Toward Information Theoretic Active Inverse Reinforcement Learning
作者: Ondrej Bajgar, Sid William Gould, Rohan Narayan Langford Mitta, Jonathon Liu, Oliver Newcombe, Jack Golden
分类: cs.LG, stat.ML
发布日期: 2024-12-31
备注: NeurIPS 2024 Workshop on Bayesian Decision-making and Uncertainty
💡 一句话要点
提出信息论主动逆强化学习框架,提升人机交互效率
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 逆强化学习 主动学习 信息论 人机交互 奖励函数
📋 核心要点
- 传统逆强化学习依赖大量人工演示,成本高昂,主动逆强化学习旨在降低人工标注成本。
- 论文提出基于信息论的主动逆强化学习方法,通过选择信息量最大的轨迹进行学习,提升效率。
- 通过网格世界实验验证了所提方法在减少人工干预方面的有效性,为更复杂环境应用奠定基础。
📝 摘要(中文)
随着人工智能系统变得越来越自主,使其决策与人类偏好对齐至关重要。在自动驾驶或机器人等领域,手动编写代表这些偏好的奖励函数是不可能的。逆强化学习(IRL)提供了一种有前景的方法,可以从演示中推断未知的奖励。然而,获得人类演示的成本可能很高。主动逆强化学习通过策略性地选择最具信息量的人类演示场景来应对这一挑战,从而减少所需的人力。现有的大多数工作允许一次查询人类在一个状态下的动作,而本文提出并分析了收集更长轨迹的场景。我们提供了一个信息论采集函数,提出了一个有效的近似方案,并通过一组网格世界实验说明了其性能,为未来扩展到更一般的设置奠定了基础。
🔬 方法详解
问题定义:逆强化学习旨在从专家演示中推断出潜在的奖励函数,但获取高质量的专家演示往往需要大量的人工成本。传统的主动逆强化学习方法通常一次只查询一个状态的动作,效率较低,难以充分利用人类提供的上下文信息。因此,如何更有效地利用有限的人工演示,特别是利用轨迹级别的演示,是本文要解决的核心问题。
