An Unsupervised Anomaly Detection in Electricity Consumption Using Reinforcement Learning and Time Series Forest Based Framework
作者: Jihan Ghanim, Mariette Awad
分类: cs.LG, cs.AI
发布日期: 2024-12-30
💡 一句话要点
提出基于强化学习和时间序列森林的无监督异常检测模型选择框架,提升电力消耗异常检测性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 异常检测 强化学习 时间序列森林 无监督学习 模型选择
📋 核心要点
- 现有异常检测方法依赖特定假设,对特定异常敏感,缺乏通用性。
- 提出结合时间序列森林和强化学习的模型选择框架,动态选择最优异常检测器。
- 实验表明,该方法在真实和合成数据集上均优于其他异常检测模型,包括GPT-4。
📝 摘要(中文)
异常检测在时间序列应用中至关重要,尤其是在实际场景中广泛使用的时间序列数据。由于异常形式多样,准确识别异常极具挑战性。现有研究提出了不同的异常检测模型,但它们都基于特定假设,对特定类型的异常敏感。为了解决这个问题,我们提出了一种新颖的无监督异常检测模型选择方法,该方法结合了时间序列森林(TSF)和强化学习(RL)方法,动态选择合适的异常检测技术。我们的方法无需依赖通常稀缺且昂贵的ground truth标签,即可实现有效的异常检测。在真实时间序列数据集上的结果表明,所提出的模型选择方法在F1 score指标方面优于所有其他异常检测模型。在合成数据集上,我们的模型优于除KNN之外的所有其他异常检测模型,F1 score高达0.989。该模型选择框架的性能也超过了GPT-4在合成数据集上作为异常检测器的表现。对不同奖励函数的探索表明,我们提出的异常检测模型选择方法中的原始奖励函数产生了最佳的总体得分。我们还在另外三个分别具有全局、局部和聚类异常的数据集上评估了六个异常检测模型的性能,结果表明每个异常检测模型都表现出不同的性能,这取决于异常的类型。这强调了我们提出的异常检测模型选择框架的重要性,它在所有数据集上保持高性能,并在不同异常类型上表现出卓越的性能。
🔬 方法详解
问题定义:论文旨在解决电力消耗时间序列数据中无监督异常检测的问题。现有异常检测方法通常针对特定类型的异常设计,难以适应复杂多变的实际场景,且需要大量标注数据,成本高昂。
核心思路:核心思路是利用强化学习训练一个智能体,该智能体能够根据当前时间序列数据的特征,动态选择最适合的异常检测模型。通过这种方式,可以综合利用不同模型的优势,提高异常检测的准确性和鲁棒性,同时避免了对大量标注数据的依赖。
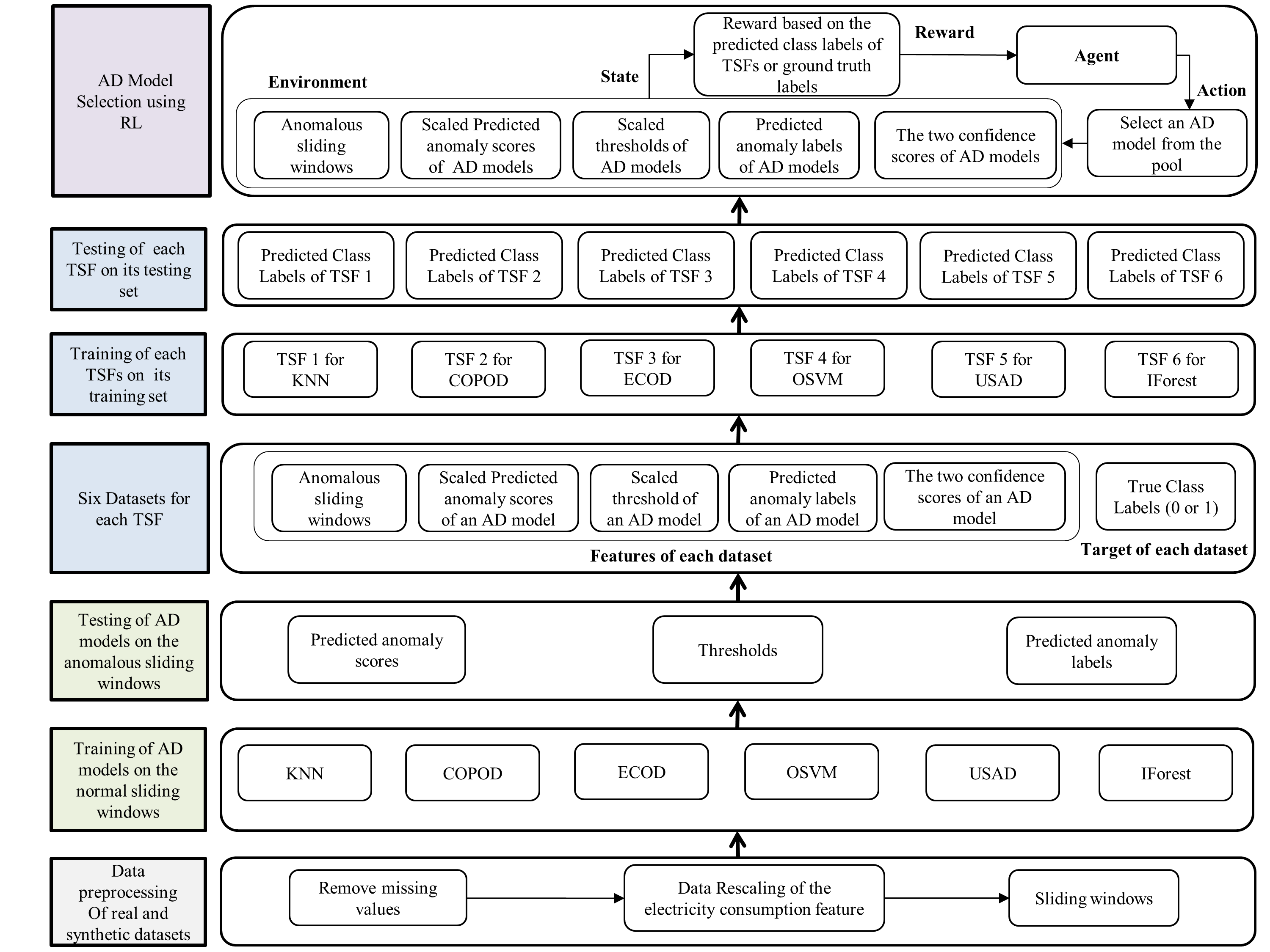
技术框架:整体框架包含以下几个主要模块:1) 时间序列森林(TSF):用于提取时间序列数据的特征,为强化学习智能体提供状态信息。2) 强化学习智能体:基于提取的特征,选择合适的异常检测模型。3) 异常检测模型池:包含多种不同的异常检测算法,例如KNN、Isolation Forest等。4) 奖励函数:用于评估所选模型的性能,并反馈给强化学习智能体,指导其学习。
关键创新:关键创新在于将模型选择问题建模为一个强化学习问题,并利用时间序列森林提取数据特征,从而实现动态、自适应的异常检测。与传统方法相比,该方法无需人工选择模型,能够自动适应不同类型的数据和异常。
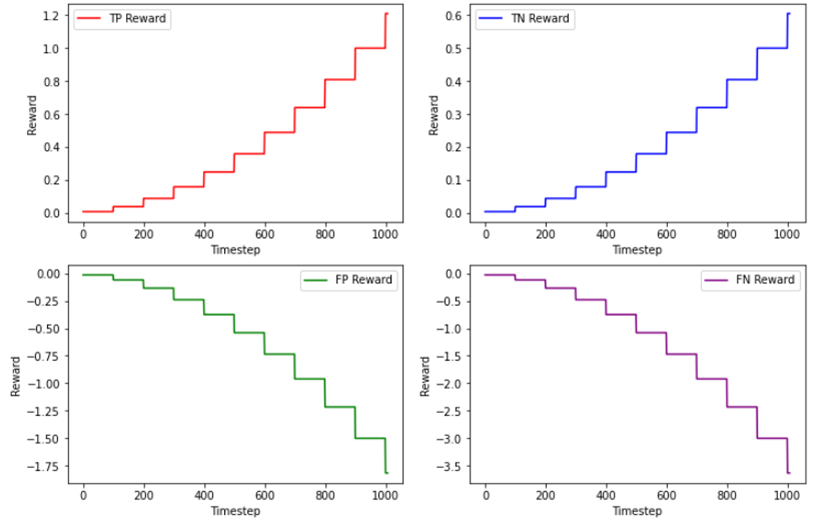
关键设计:奖励函数的设计至关重要,论文探索了不同的奖励函数,最终选择了一种能够有效平衡准确率和召回率的奖励函数。此外,时间序列森林的参数设置以及强化学习智能体的网络结构也需要仔细调整,以获得最佳性能。具体参数设置在论文中未详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
在真实电力消耗数据集上,所提出的模型选择方法在F1 score指标方面优于所有其他异常检测模型。在合成数据集上,该模型优于除KNN之外的所有其他模型,F1 score高达0.989,并且超过了GPT-4作为异常检测器的性能。实验还表明,不同的异常检测模型在不同类型的异常数据上表现各异,进一步验证了模型选择框架的必要性。
🎯 应用场景
