Representation Learning of Lab Values via Masked AutoEncoders
作者: David Restrepo, Chenwei Wu, Yueran Jia, Jaden K. Sun, Jack Gallifant, Catherine G. Bielick, Yugang Jia, Leo A. Celi
分类: cs.LG, cs.AI
发布日期: 2025-01-05 (更新: 2025-06-26)
备注: 14 pages of main text, 11 appendix
💡 一句话要点
提出Lab-MAE,利用掩码自编码器进行电子病历中缺失实验室值的表征学习与补全。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 电子病历 缺失值补全 掩码自编码器 Transformer 自监督学习
📋 核心要点
- 现有方法难以捕捉电子病历中实验室值的复杂时序依赖,导致补全精度不足,尤其在弱势群体中表现更差。
- Lab-MAE利用Transformer架构的掩码自编码器,通过联合建模实验室值和时间戳,显式学习时序关系。
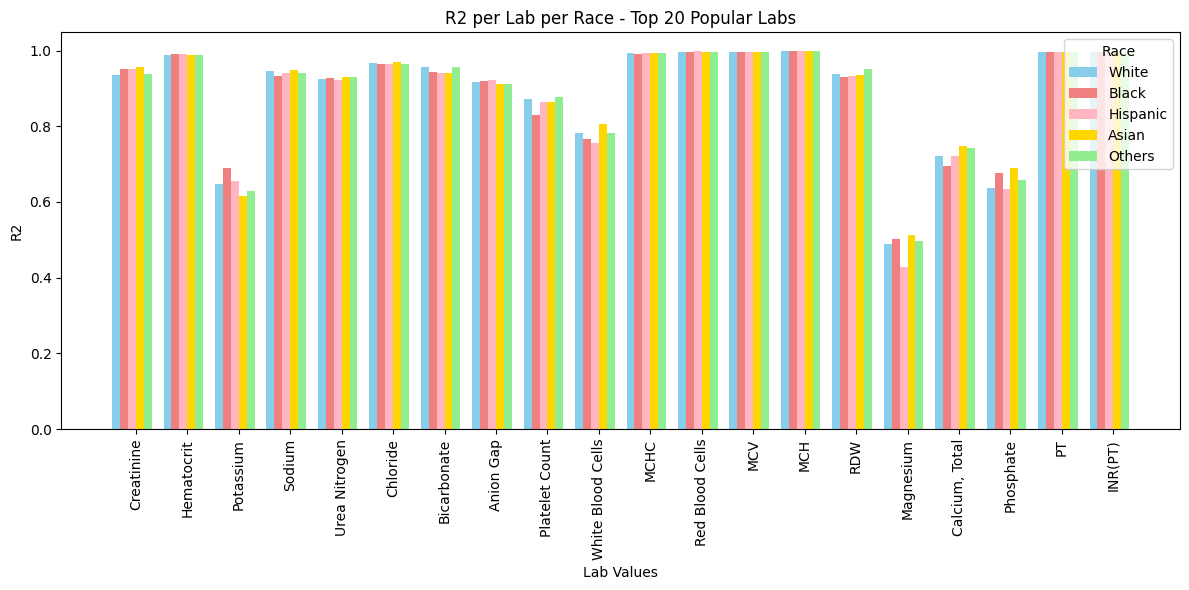
- 实验表明,Lab-MAE在MIMIC-IV数据集上显著优于现有方法,并在不同人群中实现了更公平的补全性能。
📝 摘要(中文)
电子病历(EHRs)中缺失实验室值的准确补全是实现稳健的临床预测和减少医疗保健AI系统偏差的关键。现有的XGBoost、softimpute、GAIN、EM和MICE等方法难以建模EHR数据中复杂的时序和上下文依赖关系,尤其是在代表性不足的群体中。本文提出了Lab-MAE,一种基于Transformer的掩码自编码器框架,利用自监督学习来补全连续的时序实验室值。Lab-MAE引入了一种结构化的编码方案,联合建模实验室测试值及其对应的时间戳,从而显式地捕获时间依赖性。在MIMIC-IV数据集上的实验结果表明,Lab-MAE在均方根误差(RMSE)、R方(R2)和Wasserstein距离(WD)等多项指标上显著优于XGBoost、softimpute、GAIN、EM和MICE等最先进的基线方法。值得注意的是,Lab-MAE在不同患者人群中实现了公平的性能,提高了临床预测的公平性。