Towards Pattern-aware Data Augmentation for Temporal Knowledge Graph Completion
作者: Jiasheng Zhang, Deqiang Ouyang, Shuang Liang, Jie Shao
分类: cs.LG, cs.DB, cs.IR
发布日期: 2024-12-31
💡 一句话要点
提出Booster,一种模式感知的数据增强方法,用于提升时序知识图谱补全任务性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时序知识图谱 知识图谱补全 数据增强 模型偏好 三元闭包
📋 核心要点
- 现有时序知识图谱补全方法忽略了数据不平衡和模型偏好问题,导致性能下降和误差累积。
- Booster通过分层评分算法和两阶段训练方法,生成符合时序模式的增强样本,并识别模型难学习样本。
- 实验表明,Booster能有效提升现有TKGC模型的性能,最高可达8.7%的性能提升。
📝 摘要(中文)
时序知识图谱补全(TKGC)旨在预测时序知识图谱(TKG)中缺失的事实,是一项基础任务。该任务的关键挑战之一是数据分布不平衡,即事实在实体和时间戳上的分布不均匀。这种不平衡会导致补全性能下降、长尾实体和时间戳问题,以及由于引入错误负样本而导致的不稳定训练。之前的研究很少关注如何缓解这些影响。此外,我们首次发现现有方法存在模型偏好,即具有特定属性(例如,最近活跃)的实体更受不同模型的青睐。这种偏好会导致误差累积,并进一步加剧数据分布不平衡的影响,但之前的研究忽略了这一点。为了减轻数据不平衡和模型偏好的影响,我们提出了Booster,这是第一个用于TKG的数据增强策略。这里的独特要求在于生成符合TKG中复杂语义和时间模式的新样本,并识别特定于模型的难学习样本。因此,我们提出了一种基于TKG内三元闭包的分层评分算法。通过结合全局语义模式和局部时间感知结构,该算法能够对新样本进行模式感知验证。同时,我们提出了一种两阶段训练方法来识别偏离模型首选模式的样本。通过精心设计的基于频率的过滤策略,该方法还有助于避免错误负样本的误导。实验证明,Booster可以无缝地适应现有的TKGC模型,并实现高达8.7%的性能提升。
🔬 方法详解
问题定义:论文旨在解决时序知识图谱补全任务中,由于数据分布不平衡和模型偏好导致的性能下降问题。现有方法未能有效缓解这些问题,导致模型在训练过程中容易受到长尾实体和时间戳的影响,并且容易对特定属性的实体产生偏好,从而导致误差累积。
核心思路:论文的核心思路是提出一种模式感知的数据增强方法Booster,通过生成符合时序知识图谱中复杂语义和时间模式的新样本,并识别模型难以学习的样本,从而缓解数据不平衡和模型偏好带来的负面影响。Booster旨在生成高质量的增强样本,并避免引入错误的负样本。
技术框架:Booster包含两个主要组成部分:1) 基于三元闭包的分层评分算法,用于生成和验证新的增强样本;2) 两阶段训练方法,用于识别偏离模型首选模式的难学习样本。首先,分层评分算法结合全局语义模式和局部时间感知结构,对候选增强样本进行评分,确保生成的样本符合时序知识图谱的模式。然后,两阶段训练方法通过分析模型在不同样本上的表现,识别出模型难以学习的样本,并利用这些样本进行数据增强。
关键创新:Booster的关键创新在于其模式感知的数据增强策略。与传统的数据增强方法不同,Booster能够根据时序知识图谱的复杂语义和时间模式,生成高质量的增强样本。此外,Booster还能够识别模型难以学习的样本,并利用这些样本进行针对性的数据增强,从而提高模型的泛化能力。
关键设计:分层评分算法包含全局语义评分和局部时间感知评分两个部分。全局语义评分基于三元闭包的语义相似性,评估候选样本的语义合理性。局部时间感知评分则考虑了时间序列的局部结构,评估候选样本的时间一致性。两阶段训练方法首先使用原始数据集训练一个初始模型,然后利用该模型识别难学习样本,并使用这些样本进行数据增强。此外,论文还设计了一种基于频率的过滤策略,用于避免错误负样本的误导。
🖼️ 关键图片
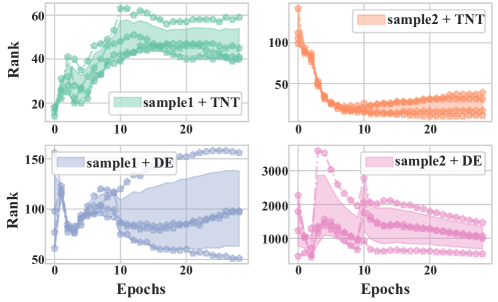
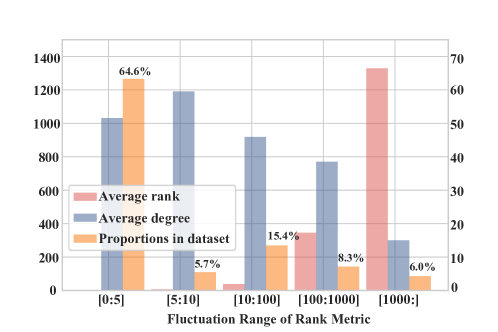
📊 实验亮点
实验结果表明,Booster可以无缝地集成到现有的TKGC模型中,并在多个基准数据集上取得了显著的性能提升。例如,在ICEWS14数据集上,Booster将现有模型的性能提升了高达8.7%。此外,实验还验证了Booster能够有效缓解数据不平衡和模型偏好问题,提高模型的泛化能力。
🎯 应用场景
该研究成果可应用于多种时序知识图谱相关的任务,例如事件预测、关系预测、实体链接等。通过提升时序知识图谱补全的性能,可以为下游应用提供更准确、更全面的知识,从而提高相关应用的性能和可靠性。例如,在金融领域,可以利用该技术预测股票市场的趋势;在医疗领域,可以用于预测疾病的传播路径。
📄 摘要(原文)
Predicting missing facts for temporal knowledge graphs (TKGs) is a fundamental task, called temporal knowledge graph completion (TKGC). One key challenge in this task is the imbalance in data distribution, where facts are unevenly spread across entities and timestamps. This imbalance can lead to poor completion performance or long-tail entities and timestamps, and unstable training due to the introduction of false negative samples. Unfortunately, few previous studies have investigated how to mitigate these effects. Moreover, for the first time, we found that existing methods suffer from model preferences, revealing that entities with specific properties (e.g., recently active) are favored by different models. Such preferences will lead to error accumulation and further exacerbate the effects of imbalanced data distribution, but are overlooked by previous studies. To alleviate the impacts of imbalanced data and model preferences, we introduce Booster, the first data augmentation strategy for TKGs. The unique requirements here lie in generating new samples that fit the complex semantic and temporal patterns within TKGs, and identifying hard-learning samples specific to models. Therefore, we propose a hierarchical scoring algorithm based on triadic closures within TKGs. By incorporating both global semantic patterns and local time-aware structures, the algorithm enables pattern-aware validation for new samples. Meanwhile, we propose a two-stage training approach to identify samples that deviate from the model's preferred patterns. With a well-designed frequency-based filtering strategy, this approach also helps to avoid the misleading of false negatives. Experiments justify that Booster can seamlessly adapt to existing TKGC models and achieve up to an 8.7% performance improvement.