Cognitive Edge Computing: A Comprehensive Survey on Optimizing Large Models and AI Agents for Pervasive Deployment
作者: Xubin Wang, Qing Li, Weijia Jia
分类: cs.LG, cs.AI
发布日期: 2025-01-04 (更新: 2025-11-07)
💡 一句话要点
综述认知边缘计算:优化大模型和AI Agent以实现普适部署
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 认知边缘计算 大语言模型 模型优化 边缘推理 云边协同
📋 核心要点
- 现有方法难以在资源受限的边缘设备上部署大型语言模型和AI Agent,同时保持推理能力。
- 论文提出了一个认知边缘计算框架,通过模型优化、系统架构和自适应智能三个方面来解决该问题。
- 论文概述了标准化评估协议,涵盖延迟、吞吐量、能耗、准确性、鲁棒性、隐私和可持续性等指标。
📝 摘要(中文)
本文综述了认知边缘计算,作为一种在资源受限的网络边缘设备上部署具备推理能力的大语言模型(LLM)和自主AI Agent的实用且系统的方法。我们提出了一个统一的、认知保持的框架,涵盖:(1)模型优化(量化、稀疏化、低秩适应、蒸馏),旨在在严格的内存/计算预算下保持多步推理;(2)系统架构(设备端推理、弹性卸载、云边协同),权衡延迟、能耗、隐私和容量;(3)自适应智能(上下文压缩、动态路由、联邦个性化),根据任务难度和设备约束调整计算。我们综合了高效Transformer设计、多模态集成、硬件感知编译、隐私保护学习和Agent工具使用的进展,并将它们映射到边缘特定的操作范围。我们进一步概述了一个标准化的评估协议,涵盖延迟、吞吐量、每token能耗、准确性、鲁棒性、隐私和可持续性,并明确测量假设以提高可比性。剩余的挑战包括模态感知推理基准、透明且可复现的能耗报告、面向边缘的安全/对齐评估以及多Agent测试平台。最后,我们总结了算法、运行时和硬件跨层协同设计的实践指南,以在边缘设备上提供可靠、高效和隐私保护的认知能力。
🔬 方法详解
问题定义:论文旨在解决如何在资源受限的边缘设备上部署大型语言模型(LLM)和自主AI Agent,同时保持其推理能力的问题。现有方法在边缘设备上部署LLM时,面临着计算资源不足、内存限制、能耗过高以及隐私泄露等挑战。
核心思路:论文的核心思路是提出一个认知边缘计算框架,通过模型优化、系统架构和自适应智能三个方面协同工作,以在边缘设备上实现高效、可靠和隐私保护的认知能力。该框架旨在保留LLM在资源受限环境下的多步推理能力。
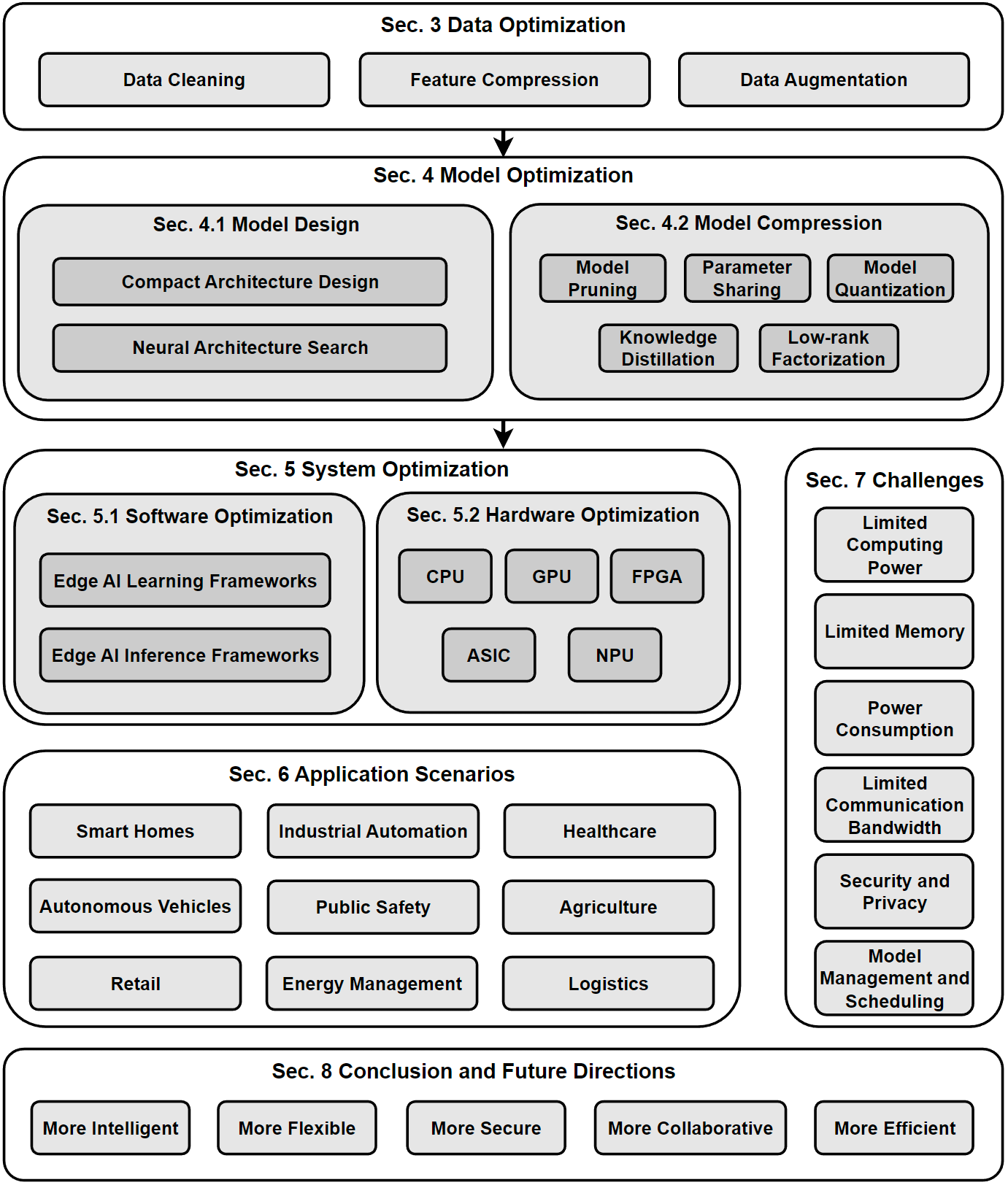
技术框架:该框架包含三个主要模块:1) 模型优化:采用量化、稀疏化、低秩适应和蒸馏等技术,压缩模型大小并降低计算复杂度;2) 系统架构:通过设备端推理、弹性卸载和云边协同等方式,权衡延迟、能耗、隐私和容量;3) 自适应智能:利用上下文压缩、动态路由和联邦个性化等技术,根据任务难度和设备约束调整计算。
关键创新:该框架的创新之处在于其统一性和认知保持性。它将模型优化、系统架构和自适应智能整合到一个框架中,并致力于在资源受限的环境下保持LLM的推理能力。此外,论文还强调了标准化评估协议的重要性,以提高不同方法的可比性。
关键设计:在模型优化方面,论文探讨了各种压缩技术的适用性,并强调了在压缩过程中保持模型推理能力的重要性。在系统架构方面,论文讨论了不同卸载策略的优缺点,并提出了云边协同的方案。在自适应智能方面,论文研究了如何根据任务难度和设备约束动态调整计算资源。
🖼️ 关键图片


📊 实验亮点
论文提出了一个标准化的评估协议,涵盖延迟、吞吐量、每token能耗、准确性、鲁棒性、隐私和可持续性等指标,并明确测量假设以提高可比性。这有助于研究人员更好地评估和比较不同的认知边缘计算方法。
