Representation Convergence: Mutual Distillation is Secretly a Form of Regularization
作者: Zhengpeng Xie, Jiahang Cao, Changwei Wang, Fan Yang, Marco Hutter, Qiang Zhang, Jianxiong Zhang, Renjing Xu
分类: cs.LG, cs.AI
发布日期: 2025-01-05 (更新: 2025-09-24)
💡 一句话要点
互蒸馏作为正则化手段,提升强化学习策略对无关特征的鲁棒性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 互蒸馏 正则化 泛化性能 鲁棒性
📋 核心要点
- 强化学习策略容易过拟合训练数据中的无关特征,导致泛化性能下降。
- 通过互蒸馏,使策略互相学习,提升对无关特征的鲁棒性,从而提高泛化能力。
- 实验表明,互蒸馏能使策略自发学习到对像素输入的不变表示,验证了其有效性。
📝 摘要(中文)
本文提出,强化学习策略间的互蒸馏实际上是一种隐式的正则化方法,能够防止策略过度拟合无关特征。论文主要贡献包括:(i) 从理论上首次证明,增强策略对无关特征的鲁棒性能够提升泛化性能。(ii) 通过实验证明,策略间的互蒸馏有助于提升这种鲁棒性,从而使策略能够自发地学习到像素输入上的不变表示。论文的重点在于揭示泛化的潜在原理,并加深对泛化机制的理解,而非追求state-of-the-art的性能。
🔬 方法详解
问题定义:强化学习策略在复杂环境中训练时,容易受到无关特征的干扰,导致过拟合,泛化能力差。现有方法通常关注提升策略的性能,而忽略了对无关特征的鲁棒性,缺乏对泛化机制的深入理解。
核心思路:论文的核心思路是将互蒸馏视为一种正则化手段,通过让多个策略互相学习,互相约束,从而避免它们过度依赖于训练数据中的无关特征。这种相互学习的过程能够促使策略学习到更加本质和鲁棒的特征表示,从而提升泛化性能。
技术框架:论文采用互蒸馏框架,训练多个强化学习策略。每个策略都以其他策略的输出作为监督信号,进行学习。具体来说,每个策略的目标是模仿其他策略的行为,从而在学习过程中相互影响,共同提升对无关特征的鲁棒性。
关键创新:论文的关键创新在于将互蒸馏与正则化联系起来,并从理论上证明了提升策略对无关特征的鲁棒性能够改善泛化性能。此外,论文还通过实验验证了互蒸馏在提升鲁棒性和学习不变表示方面的有效性。
关键设计:论文的具体实现细节(如网络结构、损失函数等)未在摘要中详细说明,属于未知信息。但可以推测,损失函数的设计可能包含衡量策略间行为差异的项,以鼓励策略互相模仿。关键参数设置可能包括蒸馏的强度,以及参与蒸馏的策略数量。
🖼️ 关键图片
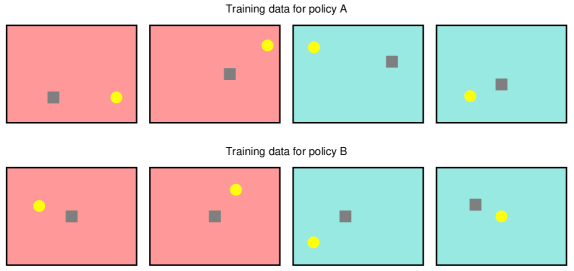
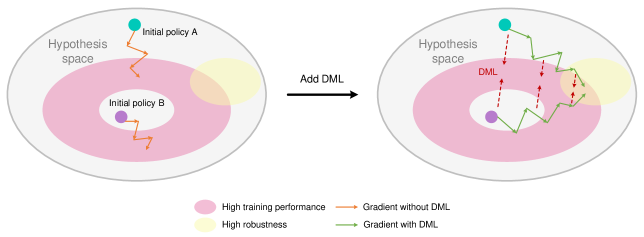
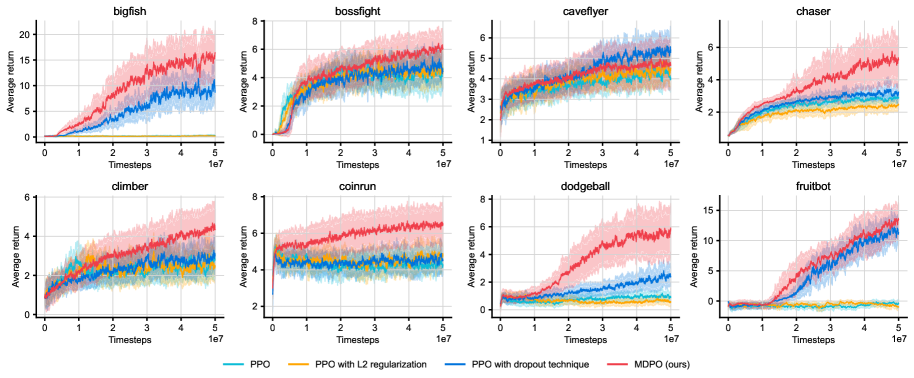
📊 实验亮点
论文通过实验证明,互蒸馏能够提升强化学习策略对无关特征的鲁棒性,并使其能够自发地学习到像素输入上的不变表示。虽然论文没有追求state-of-the-art的性能,但其对泛化机制的深入研究具有重要的理论价值。
🎯 应用场景
该研究成果可应用于各种强化学习任务中,尤其是在环境复杂、存在大量无关特征的场景下。例如,机器人导航、游戏AI等领域,通过互蒸馏提升策略的泛化能力,使其能够更好地适应真实世界的变化和干扰。该研究也为理解和提升强化学习的泛化性能提供了新的思路。
📄 摘要(原文)
In this paper, we argue that mutual distillation between reinforcement learning policies serves as an implicit regularization, preventing them from overfitting to irrelevant features. We highlight two separate contributions: (i) Theoretically, for the first time, we prove that enhancing the policy robustness to irrelevant features leads to improved generalization performance. (ii) Empirically, we demonstrate that mutual distillation between policies contributes to such robustness, enabling the spontaneous emergence of invariant representations over pixel inputs. Ultimately, we do not claim to achieve state-of-the-art performance but rather focus on uncovering the underlying principles of generalization and deepening our understanding of its mechanisms.