Efficient Deployment of Large Language Models on Resource-constrained Devices
作者: Zhiwei Yao, Yang Xu, Hongli Xu, Yunming Liao, Zuan Xie
分类: cs.LG, cs.AI, cs.CL, cs.DC
发布日期: 2025-01-05
💡 一句话要点
FedSpine:面向资源受限设备的LLM高效联邦部署框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 大型语言模型 参数高效微调 结构化剪枝 多臂老虎机 资源受限设备 模型部署
📋 核心要点
- 现有LLM微调方法在资源受限设备上部署时,存在推理延迟高、内存需求过大的问题,无法有效利用设备上的私有数据。
- FedSpine框架结合参数高效微调(PEFT)和结构化剪枝,通过迭代剪枝和调优LLM参数,实现高效部署。
- FedSpine采用在线多臂老虎机(MAB)算法,自适应地为异构设备确定剪枝率和LoRA秩,提升微调效率和最终精度。
📝 摘要(中文)
由于资源限制和异构数据分布,在资源受限设备上部署大型语言模型(LLM)面临巨大挑战。为了解决数据问题,需要使用设备上的私有数据对LLM进行微调,以适应各种下游任务。联邦学习(FL)提供了一种有前景的隐私保护解决方案,但现有的微调方法保留了原始LLM的大小,导致推理延迟高和内存需求过大的问题。因此,我们设计了FedSpine,一个FL框架,它结合了参数高效微调(PEFT)和结构化剪枝,以在资源受限设备上高效部署LLM。具体来说,FedSpine引入了一个迭代过程来剪枝和调整LLM的参数。为了减轻设备异构性的影响,采用在线多臂老虎机(MAB)算法来适应性地确定异构设备的不同剪枝率和LoRA秩,而无需事先了解其计算和通信能力。因此,FedSpine在保持较高推理精度的同时,提高了微调效率。在包含80个设备的物理平台上进行的实验结果表明,与其他基线相比,在相同稀疏度下,FedSpine可以将微调速度提高1.4倍-6.9倍,并将最终精度提高0.4%-4.5%。
🔬 方法详解
问题定义:论文旨在解决在资源受限设备上部署大型语言模型(LLM)时面临的挑战,特别是高推理延迟和过高的内存需求。现有的联邦学习微调方法通常保留原始LLM的大小,导致这些问题无法解决,并且忽略了设备异构性带来的影响。
核心思路:论文的核心思路是结合参数高效微调(PEFT)和结构化剪枝,设计一个名为FedSpine的联邦学习框架。通过迭代地剪枝和微调LLM的参数,在减小模型大小的同时,保持较高的推理精度。此外,利用在线多臂老虎机(MAB)算法来适应不同设备的计算和通信能力,从而解决设备异构性问题。
技术框架:FedSpine框架包含以下主要阶段:1) 初始化:在服务器端初始化LLM。2) 参数高效微调(PEFT):在客户端设备上,使用LoRA等PEFT技术对LLM进行微调,仅更新少量参数。3) 结构化剪枝:在客户端设备上,根据一定的策略对LLM进行结构化剪枝,减少模型大小。4) 多臂老虎机(MAB)优化:使用MAB算法为每个设备自适应地选择剪枝率和LoRA秩。5) 联邦聚合:服务器端收集客户端的更新,并进行聚合,更新全局模型。6) 迭代:重复PEFT、剪枝和MAB优化,直到模型收敛。
关键创新:FedSpine的关键创新在于:1) PEFT与结构化剪枝的结合:同时利用PEFT和剪枝来减小模型大小,提高推理效率。2) 在线多臂老虎机(MAB)优化:使用MAB算法自适应地为异构设备选择最佳的剪枝率和LoRA秩,无需事先了解设备的计算和通信能力。3) 迭代剪枝和微调:通过迭代地剪枝和微调,逐步优化模型,提高最终精度。
关键设计:1) 剪枝策略:采用结构化剪枝,例如剪枝整个attention head或layer,以避免不规则的稀疏性带来的性能下降。2) LoRA秩的选择:MAB算法根据设备的性能和数据分布,自适应地选择LoRA的秩,以平衡精度和效率。3) 奖励函数:MAB算法的奖励函数基于模型的精度和推理延迟,鼓励选择能够提供最佳精度和效率的剪枝率和LoRA秩。
🖼️ 关键图片
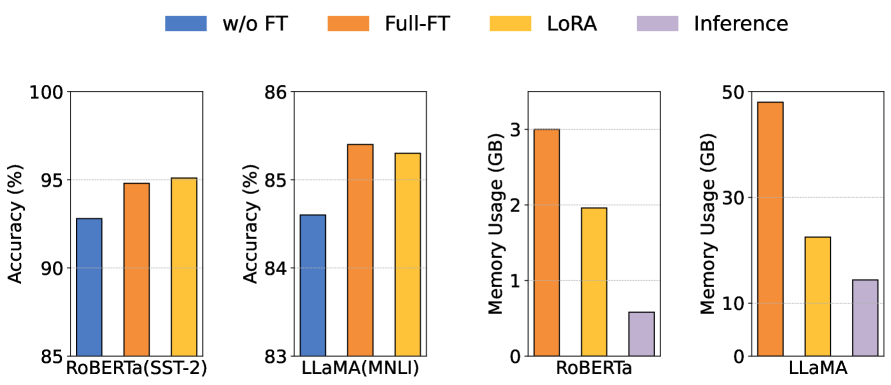