该研究成果可应用于智能电网、能源管理、工业控制等领域,通过及时发现电力消耗异常,可以有效预防电力盗窃、设备故障、能源浪费等问题,提高电力系统的安全性和效率,具有重要的经济和社会价值。未来可扩展到其他时间序列数据的异常检测,例如金融欺诈检测、网络安全监控等。
📄 摘要(原文)
Anomaly detection (AD) plays a crucial role in time series applications, primarily because time series data is employed across real-world scenarios. Detecting anomalies poses significant challenges since anomalies take diverse forms making them hard to pinpoint accurately. Previous research has explored different AD models, making specific assumptions with varying sensitivity toward particular anomaly types. To address this issue, we propose a novel model selection for unsupervised AD using a combination of time series forest (TSF) and reinforcement learning (RL) approaches that dynamically chooses an AD technique. Our approach allows for effective AD without explicitly depending on ground truth labels that are often scarce and expensive to obtain. Results from the real-time series dataset demonstrate that the proposed model selection approach outperforms all other AD models in terms of the F1 score metric. For the synthetic dataset, our proposed model surpasses all other AD models except for KNN, with an impressive F1 score of 0.989. The proposed model selection framework also exceeded the performance of GPT-4 when prompted to act as an anomaly detector on the synthetic dataset. Exploring different reward functions revealed that the original reward function in our proposed AD model selection approach yielded the best overall scores. We evaluated the performance of the six AD models on an additional three datasets, having global, local, and clustered anomalies respectively, showing that each AD model exhibited distinct performance depending on the type of anomalies. This emphasizes the significance of our proposed AD model selection framework, maintaining high performance across all datasets, and showcasing superior performance across different anomaly types.