🎯 应用场景
该研究成果可应用于智能家居、自动驾驶、工业物联网、智慧医疗等领域。通过在边缘设备上部署LLM和AI Agent,可以实现更快速、更可靠、更隐私的智能服务,例如本地语音助手、实时交通预测、设备故障诊断和个性化健康监测等。
📄 摘要(原文)
This article surveys Cognitive Edge Computing as a practical and methodical pathway for deploying reasoning-capable Large Language Models (LLMs) and autonomous AI agents on resource-constrained devices at the network edge. We present a unified, cognition-preserving framework spanning: (1) model optimization (quantization, sparsity, low-rank adaptation, distillation) aimed at retaining multi-step reasoning under tight memory/compute budgets; (2) system architecture (on-device inference, elastic offloading, cloud-edge collaboration) that trades off latency, energy, privacy, and capacity; and (3) adaptive intelligence (context compression, dynamic routing, federated personalization) that tailors computation to task difficulty and device constraints. We synthesize advances in efficient Transformer design, multimodal integration, hardware-aware compilation, privacy-preserving learning, and agentic tool use, and map them to edge-specific operating envelopes. We further outline a standardized evaluation protocol covering latency, throughput, energy per token, accuracy, robustness, privacy, and sustainability, with explicit measurement assumptions to enhance comparability. Remaining challenges include modality-aware reasoning benchmarks, transparent and reproducible energy reporting, edge-oriented safety/alignment evaluation, and multi-agent testbeds. We conclude with practitioner guidelines for cross-layer co-design of algorithms, runtime, and hardware to deliver reliable, efficient, and privacy-preserving cognitive capabilities on edge devices.