On the Statistical Complexity for Offline and Low-Adaptive Reinforcement Learning with Structures
作者: Ming Yin, Mengdi Wang, Yu-Xiang Wang
分类: cs.LG, cs.AI
发布日期: 2025-01-03
备注: Review Article
💡 一句话要点
研究离线与低自适应强化学习的统计复杂性,为实际应用提供理论基础。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 离线策略评估 离线策略学习 统计复杂性 实例相关界限
📋 核心要点
- 现有强化学习方法在实际应用中面临数据获取困难和探索风险高的问题,离线强化学习提供了一种利用现有数据集进行策略学习的解决方案。
- 论文关注离线策略评估和离线策略学习的统计复杂性,旨在为这些问题提供更严格的理论界限和高效的算法。
- 研究还探讨了低自适应探索,作为离线和在线强化学习之间的桥梁,以克服离线RL的局限性并提高学习效率。
📝 摘要(中文)
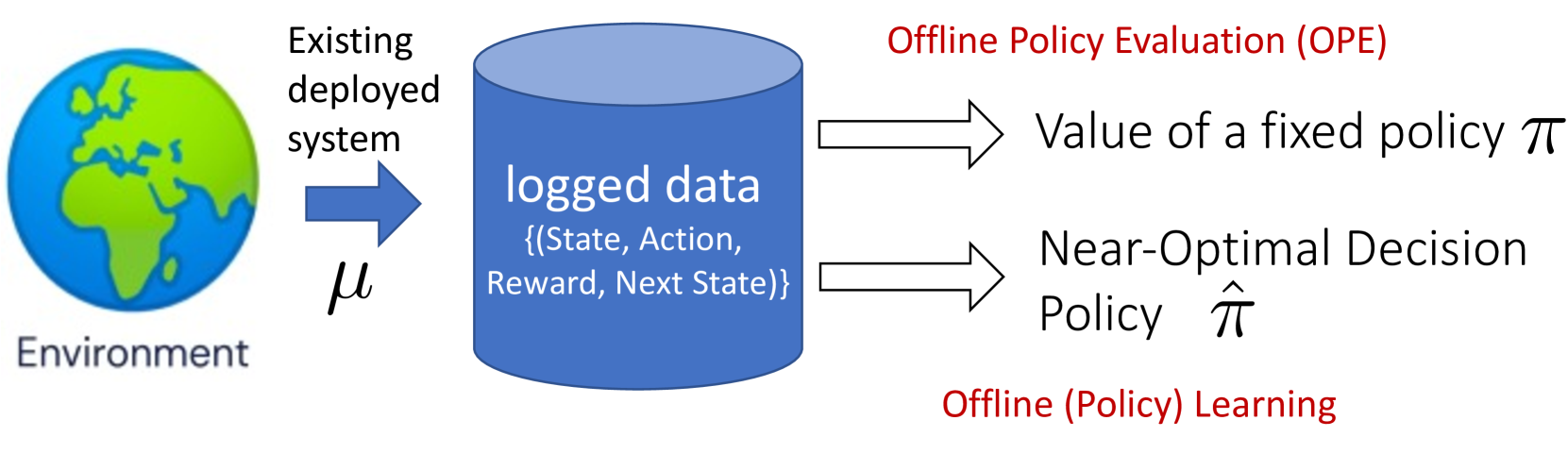
本文综述了离线和低自适应强化学习(RL)统计基础的最新进展。首先,论证了为什么离线RL是几乎所有现实机器学习问题的适当模型,即使它们与最近使用RL的人工智能突破无关。然后,深入研究离线RL的两个基本问题:离线策略评估(OPE)和离线策略学习(OPL)。令人惊讶的是,直到最近,即使对于表格和线性情况,这些问题的严格界限仍然未知。我们描述了最坏情况下的极小极大界限和实例相关界限之间的差异。我们还介绍了OPE和OPL中近乎最优的实例相关方法背后的关键算法思想和证明技术。最后,我们讨论了离线RL的局限性,并回顾了一个新兴的“低自适应探索”问题,该问题通过在离线和在线RL之间提供一个理想的中间地带来解决这些局限性。
🔬 方法详解
问题定义:论文主要关注离线强化学习中的两个核心问题:离线策略评估(OPE)和离线策略学习(OPL)。现有方法在表格和线性情况下,对于这两个问题的理论界限不够明确,尤其是在实例相关界限方面。此外,离线RL由于依赖于固定数据集,缺乏探索能力,限制了其在复杂环境中的应用。
核心思路:论文的核心思路是深入研究离线RL的统计复杂性,通过理论分析推导出更严格的实例相关界限,并设计相应的算法。同时,引入低自适应探索的概念,允许在一定程度上进行探索,以克服离线RL的局限性。
技术框架:论文首先对离线RL的基本概念和问题进行了定义,然后分别针对OPE和OPL问题,分析了现有方法的不足,并提出了改进的算法。对于OPE,重点关注如何利用实例相关信息来提高评估精度;对于OPL,则关注如何设计策略优化算法,使其能够在离线数据上学习到更好的策略。最后,讨论了低自适应探索的框架,并探讨了如何在探索和利用之间进行权衡。
关键创新:论文的关键创新在于对离线RL的统计复杂性进行了更深入的分析,推导出了更严格的实例相关界限。此外,提出了低自适应探索的概念,为离线RL提供了一种新的探索机制,使其能够在一定程度上克服离线数据的局限性。
关键设计:论文中涉及的关键设计包括:针对OPE问题,如何设计实例相关的评估指标;针对OPL问题,如何设计策略优化算法,使其能够在离线数据上稳定学习;针对低自适应探索,如何设计探索策略,使其能够在有限的探索预算下,最大程度地提高学习效率。具体的参数设置、损失函数和网络结构等细节,需要根据具体的应用场景进行调整。
🖼️ 关键图片


📊 实验亮点
论文重点在于理论分析,为离线策略评估和离线策略学习提供了更严格的实例相关界限,这为算法设计提供了理论指导。虽然没有提供具体的实验数据,但理论上的突破为后续的算法改进和实际应用奠定了基础。低自适应探索的概念也为解决离线RL的局限性提供了一种新的思路。
🎯 应用场景
该研究成果可应用于医疗诊断、金融交易、自动驾驶等领域。在这些领域中,通常存在大量的历史数据,但在线交互成本较高或存在安全风险。通过离线强化学习,可以利用这些历史数据训练智能体,从而在实际应用中做出更优决策,降低成本和风险。低自适应探索则进一步提升了智能体在复杂环境中的适应能力。
📄 摘要(原文)
This article reviews the recent advances on the statistical foundation of reinforcement learning (RL) in the offline and low-adaptive settings. We will start by arguing why offline RL is the appropriate model for almost any real-life ML problems, even if they have nothing to do with the recent AI breakthroughs that use RL. Then we will zoom into two fundamental problems of offline RL: offline policy evaluation (OPE) and offline policy learning (OPL). It may be surprising to people that tight bounds for these problems were not known even for tabular and linear cases until recently. We delineate the differences between worst-case minimax bounds and instance-dependent bounds. We also cover key algorithmic ideas and proof techniques behind near-optimal instance-dependent methods in OPE and OPL. Finally, we discuss the limitations of offline RL and review a burgeoning problem of \emph{low-adaptive exploration} which addresses these limitations by providing a sweet middle ground between offline and online RL.