HALO: Hadamard-Assisted Lower-Precision Optimization for LLMs
作者: Saleh Ashkboos, Mahdi Nikdan, Soroush Tabesh, Roberto L. Castro, Torsten Hoefler, Dan Alistarh
分类: cs.LG
发布日期: 2025-01-05 (更新: 2025-11-05)
备注: 19 pages, 6 figures
🔗 代码/项目: GITHUB
💡 一句话要点
HALO:面向LLM的Hadamard辅助低精度优化,实现高效量化微调
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 量化训练 低精度优化 Hadamard变换 模型微调
📋 核心要点
- 大型语言模型(LLM)的量化训练面临精度损失的挑战,尤其是在微调预训练模型时,权重和激活中存在的异常值会加剧这一问题。
- HALO通过在前向和后向传播中引入Hadamard旋转来缓解异常值,并结合高性能内核和FSDP集成,实现了高效的低精度训练。
- 实验表明,HALO在LLAMA系列模型上实现了接近全精度的微调效果,并在RTX 4090 GPU上实现了高达1.41倍的加速。
📝 摘要(中文)
本文提出了一种名为HALO的Transformer量化感知训练方法,旨在实现准确高效的低精度LLM训练。HALO通过以下方式解决低精度优化难题:1) 在前向和后向传播中策略性地放置Hadamard旋转,以减轻异常值的影响;2) 提供高性能内核支持;3) 集成FSDP以实现低精度通信。该方法确保前向和后向传播期间所有大型矩阵乘法均以较低精度执行。在LLAMA系列模型上的应用表明,HALO在各种任务的微调中实现了接近全精度等效的结果,并在RTX 4090 GPU上进行完整微调时,提供了高达1.41倍的端到端加速。HALO有效地支持标准和参数高效微调(PEFT)。实验结果表明,HALO是第一个实用的全量化LLM微调方法,可在保持8位精度的情况下提供性能优势。代码已开源。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在低精度下进行量化训练时,精度难以维持的问题。现有的量化方法在微调预训练模型时,由于权重和激活中存在较大的异常值,导致精度显著下降,限制了低精度训练的实际应用。
核心思路:HALO的核心思路是通过引入Hadamard变换来降低权重和激活中的异常值,从而使得模型能够在低精度下进行训练,同时保持较高的精度。Hadamard变换具有良好的能量集中特性,可以将数据分散到各个维度,从而降低异常值的影响。
技术框架:HALO的技术框架主要包括三个部分:Hadamard旋转的策略性放置、高性能内核支持和FSDP集成。Hadamard旋转被放置在前向和后向传播的关键位置,以减轻异常值的影响。高性能内核用于加速低精度计算。FSDP(Fully Sharded Data Parallel)集成用于实现低精度通信,从而提高训练效率。
关键创新:HALO的关键创新在于将Hadamard变换引入到LLM的量化训练中,并结合高性能内核和FSDP集成,实现了在低精度下进行高效且准确的微调。与现有方法相比,HALO能够更好地处理异常值,从而在保持精度的同时,提高训练速度。
关键设计:HALO的关键设计包括:1) Hadamard旋转的位置选择,需要根据模型的结构和数据的分布进行调整;2) 低精度数据类型选择,例如INT8或FP8;3) 高性能内核的优化,以充分利用硬件资源;4) FSDP的配置,以实现高效的通信。
🖼️ 关键图片
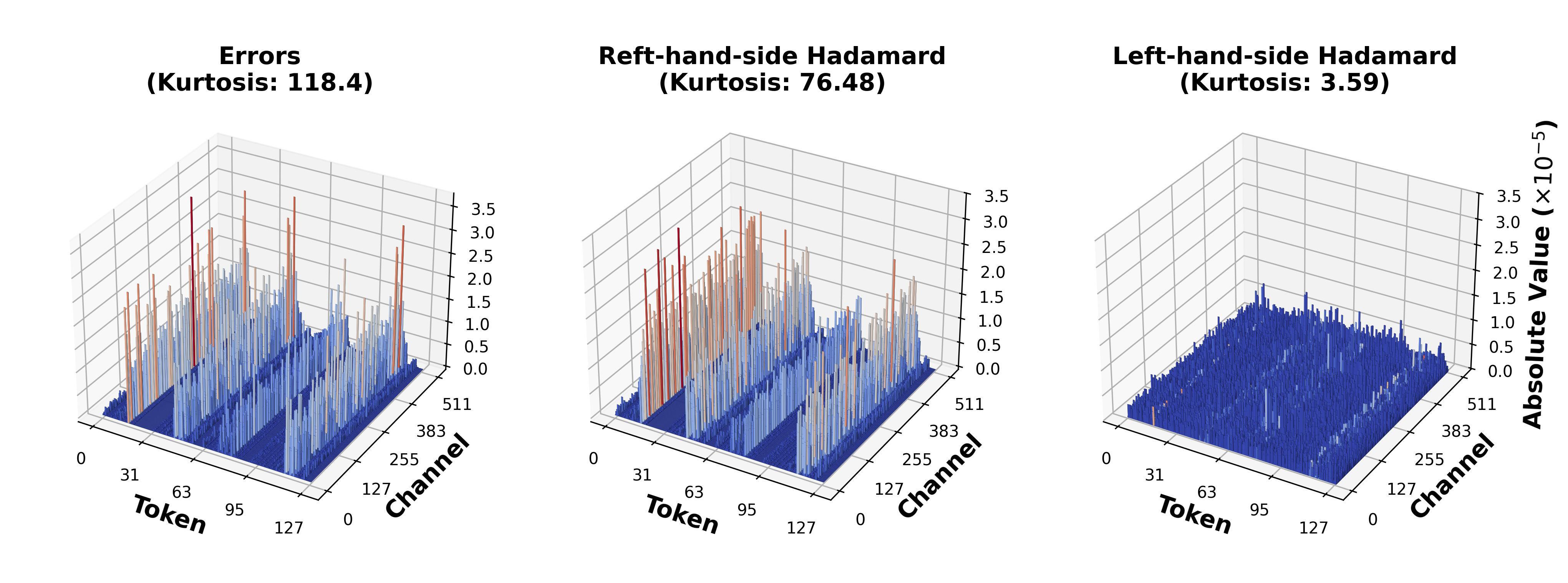
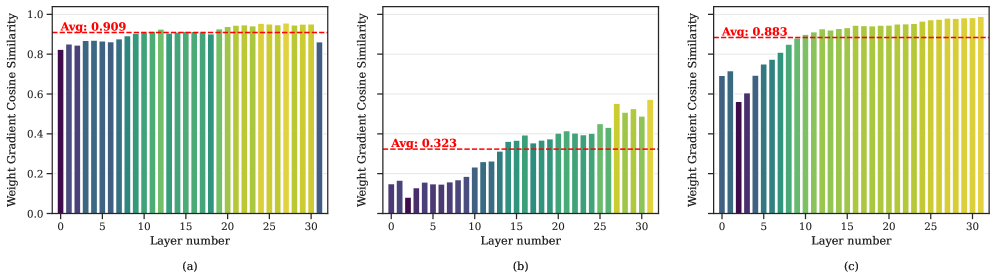
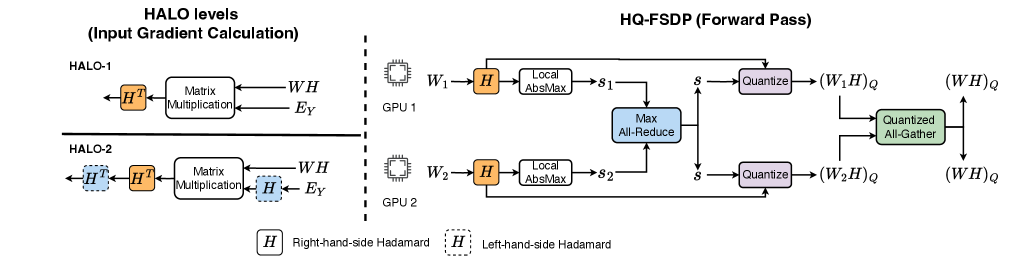
