Adjoint sharding for very long context training of state space models
作者: Xingzi Xu, Amir Tavanaei, Kavosh Asadi, Karim Bouyarmane
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-01-01
💡 一句话要点
提出 adjoint sharding 方法,解决超长上下文状态空间模型训练中的内存瓶颈问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 超长上下文 状态空间模型 梯度分片 伴随方法 内存优化
📋 核心要点
- 现有LLM训练方法在处理超长上下文时面临内存和计算效率的挑战,限制了其在需要长上下文训练/微调的应用中的潜力。
- Adjoint sharding通过对梯度计算进行分片,显著降低内存需求,使得在超长上下文中训练大型语言模型成为可能。
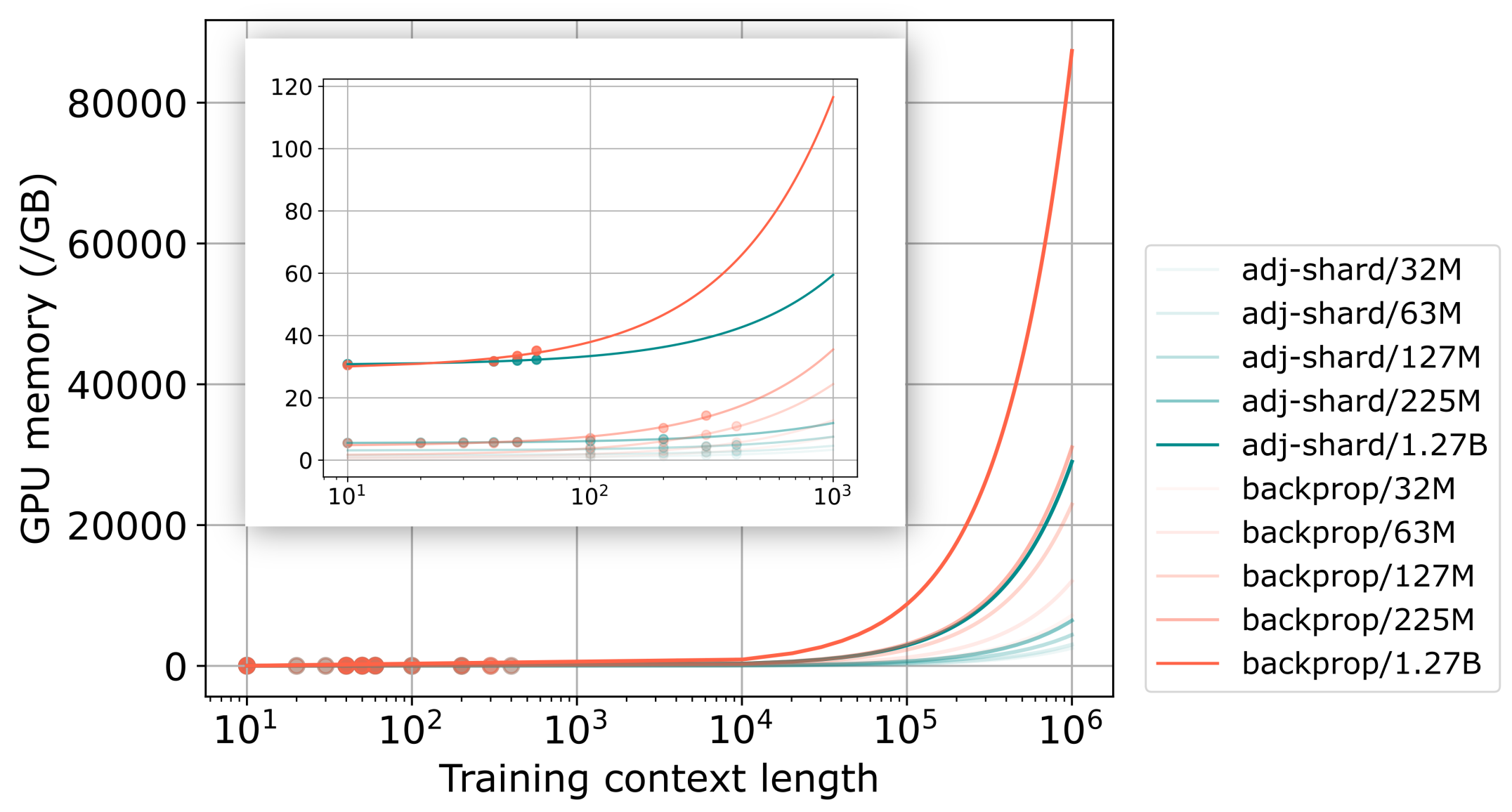
- 实验结果表明,Adjoint sharding能够显著降低内存使用量,并允许在现有硬件上训练更长的上下文,提升模型性能。
📝 摘要(中文)
尽管大型语言模型(LLM)取得了快速进展,但在超长上下文中高效训练它们仍然具有挑战性。现有方法通常退回到使用短上下文训练LLM(最多几千个token),并在评估长上下文(推理时超过100万个token上下文窗口)时使用推理时技术。与长上下文推理相反,在超长上下文输入提示上进行训练很快就会受到GPU内存可用性和最先进硬件上所需过长训练时间的限制。同时,许多实际应用不仅需要推理,还需要在特定任务上使用长上下文进行训练/微调。这些应用包括,例如,使用各种原始参考信息源来扩充上下文,以用于事实提取、事实总结或事实协调任务。我们提出adjoint sharding,这是一种新颖的技术,包括在训练期间对梯度计算进行分片,以将内存需求降低几个数量级,从而使在超长上下文中进行训练在计算上易于处理。Adjoint sharding基于伴随方法,并计算与反向传播等效的梯度。我们还提出了截断的adjoint sharding,以加快算法速度,同时保持性能。我们提供了分布式版本和并行版本的adjoint sharding,以进一步加快训练速度。经验结果表明,所提出的adjoint sharding算法在100万上下文长度训练中,使用12.7亿参数的大型语言模型,可将内存使用量减少高达3倍。这允许在由五个AWS P4实例组成的训练基础设施上,将12.7亿参数模型的训练或微调期间的最大上下文长度从35K token增加到100K token以上。
🔬 方法详解
问题定义:现有的大型语言模型训练方法在处理超长上下文时,面临着GPU内存不足和训练时间过长的问题。传统的反向传播算法在训练过程中需要存储大量的中间激活值,导致内存需求随着上下文长度的增加而线性增长。这使得在实际应用中,很难直接使用超长上下文进行训练或微调。
核心思路:论文的核心思路是利用伴随方法(adjoint method)来计算梯度,并对梯度计算过程进行分片(sharding),从而显著降低内存需求。伴随方法通过求解一个伴随方程来计算梯度,避免了存储大量中间激活值的需要。通过对伴随方程的求解过程进行分片,可以将内存需求进一步降低。
技术框架:Adjoint sharding的整体框架包括以下几个主要步骤:1)前向传播:计算模型的输出;2)伴随方程求解:利用伴随方法计算梯度;3)梯度分片:将梯度计算过程分成多个小的计算块,每个计算块在不同的GPU上执行;4)梯度聚合:将各个GPU上的梯度计算结果进行聚合,得到最终的梯度。此外,论文还提出了截断的adjoint sharding,通过减少伴随方程的求解次数来进一步加速训练。
关键创新:该方法最重要的创新点在于将伴随方法和梯度分片技术结合起来,从而在不影响模型性能的前提下,显著降低了训练过程中的内存需求。与传统的反向传播算法相比,Adjoint sharding避免了存储大量中间激活值的需要,从而可以处理更长的上下文。
关键设计:论文中关键的设计包括:1)伴随方程的求解方法;2)梯度分片策略;3)截断adjoint sharding的截断长度选择;4)分布式和并行版本的实现细节。这些设计都对算法的性能和可扩展性产生了重要影响。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Adjoint sharding 能够显著降低内存使用量,在使用 12.7 亿参数的模型和 100 万上下文长度进行训练时,内存使用量减少高达 3 倍。此外,该方法还允许在现有硬件上训练更长的上下文,将 12.7 亿参数模型的训练或微调期间的最大上下文长度从 35K token 增加到 100K token 以上。
