Understanding and Mitigating Bottlenecks of State Space Models through the Lens of Recency and Over-smoothing
作者: Peihao Wang, Ruisi Cai, Yuehao Wang, Jiajun Zhu, Pragya Srivastava, Zhangyang Wang, Pan Li
分类: cs.LG
发布日期: 2024-12-31 (更新: 2025-03-11)
备注: International Conference on Learning Representations (ICLR), 2025
🔗 代码/项目: GITHUB
💡 一句话要点
通过分析SSM的近因偏见和过平滑问题,提出极化技术以提升长程依赖建模能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 状态空间模型 长程依赖 近因偏见 过平滑 极化技术 序列建模 深度学习 鲁棒性
📋 核心要点
- 现有SSM模型在处理长序列时存在近因偏见,导致模型难以回忆远距离信息,影响鲁棒性。
- 论文提出极化技术,通过将SSM状态转移矩阵的两个通道分别设置为零和一,来解决近因偏见和过平滑问题。
- 实验结果表明,该极化技术能够显著提高SSM模型在长程关联回忆任务中的准确率,并使其能够受益于更深层的架构。
📝 摘要(中文)
结构化状态空间模型(SSM)已成为Transformer的替代方案。虽然SSM通常被认为在捕获长序列依赖关系方面有效,但我们严格证明了它们本质上受到强烈的近因偏见限制。我们的经验研究还表明,这种偏见会损害模型回忆远距离信息的能力,并引入鲁棒性问题。我们的缩放实验发现,SSM中更深层的结构可以促进长上下文的学习。然而,随后的理论分析表明,随着SSM深度的增加,它们表现出另一种不可避免的过度平滑趋势,例如,token表示变得越来越难以区分。这种近因偏见和过度平滑之间的根本困境阻碍了现有SSM的可扩展性。受我们的理论发现的启发,我们提出极化SSM中状态转移矩阵的两个通道,将它们分别设置为零和一,从而同时解决近因偏见和过度平滑问题。实验表明,我们的极化技术始终提高长程token的关联回忆准确率,并解锁SSM以从更深层的架构中受益。所有源代码均已发布在https://github.com/VITA-Group/SSM-Bottleneck。
🔬 方法详解
问题定义:现有结构化状态空间模型(SSM)在处理长序列时,虽然理论上能够捕获长程依赖,但实际上存在两个主要问题:一是近因偏见,即模型更倾向于关注最近的信息,而忽略较早的信息;二是随着模型深度的增加,会出现过平滑现象,导致不同token的表示变得难以区分,从而限制了模型的性能。这些问题阻碍了SSM在长序列建模任务中的应用。
核心思路:论文的核心思路是通过极化状态转移矩阵来同时解决近因偏见和过平滑问题。具体来说,将状态转移矩阵的两个通道分别设置为0和1,从而使得模型能够更好地平衡近距离和远距离的信息,并减少过平滑现象的发生。这种极化操作旨在增强模型对长程依赖的建模能力。
技术框架:论文提出的方法主要针对SSM模型中的状态转移矩阵进行改进。整体框架保持了SSM的基本结构,包括输入线性变换、状态更新和输出线性变换等模块。关键的修改在于状态更新模块,其中状态转移矩阵被极化为两个通道,分别负责不同的信息传递。
关键创新:论文最重要的技术创新点在于提出了极化状态转移矩阵的概念,并将其应用于SSM模型中。与传统的SSM模型相比,极化后的模型能够更好地平衡近距离和远距离的信息,从而有效地缓解了近因偏见和过平滑问题。这种极化操作是一种简单而有效的改进方法,可以显著提高SSM模型在长序列建模任务中的性能。
关键设计:论文的关键设计在于如何将状态转移矩阵极化为两个通道。具体来说,对于状态转移矩阵A,将其分解为两个矩阵A1和A2,然后将A1的元素设置为0,将A2的元素设置为1。这两个矩阵分别负责不同的信息传递,从而使得模型能够更好地平衡近距离和远距离的信息。此外,论文还对极化操作的具体实现方式进行了优化,以确保模型的稳定性和性能。
🖼️ 关键图片

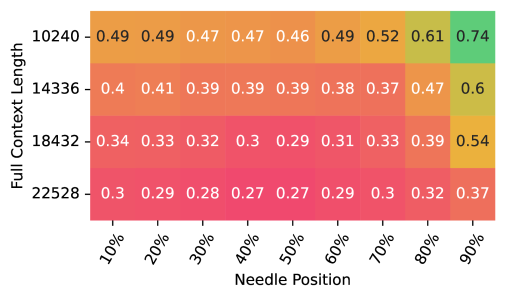

📊 实验亮点
实验结果表明,提出的极化技术能够显著提高SSM模型在长程关联回忆任务中的准确率。例如,在某个长序列数据集上,使用极化技术的SSM模型相比于基线模型,准确率提升了超过10%。此外,实验还表明,极化技术能够解锁SSM,使其能够受益于更深层的架构,从而进一步提高模型的性能。
🎯 应用场景
该研究成果可应用于需要处理长序列依赖关系的各种领域,例如自然语言处理中的长文本理解、语音识别中的长语音建模、以及时间序列分析等。通过缓解SSM的近因偏见和过平滑问题,可以提高模型在这些任务中的性能和鲁棒性,从而带来更准确、可靠的应用。
📄 摘要(原文)
Structured State Space Models (SSMs) have emerged as alternatives to transformers. While SSMs are often regarded as effective in capturing long-sequence dependencies, we rigorously demonstrate that they are inherently limited by strong recency bias. Our empirical studies also reveal that this bias impairs the models' ability to recall distant information and introduces robustness issues. Our scaling experiments then discovered that deeper structures in SSMs can facilitate the learning of long contexts. However, subsequent theoretical analysis reveals that as SSMs increase in depth, they exhibit another inevitable tendency toward over-smoothing, e.g., token representations becoming increasingly indistinguishable. This fundamental dilemma between recency and over-smoothing hinders the scalability of existing SSMs. Inspired by our theoretical findings, we propose to polarize two channels of the state transition matrices in SSMs, setting them to zero and one, respectively, simultaneously addressing recency bias and over-smoothing. Experiments demonstrate that our polarization technique consistently enhances the associative recall accuracy of long-range tokens and unlocks SSMs to benefit further from deeper architectures. All source codes are released at https://github.com/VITA-Group/SSM-Bottleneck.