Beyond Introspection: Reinforcing Thinking via Externalist Behavioral Feedback
作者: Diji Yang, Linda Zeng, Kezhen Chen, Yi Zhang
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-12-31 (更新: 2025-11-27)
💡 一句话要点
提出DRR框架,通过外部行为反馈增强LLM的推理能力,克服自省幻觉。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 推理增强 外部反馈 行为评估 判别模型
📋 核心要点
- LLM推理过程易受自身概率性和知识边界影响,导致结果不稳定,自批判方法存在“内省幻觉”问题。
- DRR框架通过外部判别模型评估LLM行为,提供纠正性反馈,引导模型探索更优推理路径。
- 实验表明,DRR在多个推理基准上显著优于自批判方法,且具有轻量级和无标注的优点。
📝 摘要(中文)
为了解决大型语言模型(LLM)在推理过程中因概率性以及知识边界附近而产生的不稳定和不一致问题,本文提出了一种名为Distillation-Reinforcement-Reasoning(DRR)的外部主义三步框架,旨在超越内省的局限。DRR借鉴了动物行为学的方法,通过评估LLM的可观察行为来提供纠正性反馈,而非依赖模型自身的反思。该框架首先提炼推理器的行为轨迹,然后训练一个轻量级的外部判别模型(DM)。在推理时,DM充当评论员,识别并拒绝可疑的推理步骤。这种外部反馈促使LLM放弃有缺陷的路径并探索替代方案,从而在不改变基础模型的情况下提高推理质量。在多个推理基准上的实验表明,DRR框架显著优于现有的自批判方法。受益于轻量级和无标注的设计,DRR为提高各种LLM推理的可靠性提供了一个可扩展且适应性强的解决方案。
🔬 方法详解
问题定义:大型语言模型在复杂问题推理时,由于其内在的概率性和知识边界的限制,推理过程可能出现不一致和不可靠的情况。现有的自批判方法试图通过模型自身的反思来纠正错误,但这种自我反思容易受到“内省幻觉”的影响,即模型无法识别自身推理中的偏差。因此,如何有效地提高LLM推理的可靠性,克服自省幻觉,是一个亟待解决的问题。
核心思路:DRR框架的核心思路是借鉴动物行为学中的外部观察和反馈机制,通过训练一个外部的判别模型(DM)来评估LLM的推理行为,并提供纠正性反馈。这种外部反馈可以避免模型自身的偏差,引导模型探索更优的推理路径,从而提高推理的可靠性。
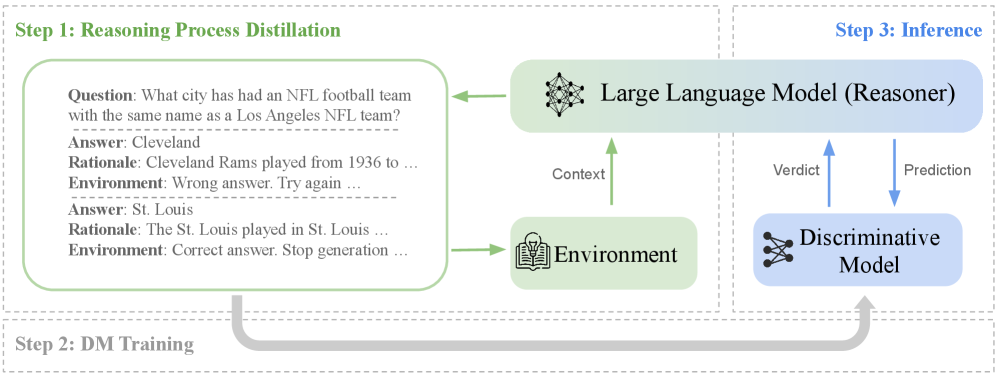
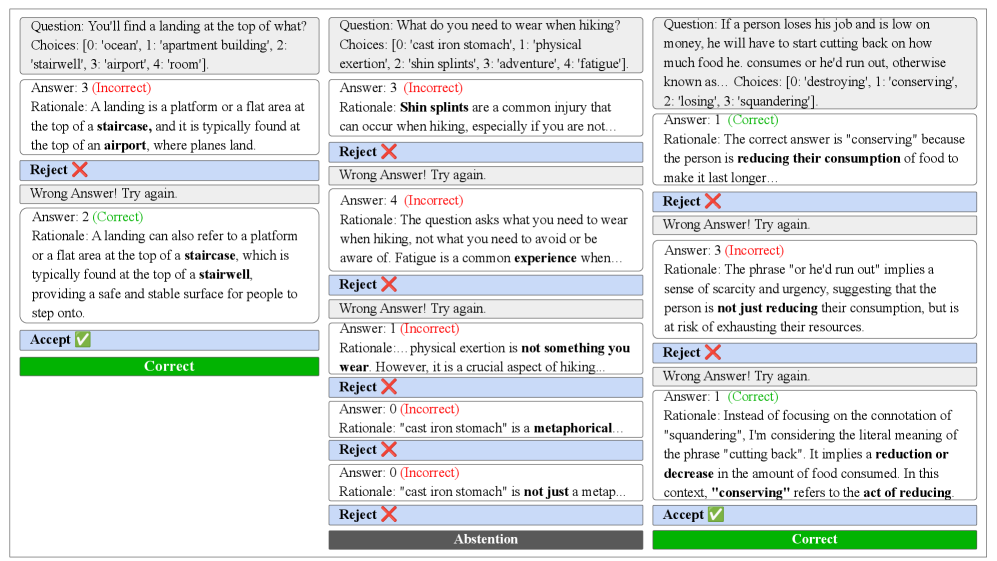
技术框架:DRR框架包含三个主要阶段:1. Distillation(蒸馏): 从LLM的推理过程中提取行为轨迹数据,用于训练判别模型。2. Reinforcement(强化): 使用蒸馏得到的数据训练一个轻量级的外部判别模型(DM),该模型能够评估LLM推理步骤的质量。3. Reasoning(推理): 在推理过程中,DM作为评论员,对LLM的每个推理步骤进行评估,如果DM认为某个步骤可疑,则拒绝该步骤,并促使LLM探索其他推理路径。
关键创新:DRR框架的关键创新在于引入了外部判别模型来评估LLM的推理行为,从而避免了自批判方法中的“内省幻觉”问题。与现有方法相比,DRR不依赖于模型自身的反思,而是通过外部反馈来提高推理的可靠性。此外,DRR框架采用轻量级和无标注的设计,使其具有良好的可扩展性和适应性。
关键设计:判别模型(DM)通常是一个轻量级的分类器,例如小型Transformer模型或MLP。DM的训练数据来自LLM的推理轨迹,正样本是正确的推理步骤,负样本是错误的推理步骤。损失函数通常采用交叉熵损失。在推理过程中,DM会为每个推理步骤打分,如果分数低于某个阈值,则认为该步骤可疑,并拒绝该步骤。阈值的选择需要根据具体的任务和数据集进行调整。
🖼️ 关键图片
📊 实验亮点
