LEASE: Offline Preference-based Reinforcement Learning with High Sample Efficiency
作者: Xiao-Yin Liu, Guotao Li, Xiao-Hu Zhou, Zeng-Guang Hou
分类: cs.LG, cs.AI
发布日期: 2024-12-30 (更新: 2025-11-04)
备注: 17 pages, 5 figures
💡 一句话要点
LEASE:高样本效率的离线偏好强化学习算法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 偏好学习 样本效率 转移模型 不确定性感知
📋 核心要点
- 离线偏好强化学习面临偏好数据获取困难的挑战,人工标注成本高昂且效率低下。
- LEASE算法利用学习到的转移模型生成未标记偏好数据,并引入不确定性感知机制筛选高质量数据。
- 实验结果表明,LEASE在少量偏好数据下即可达到与基线方法相当的性能,无需在线交互。
📝 摘要(中文)
离线偏好强化学习(PbRL)为克服奖励函数设计和在线交互高成本的挑战提供了一种有效途径。然而,由于标记偏好需要实时的人工反馈,获取足够的偏好标签具有挑战性。为了解决这个问题,本文提出了一种具有高样本效率的离线偏好强化学习(LEASE)算法,该算法利用学习到的转移模型来生成未标记的偏好数据。考虑到预训练的奖励模型可能为未标记数据生成不正确的标签,我们设计了一种不确定性感知机制来确保奖励模型的性能,其中只选择高置信度和低方差的数据。此外,我们提供了奖励模型的泛化界限,以分析影响奖励准确性的因素,并证明了LEASE学习到的策略具有理论上的改进保证。所开发的理论基于状态-动作对,可以很容易地与其他离线算法相结合。实验结果表明,在没有在线交互的情况下,LEASE可以在更少的偏好数据下达到与基线相当的性能。
🔬 方法详解
问题定义:离线偏好强化学习(Offline PbRL)旨在利用离线数据集学习策略,避免与环境的在线交互。然而,获取足够数量的偏好标签是关键挑战,因为这通常需要耗时且昂贵的人工标注。现有方法在数据效率方面存在不足,限制了其在实际场景中的应用。
核心思路:LEASE算法的核心思路是利用学习到的转移模型生成大量的未标记偏好数据,从而扩充训练数据集。为了解决生成数据可能存在噪声的问题,引入了不确定性感知机制,只选择置信度高且方差低的样本用于训练,保证奖励模型的准确性。
技术框架:LEASE算法主要包含以下几个阶段:1) 利用离线数据集训练转移模型;2) 使用转移模型生成大量的未标记状态-动作对;3) 使用预训练的奖励模型对生成的数据进行偏好预测;4) 通过不确定性感知机制筛选高质量的偏好数据;5) 利用筛选后的数据训练或微调奖励模型;6) 使用训练好的奖励模型进行策略学习。
关键创新:LEASE算法的关键创新在于:1) 利用转移模型生成未标记偏好数据,显著提高了样本效率;2) 引入不确定性感知机制,有效降低了生成数据噪声对奖励模型的影响;3) 提供了奖励模型的泛化界限,从理论上分析了影响奖励准确性的因素,并证明了算法的改进保证。
关键设计:不确定性感知机制通过计算奖励模型输出的置信度和方差来评估数据的质量。置信度可以使用softmax输出的最大概率值来表示,方差可以通过集成多个奖励模型的输出来估计。算法只选择置信度高于阈值且方差低于阈值的样本。奖励模型的泛化界限分析基于状态-动作对,可以方便地与其他离线算法结合。具体的损失函数和网络结构的选择取决于具体的应用场景。
🖼️ 关键图片


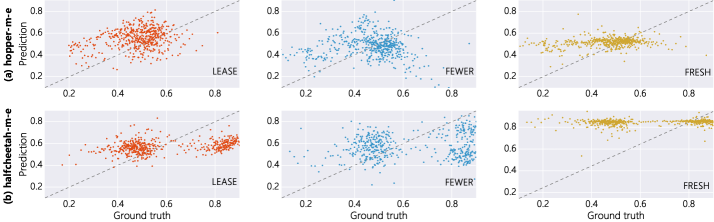
📊 实验亮点
实验结果表明,LEASE算法在更少的偏好数据下,能够达到与基线方法相当的性能。具体而言,在某些任务上,LEASE算法仅使用基线方法一半甚至更少的偏好数据,即可取得相似或更好的结果,显著提高了样本效率,验证了算法的有效性。
🎯 应用场景
LEASE算法可应用于需要人工反馈但获取成本高昂的强化学习场景,例如机器人控制、游戏AI、推荐系统等。通过减少对人工标注数据的依赖,降低了算法的部署成本,加速了算法的落地应用。未来可进一步探索如何更有效地利用生成数据,提升算法的性能和鲁棒性。
📄 摘要(原文)
Offline preference-based reinforcement learning (PbRL) provides an effective way to overcome the challenges of designing reward and the high costs of online interaction. However, since labeling preference needs real-time human feedback, acquiring sufficient preference labels is challenging. To solve this, this paper proposes a offLine prEference-bAsed RL with high Sample Efficiency (LEASE) algorithm, where a learned transition model is leveraged to generate unlabeled preference data. Considering the pretrained reward model may generate incorrect labels for unlabeled data, we design an uncertainty-aware mechanism to ensure the performance of reward model, where only high confidence and low variance data are selected. Moreover, we provide the generalization bound of reward model to analyze the factors influencing reward accuracy, and demonstrate that the policy learned by LEASE has theoretical improvement guarantee. The developed theory is based on state-action pair, which can be easily combined with other offline algorithms. The experimental results show that LEASE can achieve comparable performance to baseline under fewer preference data without online interaction.