Understanding Difficult-to-learn Examples in Contrastive Learning: A Theoretical Framework for Spectral Contrastive Learning
作者: Yi-Ge Zhang, Jingyi Cui, Qiran Li, Yisen Wang
分类: cs.LG, cs.AI
发布日期: 2025-01-02
💡 一句话要点
提出谱对比学习理论框架,揭示难学样本对对比学习泛化性的负面影响
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 对比学习 无监督学习 难学样本 泛化性 谱分析
📋 核心要点
- 对比学习性能优异,但其与监督学习的学习机制不同,难学样本的作用也不同。
- 论文核心思想是构建理论框架,分析难学样本对对比学习泛化性的影响,并提出移除难学样本的策略。
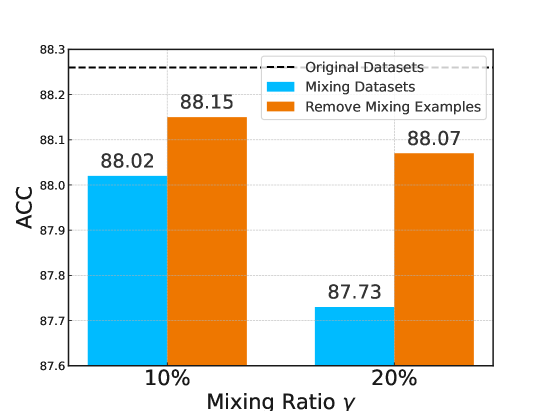
- 实验结果表明,移除难学样本、调整margin和温度等方法可以有效提升对比学习的性能。
📝 摘要(中文)
近年来,无监督对比学习在各种任务中表现出显著的性能提升,通常接近甚至超过有监督学习。然而,其学习机制与有监督学习有着根本的不同。以往的研究表明,在有监督学习中至关重要的难学样本(即决策边界附近的样本)在无监督环境中贡献甚微。本文发现,直接移除难学样本虽然减少了样本量,但可以提高对比学习的下游分类性能,这可能令人惊讶。为了揭示其背后的原因,我们建立了一个理论框架来模拟不同样本对之间的相似性。在该理论框架的指导下,我们进行了全面的理论分析,揭示了难学样本的存在对对比学习的泛化性产生负面影响。此外,我们证明了移除这些样本以及调整margin和温度等技术可以增强其泛化界限,从而提高性能。在实验上,我们提出了一种简单有效的机制来选择难学样本,并验证了上述方法的有效性,从而证实了我们提出的理论框架的可靠性。
🔬 方法详解
问题定义:对比学习在无监督表示学习中取得了显著进展,但其内在机制与监督学习不同。监督学习中重要的难学样本在对比学习中作用甚微,甚至可能损害性能。现有方法缺乏对难学样本在对比学习中作用的理论分析,以及有效去除难学样本的策略。
核心思路:论文的核心思路是构建一个理论框架,用于建模样本对之间的相似性,并分析难学样本对对比学习泛化性的影响。通过理论分析,揭示难学样本的存在会损害对比学习的泛化能力。基于此,提出移除难学样本,并结合margin调整和温度缩放等技术,以提升对比学习的性能。
技术框架:论文构建了一个谱对比学习的理论框架,该框架主要包含以下几个部分:1) 定义样本对之间的相似性度量;2) 基于相似性度量,构建样本的相似性图;3) 分析相似性图的谱性质,推导对比学习的泛化误差界;4) 基于泛化误差界,分析难学样本的影响,并提出相应的优化策略。
关键创新:论文最重要的创新点在于提出了一个谱对比学习的理论框架,该框架能够定量分析难学样本对对比学习泛化性的影响。与现有方法相比,该框架不仅提供了理论解释,还指导了实际算法的设计,例如难学样本的选择和移除策略。
关键设计:论文的关键设计包括:1) 相似性度量的选择,论文可能采用了余弦相似度或其他合适的相似性度量;2) 难学样本的选择机制,论文提出了一种简单有效的机制来选择难学样本,具体细节未知;3) margin调整和温度缩放的具体策略,这些策略可能涉及到对损失函数的修改或对模型输出的后处理。
🖼️ 关键图片

📊 实验亮点
论文通过实验验证了移除难学样本、调整margin和温度等方法可以有效提升对比学习的性能。具体的性能数据、对比基线和提升幅度在摘要中未明确给出,但强调了实验结果证实了理论框架的可靠性。实验部分的关键在于验证了所提出的难学样本选择机制的有效性。
🎯 应用场景
该研究成果可应用于各种无监督表示学习任务,例如图像分类、目标检测、自然语言处理等。通过移除难学样本,可以提升对比学习模型的泛化能力和鲁棒性,从而提高下游任务的性能。该研究对于理解对比学习的内在机制,以及设计更有效的对比学习算法具有重要的理论和实践意义。
📄 摘要(原文)
Unsupervised contrastive learning has shown significant performance improvements in recent years, often approaching or even rivaling supervised learning in various tasks. However, its learning mechanism is fundamentally different from that of supervised learning. Previous works have shown that difficult-to-learn examples (well-recognized in supervised learning as examples around the decision boundary), which are essential in supervised learning, contribute minimally in unsupervised settings. In this paper, perhaps surprisingly, we find that the direct removal of difficult-to-learn examples, although reduces the sample size, can boost the downstream classification performance of contrastive learning. To uncover the reasons behind this, we develop a theoretical framework modeling the similarity between different pairs of samples. Guided by this theoretical framework, we conduct a thorough theoretical analysis revealing that the presence of difficult-to-learn examples negatively affects the generalization of contrastive learning. Furthermore, we demonstrate that the removal of these examples, and techniques such as margin tuning and temperature scaling can enhance its generalization bounds, thereby improving performance. Empirically, we propose a simple and efficient mechanism for selecting difficult-to-learn examples and validate the effectiveness of the aforementioned methods, which substantiates the reliability of our proposed theoretical framework.