我们进一步研究了后续实验室值作为潜在捷径特征的作用,揭示了Lab-MAE在缺乏此类数据情况下的鲁棒性。研究结果表明,我们针对EHR数据特征改进的Transformer架构,为更准确和公平的临床补全提供了一个基础模型。此外,我们测量并比较了Lab-MAE与XGBoost模型的碳足迹,突出了其环境要求。
🔬 方法详解
问题定义:论文旨在解决电子病历中缺失实验室值的准确补全问题。现有方法,如XGBoost、softImpute、GAIN等,无法有效建模EHR数据中复杂的时序和上下文依赖关系,导致补全精度不高,并且可能在不同人群中存在偏差。
核心思路:论文的核心思路是利用Transformer架构的强大表征学习能力,通过掩码自编码器(MAE)进行自监督学习,从而学习到实验室值的时序依赖关系。通过联合建模实验室值和对应的时间戳,显式地捕获时间信息,提高补全的准确性和公平性。
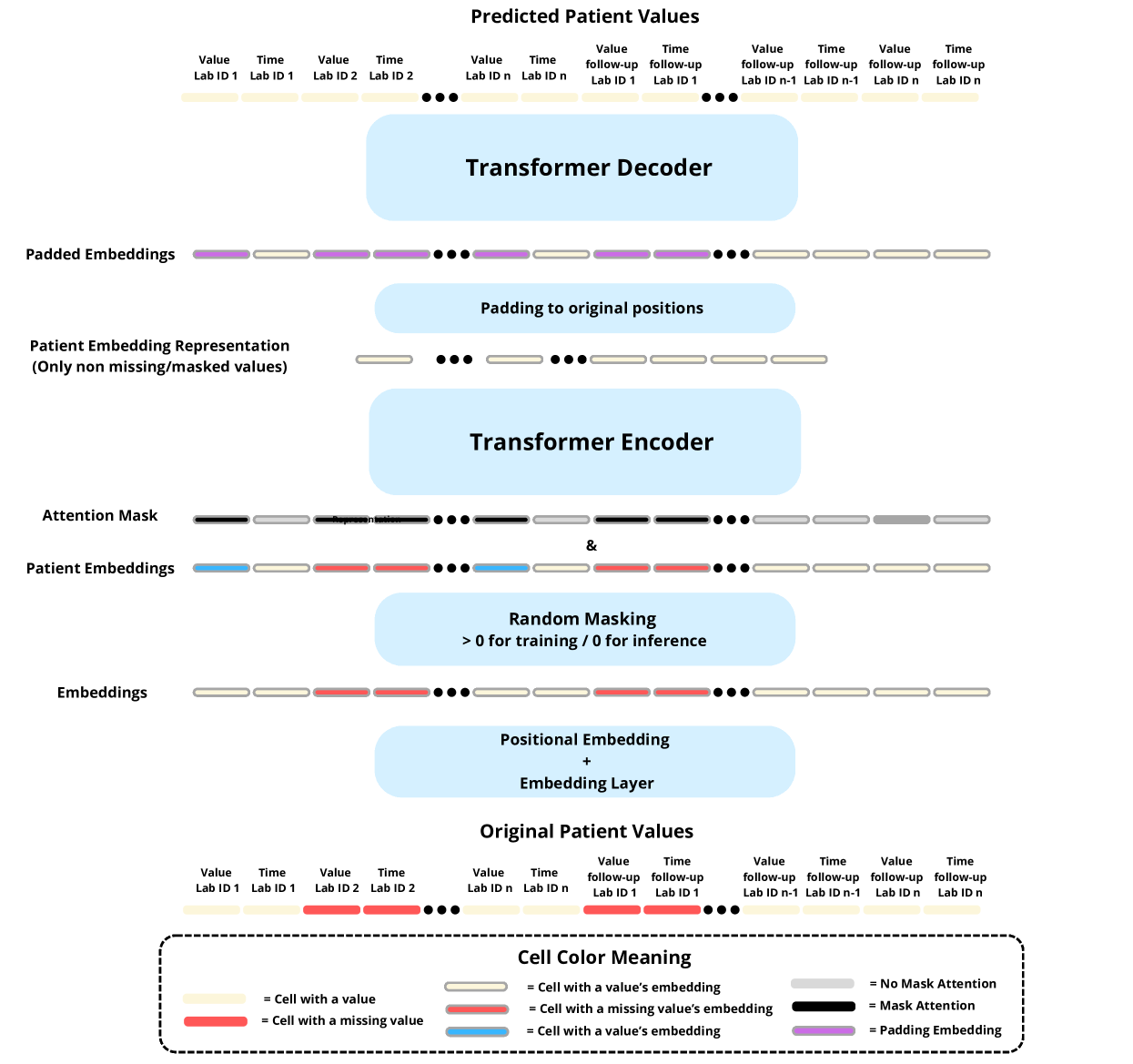
技术框架:Lab-MAE的整体框架是一个基于Transformer的掩码自编码器。首先,输入的实验室值序列和对应的时间戳经过一个结构化的编码层,将它们嵌入到同一向量空间。然后,随机mask掉一部分实验室值,将剩余的可见部分输入到Transformer编码器中进行特征提取。编码器的输出再经过一个Transformer解码器,用于预测被mask掉的实验室值。
关键创新:Lab-MAE的关键创新在于其结构化的编码方案和对Transformer架构的适配。结构化编码方案能够联合建模实验室值和时间戳,从而显式地捕获时间依赖性。此外,论文还针对EHR数据的特点,对Transformer架构进行了调整,使其更适合处理不规则的时序数据。与现有方法相比,Lab-MAE能够更好地捕捉EHR数据中的复杂关系,从而提高补全的准确性和公平性。
关键设计:Lab-MAE的关键设计包括:1) 结构化的嵌入层,用于联合编码实验室值和时间戳;2) Transformer编码器和解码器的层数和隐藏层大小;3) 掩码比例,即mask掉的实验室值的比例;4) 损失函数,采用均方误差(MSE)作为重建损失。具体参数设置在论文中有详细描述,例如Transformer的层数、隐藏层大小、注意力头数等。
🖼️ 关键图片
📊 实验亮点
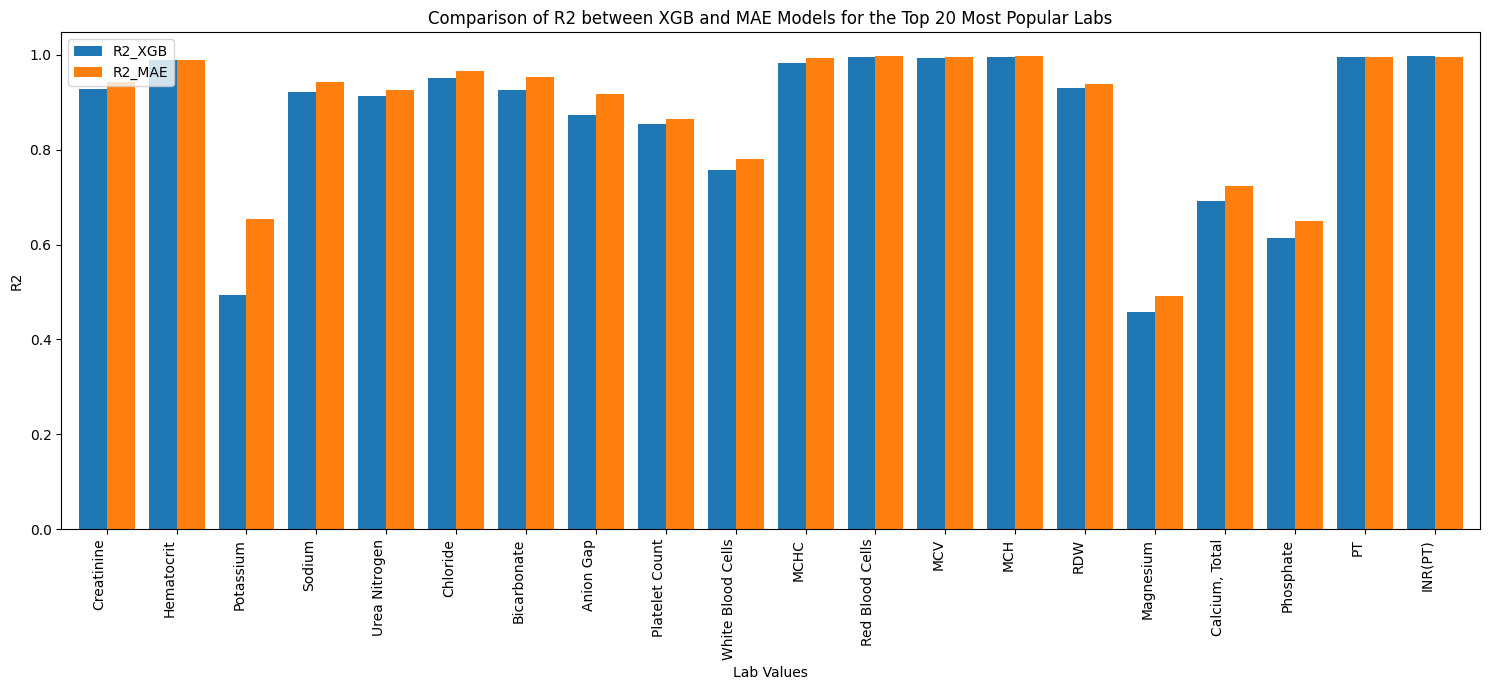