核心思路:本文的核心思路是基于信息论,选择那些能够最大程度减少奖励函数不确定性的轨迹进行查询。具体来说,通过最大化信息增益(Information Gain)来选择轨迹,即选择那些能够最大程度降低奖励函数后验分布熵的轨迹。这样可以确保每次查询都能获得最有价值的信息,从而更快地学习到准确的奖励函数。
技术框架:整体框架包含以下几个主要步骤:1) 初始化奖励函数的先验分布;2) 根据当前奖励函数的后验分布,计算每个候选轨迹的信息增益;3) 选择信息增益最大的轨迹进行查询,获取人类专家的演示;4) 根据新的演示更新奖励函数的后验分布;5) 重复步骤2-4,直到满足停止条件。其中,奖励函数的后验分布通常采用贝叶斯方法进行更新。
关键创新:本文的关键创新在于提出了一个基于信息论的轨迹选择策略,能够有效地选择信息量最大的轨迹进行查询,从而显著减少了所需的人工演示数量。与传统的主动逆强化学习方法相比,本文的方法能够更好地利用轨迹级别的上下文信息,从而更有效地学习到准确的奖励函数。此外,论文还提出了一个高效的近似方案来计算信息增益,降低了计算复杂度。
关键设计:论文中,信息增益的计算是核心。由于直接计算信息增益通常是困难的,论文提出了一种近似方法。具体来说,论文采用蒙特卡洛方法来估计信息增益,即从当前的奖励函数后验分布中采样多个奖励函数,然后计算每个候选轨迹在这些奖励函数下的期望回报,并根据这些期望回报来估计信息增益。此外,论文还设计了一个高效的采样策略,以减少蒙特卡洛估计的方差。
🖼️ 关键图片
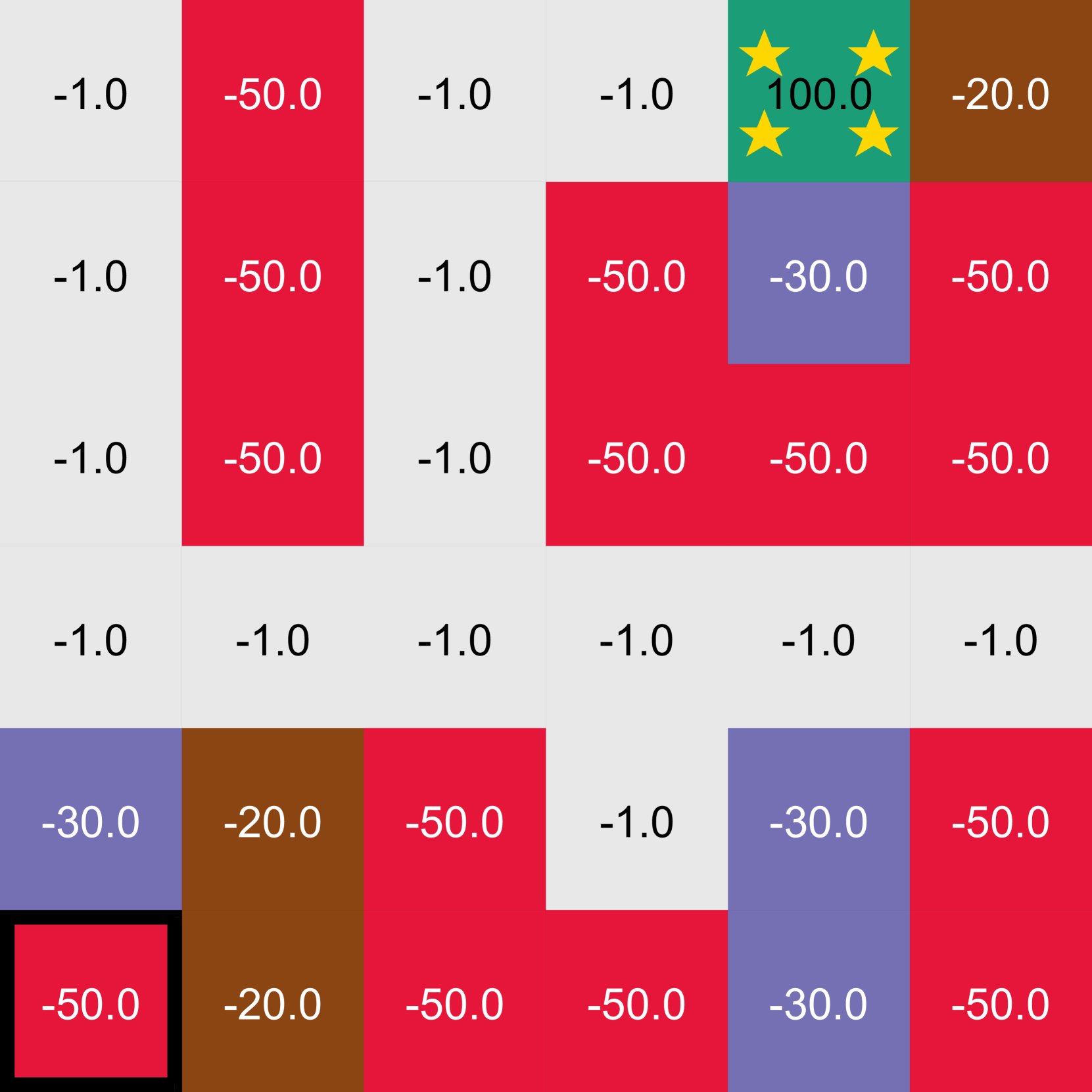
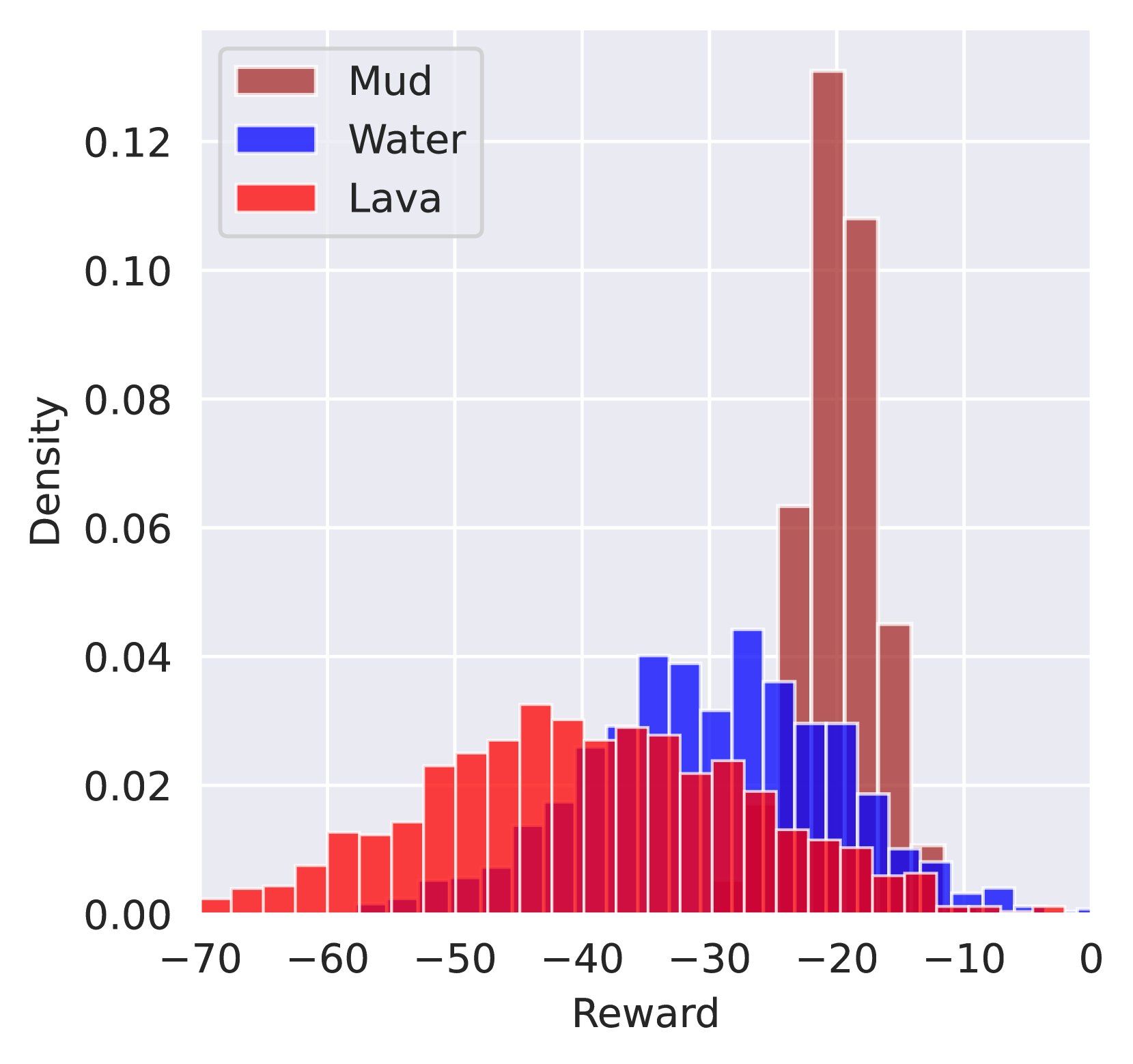
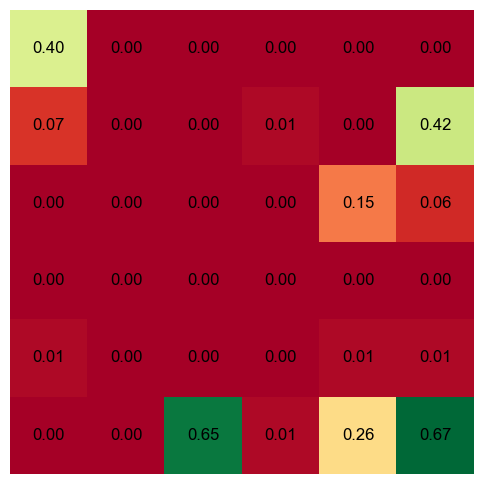
📊 实验亮点
论文通过网格世界实验验证了所提方法的有效性。实验结果表明,与随机选择轨迹的方法相比,基于信息论的主动逆强化学习方法能够显著减少所需的人工演示数量,更快地学习到准确的奖励函数。具体的性能数据未知,但论文强调了其在减少人工干预方面的优势。
🎯 应用场景
该研究成果可应用于各种需要人机协作的自主系统中,例如自动驾驶、机器人导航、智能家居等。通过主动学习人类偏好,系统能够更好地理解人类意图,从而做出更符合人类期望的决策,提高人机交互的效率和安全性。未来,该技术有望在医疗、教育等领域发挥重要作用。
📄 摘要(原文)
As AI systems become increasingly autonomous, aligning their decision-making to human preferences is essential. In domains like autonomous driving or robotics, it is impossible to write down the reward function representing these preferences by hand. Inverse reinforcement learning (IRL) offers a promising approach to infer the unknown reward from demonstrations. However, obtaining human demonstrations can be costly. Active IRL addresses this challenge by strategically selecting the most informative scenarios for human demonstration, reducing the amount of required human effort. Where most prior work allowed querying the human for an action at one state at a time, we motivate and analyse scenarios where we collect longer trajectories. We provide an information-theoretic acquisition function, propose an efficient approximation scheme, and illustrate its performance through a set of gridworld experiments as groundwork for future work expanding to more general settings.