📊 实验亮点
HALO在LLAMA系列模型上进行了实验,结果表明,在各种微调任务中,HALO能够达到接近全精度的性能。在RTX 4090 GPU上进行完整微调时,HALO实现了高达1.41倍的端到端加速。这些结果表明,HALO是第一个实用的全量化LLM微调方法,能够在保持精度的同时,显著提高训练效率。
🎯 应用场景
HALO的潜在应用领域包括自然语言处理、机器翻译、文本生成等。该研究的实际价值在于降低了LLM的训练和部署成本,使得更多研究者和开发者能够使用和改进LLM。未来,HALO可以进一步推广到其他类型的深度学习模型,并与其他优化技术相结合,以实现更高的性能。
📄 摘要(原文)
Quantized training of Large Language Models (LLMs) remains an open challenge, as maintaining accuracy while performing all matrix multiplications in low precision has proven difficult. This is particularly the case when fine-tuning pre-trained models, which can have large weight and activation outlier values that make lower-precision optimization difficult. To address this, we present HALO, a novel quantization-aware training approach for Transformers that enables accurate and efficient low-precision training by combining 1) strategic placement of Hadamard rotations in both forward and backward passes, which mitigate outliers, 2) high-performance kernel support, and 3) FSDP integration for low-precision communication. Our approach ensures that all large matrix multiplications during the forward and backward passes are executed in lower precision. Applied to LLAMA-family models, HALO achieves near-full-precision-equivalent results during fine-tuning on various tasks, while delivering up to 1.41x end-to-end speedup for full fine-tuning on RTX 4090 GPUs. HALO efficiently supports both standard and parameterefficient fine-tuning (PEFT). Our results demonstrate the first practical approach to fully quantized LLM fine-tuning that maintains accuracy in 8-bit precision, while delivering performance benefits. Code is available at https://github.com/IST-DASLab/HALO.