Lab-MAE在MIMIC-IV数据集上取得了显著的性能提升,在RMSE、R2和Wasserstein距离等指标上均优于XGBoost、softImpute、GAIN、EM和MICE等基线方法。尤其值得一提的是,Lab-MAE在不同人群中实现了更公平的性能,表明其具有良好的泛化能力和鲁棒性。此外,论文还分析了后续实验室值作为shortcut features的影响,证明了Lab-MAE在缺乏此类数据时的有效性。
🎯 应用场景
Lab-MAE可应用于多种临床场景,例如:提高临床预测模型的准确性,减少由于数据缺失导致的偏差;辅助医生进行诊断和治疗决策,尤其是在数据不完整的患者中;构建更公平的医疗AI系统,减少不同人群之间的差异。该研究为构建更准确和公平的临床预测模型奠定了基础。
📄 摘要(原文)
Accurate imputation of missing laboratory values in electronic health records (EHRs) is critical to enable robust clinical predictions and reduce biases in AI systems in healthcare. Existing methods, such as XGBoost, softimpute, GAIN, Expectation Maximization (EM), and MICE, struggle to model the complex temporal and contextual dependencies in EHR data, particularly in underrepresented groups. In this work, we propose Lab-MAE, a novel transformer-based masked autoencoder framework that leverages self-supervised learning for the imputation of continuous sequential lab values. Lab-MAE introduces a structured encoding scheme that jointly models laboratory test values and their corresponding timestamps, enabling explicit capturing temporal dependencies. Empirical evaluation on the MIMIC-IV dataset demonstrates that Lab-MAE significantly outperforms state-of-the-art baselines such as XGBoost, softimpute, GAIN, EM, and MICE across multiple metrics, including root mean square error (RMSE), R-squared (R2), and Wasserstein distance (WD). Notably, Lab-MAE achieves equitable performance across demographic groups of patients, advancing fairness in clinical predictions. We further investigate the role of follow-up laboratory values as potential shortcut features, revealing Lab-MAE's robustness in scenarios where such data is unavailable. The findings suggest that our transformer-based architecture, adapted to the characteristics of EHR data, offers a foundation model for more accurate and fair clinical imputation. In addition, we measure and compare the carbon footprint of Lab-MAE with the a XGBoost model, highlighting its environmental requirements.