Quantifying True Robustness: Synonymity-Weighted Similarity for Trustworthy XAI Evaluation
作者: Christopher Burger
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-01-02 (更新: 2025-12-29)
备注: 10 pages, 2 figures, 6 tables. Changes to title, abstract and minor edits to the content as a result of acceptance to the 59th Hawaii International Conference on System Sciences
💡 一句话要点
提出基于同义词加权相似度的XAI评估方法,提升对抗攻击鲁棒性评估的准确性。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 可解释人工智能 对抗攻击 鲁棒性评估 同义词加权 语义相似度
📋 核心要点
- 现有基于文本的XAI评估方法,如信息检索指标,无法准确衡量对抗攻击的影响,忽略了同义词替换的语义相似性。
- 论文提出同义词加权方法,通过考虑扰动词的语义相似性来修正评估指标,从而更准确地评估XAI系统的鲁棒性。
- 该方法能够防止对攻击成功率的过高估计,从而更真实地反映XAI系统抵抗对抗性操纵的能力。
📝 摘要(中文)
对抗攻击通过在模型输出不变的情况下改变解释,对可解释人工智能(XAI)的可靠性提出了挑战。这些攻击在基于文本的XAI上的成功通常使用标准信息检索指标来判断。我们认为这些指标不适合评估可信度,因为它们平等地对待所有单词扰动,而忽略了同义性,这可能会错误地表示攻击的真实影响。为了解决这个问题,我们应用同义词加权,这是一种通过结合扰动词的语义相似性来修正这些指标的方法。这产生了更准确的漏洞评估,并为评估AI系统对抗对抗性操纵的真实弹性提供了一个重要的工具。我们的方法防止了对攻击成功的过度估计,从而更真实地理解XAI系统抵抗对抗性操纵的真实能力。
🔬 方法详解
问题定义:现有基于文本的XAI评估方法在评估对抗攻击的有效性时存在缺陷。这些方法通常使用信息检索指标,平等对待所有单词的扰动,忽略了同义词替换等语义相似性。这导致对攻击效果的过度估计,无法真实反映XAI系统的脆弱性。现有方法的痛点在于无法区分无意义的扰动和语义上相似的扰动,从而影响了对XAI系统鲁棒性的准确评估。
核心思路:论文的核心思路是引入同义词加权的概念,通过考虑扰动词与原始词之间的语义相似性来修正现有的评估指标。具体来说,对于语义上更相似的扰动,赋予更小的权重,反之则赋予更大的权重。这样可以更准确地反映攻击对XAI解释的真实影响,避免因同义词替换等语义保持的扰动而高估攻击的成功率。
技术框架:该方法主要包含以下几个阶段:1. 对抗攻击生成:使用对抗攻击方法对输入文本进行扰动,生成对抗样本。2. XAI解释生成:使用XAI方法(如LIME、SHAP)对原始样本和对抗样本生成解释。3. 相似度计算:计算原始词和扰动词之间的语义相似度,例如使用WordNet、BERT等预训练模型。4. 加权评估:使用同义词加权后的信息检索指标(如Precision、Recall、F1-score)评估对抗攻击的效果。
关键创新:最重要的技术创新点在于将同义词相似度融入到XAI评估指标中。与现有方法平等对待所有扰动不同,该方法能够区分语义保持的扰动和语义改变的扰动,从而更准确地评估XAI系统的鲁棒性。这种方法提供了一种更细粒度的评估方式,能够更真实地反映XAI系统抵抗对抗性操纵的能力。
关键设计:关键设计在于如何选择合适的语义相似度度量方法以及如何将相似度值融入到评估指标中。论文可能使用了WordNet的同义词集来判断两个词是否为同义词,并使用预训练语言模型(如BERT)计算词向量的余弦相似度。在评估指标方面,可以将相似度值作为权重,对Precision、Recall等指标进行修正,例如,将扰动词的权重设置为其与原始词的相似度值。
🖼️ 关键图片

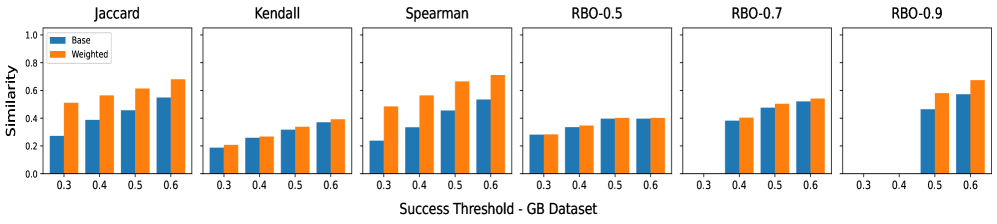
📊 实验亮点
论文提出同义词加权方法,有效降低了对抗攻击成功率的过高估计。通过考虑同义词的语义相似性,能够更准确地评估XAI系统的鲁棒性。具体的性能数据、对比基线和提升幅度未知,需要在论文中查找。
🎯 应用场景
该研究成果可应用于提升自然语言处理系统中XAI解释的可靠性和鲁棒性。例如,在金融风控、医疗诊断等高风险领域,确保XAI解释在面对对抗攻击时仍然可信,有助于提高决策的透明度和可信度。此外,该方法还可以用于评估和改进现有的XAI算法,使其更加稳定和可靠。
📄 摘要(原文)
Adversarial attacks challenge the reliability of Explainable AI (XAI) by altering explanations while the model's output remains unchanged. The success of these attacks on text-based XAI is often judged using standard information retrieval metrics. We argue these measures are poorly suited in the evaluation of trustworthiness, as they treat all word perturbations equally while ignoring synonymity, which can misrepresent an attack's true impact. To address this, we apply synonymity weighting, a method that amends these measures by incorporating the semantic similarity of perturbed words. This produces more accurate vulnerability assessments and provides an important tool for assessing the robustness of AI systems. Our approach prevents the overestimation of attack success, leading to a more faithful understanding of an XAI system's true resilience against adversarial manipulation.