🎯 应用场景
Adjoint sharding 在需要处理超长上下文的自然语言处理任务中具有广泛的应用前景,例如事实提取、事实总结、事实协调等。通过该方法,可以利用更多的上下文信息来提高模型的性能,从而更好地解决实际问题。此外,该方法还可以应用于其他领域,例如时间序列分析、生物信息学等,这些领域也需要处理长序列数据。
📄 摘要(原文)
Despite very fast progress, efficiently training large language models (LLMs) in very long contexts remains challenging. Existing methods fall back to training LLMs with short contexts (a maximum of a few thousands tokens in training) and use inference time techniques when evaluating on long contexts (above 1M tokens context window at inference). As opposed to long-context-inference, training on very long context input prompts is quickly limited by GPU memory availability and by the prohibitively long training times it requires on state-of-the-art hardware. Meanwhile, many real-life applications require not only inference but also training/fine-tuning with long context on specific tasks. Such applications include, for example, augmenting the context with various sources of raw reference information for fact extraction, fact summarization, or fact reconciliation tasks. We propose adjoint sharding, a novel technique that comprises sharding gradient calculation during training to reduce memory requirements by orders of magnitude, making training on very long context computationally tractable. Adjoint sharding is based on the adjoint method and computes equivalent gradients to backpropagation. We also propose truncated adjoint sharding to speed up the algorithm while maintaining performance. We provide a distributed version, and a paralleled version of adjoint sharding to further speed up training. Empirical results show the proposed adjoint sharding algorithm reduces memory usage by up to 3X with a 1.27B parameter large language model on 1M context length training. This allows to increase the maximum context length during training or fine-tuning of a 1.27B parameter model from 35K tokens to above 100K tokens on a training infrastructure composed of five AWS P4 instances.