成的简单语言任务,隔离了新颖性对上下文学习的影响,从而评估LLM的泛化能力。
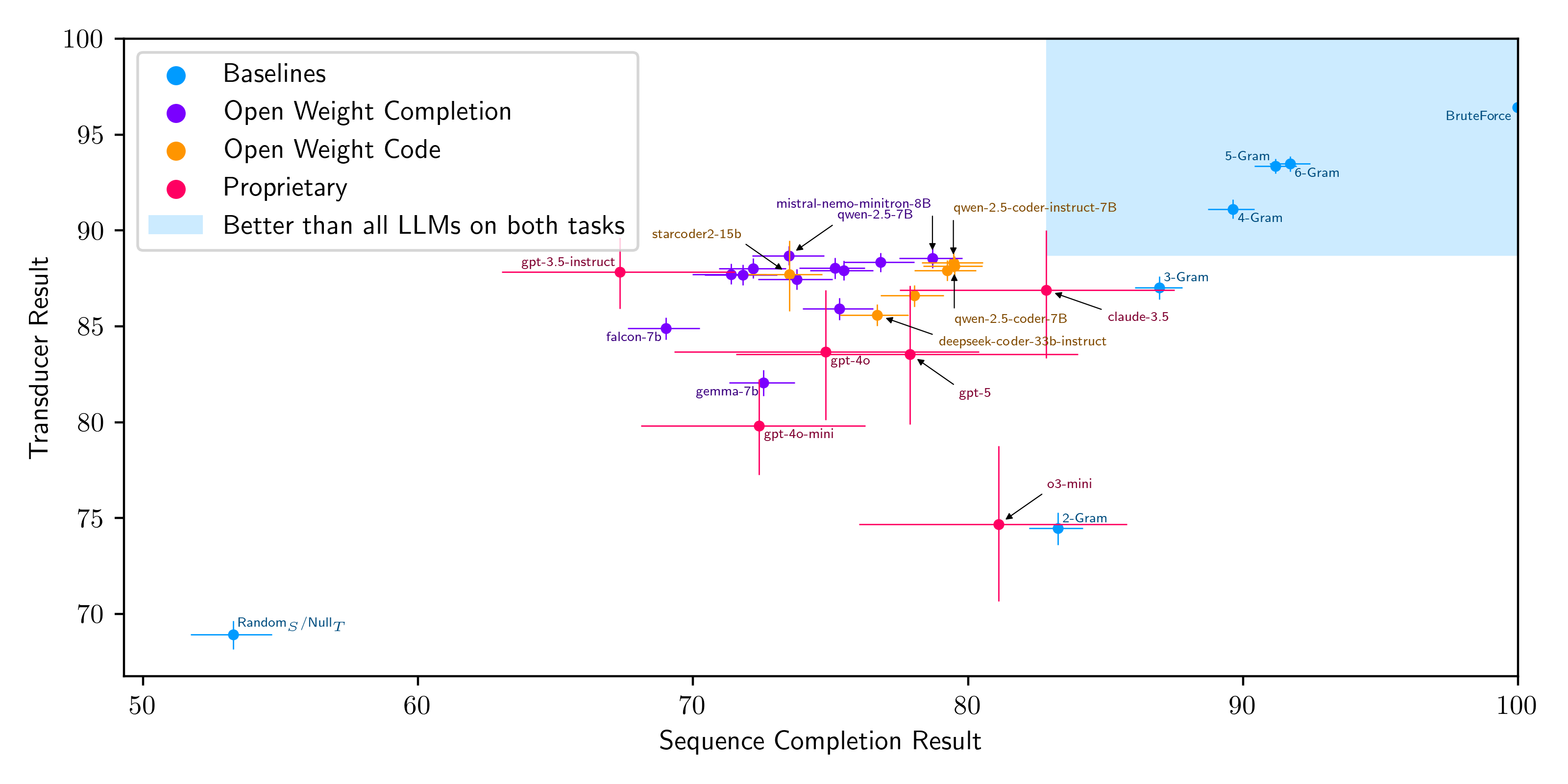
- 实验表明,在这些随机语言任务上,LLM的性能不如n-gram模型,揭示了上下文学习的局限性。
📝 摘要(中文)
大型语言模型(LLMs)因其在广泛问题上的卓越性能而彻底改变了机器学习领域,但它们也容易产生幻觉般的错误答案,并且在同一任务的非典型版本上表现不佳。关于LLM性能有几种新兴理论,包括LLM缺乏世界建模能力,对自回归先验存在不良偏差,以及难以处理更具新颖性的问题。现有关于LLM输入新颖性的文献主要集中在相对复杂的任务上,研究典型但复杂问题的扰动。本文试图最小化复杂性,以隔离新颖性作为LLM表现不佳的一个因素,并研究上下文学习的能力。为此,我们考虑一个极其简单的领域:简单语言任务上的下一个token预测。特别之处在于,这些语言任务是完全未知的,因为它们是从由简单语法规则产生的大量、简约定义的语言集中随机抽取的。这种实验设置允许我们独立于模型的参数知识来评估ICL。我们发现,在这种任务上,LLM的性能一致低于n-gram模型,无论是在用作下一个token预测器还是在思维链中。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLMs)在面对完全新颖的、简单的语言任务时的表现。现有方法通常评估LLM在常见任务上的性能,忽略了模型在新颖性方面的泛化能力。现有研究主要集中在复杂任务的扰动上,难以有效隔离新颖性这一因素的影响。
核心思路:论文的核心思路是通过随机生成简单的语言任务,创建一个可控的新颖性环境。这些语言任务基于简单的语法规则,并且对于LLM来说是完全未知的。通过在这种环境下评估LLM的性能,可以更清晰地了解上下文学习(ICL)在处理新颖性问题时的局限性。
技术框架:论文采用的实验框架包括以下几个主要步骤:1) 定义一组简单的语法规则,用于生成随机语言;2) 从这些随机语言中抽取样本,构建语言任务;3) 使用LLM进行下一个token预测,并评估其性能;4) 将LLM的性能与n-gram模型进行比较,作为基线。实验中使用了两种LLM使用方式:直接作为下一个token预测器和在思维链(Chain-of-Thought)模式下使用。
关键创新:论文的关键创新在于其实验设置,即使用随机生成的简单语言任务来评估LLM的上下文学习能力。这种方法能够有效地隔离新颖性这一因素,并避免了模型参数知识的干扰。通过这种方式,论文能够更清晰地揭示LLM在处理新颖性问题时的局限性。
关键设计:论文的关键设计包括:1) 语法规则的设计,需要足够简单以确保任务的易于理解,同时又足够多样化以产生大量不同的语言;2) 评估指标的选择,需要能够准确反映LLM的预测性能;3) 基线的选择,n-gram模型作为一种简单的统计语言模型,可以作为评估LLM性能的有效基线。具体的参数设置和网络结构信息未知。
🖼️ 关键图片
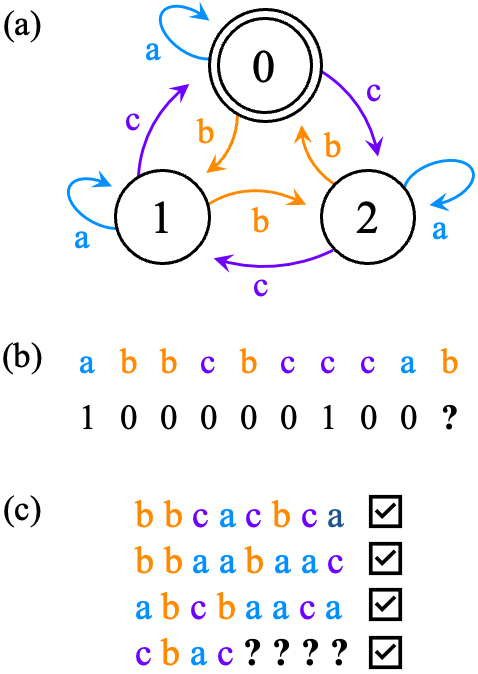
📊 实验亮点
实验结果表明,在随机生成的简单语言任务上,LLM的性能一致低于n-gram模型。这一结果表明,即使在非常简单的任务上,LLM在处理完全新颖的语言时也存在显著的局限性。无论LLM是直接用作下一个token预测器,还是在思维链模式下使用,其性能均不如n-gram模型。