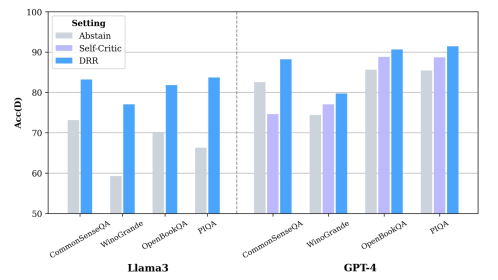
实验结果表明,DRR框架在多个推理基准上显著优于现有的自批判方法。例如,在某些基准测试中,DRR的性能提升超过10%。此外,DRR框架的轻量级设计使其易于部署和扩展,可以在各种LLM上应用,而无需对基础模型进行修改。
🎯 应用场景
DRR框架可广泛应用于需要高可靠性推理的领域,如医疗诊断、金融分析、法律咨询等。通过提高LLM推理的准确性和可靠性,DRR有助于构建更值得信赖的AI系统,并促进LLM在各个领域的应用。未来,DRR可以与其他技术相结合,例如知识图谱、符号推理等,进一步提升LLM的推理能力。
📄 摘要(原文)
While inference-time thinking allows Large Language Models (LLMs) to address complex problems, the extended thinking process can be unreliable or inconsistent because of the model's probabilistic nature, especially near its knowledge boundaries. Existing approaches attempt to mitigate this by having the model critique its own reasoning to make corrections. However, such self-critique inherits the same biases of the original output, known as the introspection illusion. Moving beyond such introspection and inspired by core methodologies in ethology, we propose an externalist three-step framework Distillation-Reinforcement-Reasoning (DRR). Rather than relying on a model's introspection, DRR evaluates its observable behaviors to provide corrective feedback. DRR first distills the reasoner's behavioral traces, then trains a lightweight, external Discriminative Model (DM). At inference time, this DM acts as a critic, identifying and rejecting suspicious reasoning steps. This external feedback compels the LLM to discard flawed pathways and explore alternatives, thereby enhancing reasoning quality without altering the base model. Experiments on multiple reasoning benchmarks show that our framework significantly outperforms prominent self-critique methods. Benefiting from a lightweight and annotation-free design, DRR offers a scalable and adaptable solution for improving the reliability of reasoning in a wide range of LLMs.