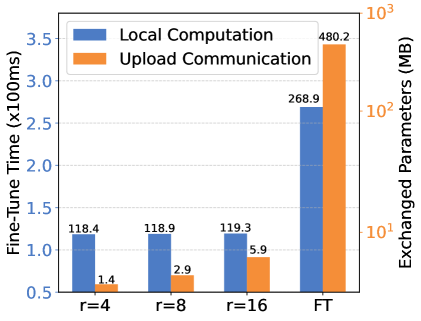
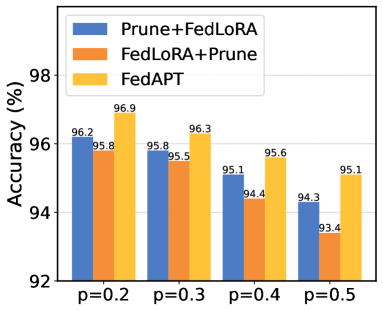
📊 实验亮点
实验结果表明,FedSpine在包含80个设备的物理平台上,与其他基线方法相比,在相同稀疏度下,可以将微调速度提高1.4倍-6.9倍,并将最终精度提高0.4%-4.5%。这些结果验证了FedSpine在资源受限设备上部署LLM的有效性。
🎯 应用场景
FedSpine框架可应用于各种资源受限设备上的LLM部署场景,例如移动设备、物联网设备和边缘服务器。该研究的实际价值在于降低了LLM的部署成本,使其能够在更广泛的设备上运行,从而促进LLM在各个领域的应用,例如智能助手、自然语言处理和机器翻译。未来,该框架可以进一步扩展到支持更多类型的设备和任务,并与其他优化技术相结合,以实现更高的效率和精度。
📄 摘要(原文)
Deploying Large Language Models (LLMs) on resource-constrained (or weak) devices presents significant challenges due to limited resources and heterogeneous data distribution. To address the data concern, it is necessary to fine-tune LLMs using on-device private data for various downstream tasks. While Federated Learning (FL) offers a promising privacy-preserving solution, existing fine-tuning methods retain the original LLM size, leaving issues of high inference latency and excessive memory demands unresolved. Hence, we design FedSpine, an FL framework that combines Parameter- Efficient Fine-Tuning (PEFT) with structured pruning for efficient deployment of LLMs on resource-constrained devices. Specifically, FedSpine introduces an iterative process to prune and tune the parameters of LLMs. To mitigate the impact of device heterogeneity, an online Multi-Armed Bandit (MAB) algorithm is employed to adaptively determine different pruning ratios and LoRA ranks for heterogeneous devices without any prior knowledge of their computing and communication capabilities. As a result, FedSpine maintains higher inference accuracy while improving fine-tuning efficiency. Experimental results conducted on a physical platform with 80 devices demonstrate that FedSpine can speed up fine-tuning by 1.4$\times$-6.9$\times$ and improve final accuracy by 0.4%-4.5% under the same sparsity level compared to other baselines.