🎯 应用场景
该研究有助于更好地理解大型语言模型的局限性,并指导未来模型的设计和训练。其潜在应用领域包括:提升LLM在处理新领域、新任务时的泛化能力;开发更鲁棒的上下文学习方法;以及设计更有效的模型评估指标,从而推动人工智能技术的进步。
📄 摘要(原文)
While LLMs have revolutionized the field of machine learning due to their high performance on a strikingly wide range of problems, they are also known to hallucinate false answers and underperform on less canonical versions of the same tasks. There are several emerging theories of LLM performance, among them that LLMs lack world modeling ability, that they have an undesirable bias towards an autoregressive prior, and that they struggle on more novel problems. The existing literature on LLM input novelty has focused on tasks of relatively high complexity, studying perturbations of canonical but complex problems. In this paper, we attempt to minimize complexity in order to isolate novelty as a factor in LLM underperformance and investigate the power of in-context-learning. To this end, we consider an extremely simple domain: next token prediction on simple language tasks. The twist is that these language tasks are wholly unseen, as they are randomly drawn from a large, parsimoniously defined set of languages arising from simple grammar rules. This experimental setup allows us to evaluate ICL independently of models' parametric knowledge. We find that LLMs uniformly underperform n-gram models on this task, both when used as next token predictors and in chain-of-thought.