Goal-Conditioned Data Augmentation for Offline Reinforcement Learning
作者: Xingshuai Huang, Di Wu, Benoit Boulet
分类: cs.LG, cs.AI, cs.RO
发布日期: 2024-12-29 (更新: 2025-09-02)
💡 一句话要点
提出基于目标条件扩散模型的离线强化学习数据增强方法GODA,提升次优数据集策略学习效果。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 数据增强 扩散模型 目标条件 生成模型 回报导向 交通信号控制
📋 核心要点
- 离线强化学习受限于离线数据集质量,次优数据集难以学习到高质量策略。
- GODA利用目标条件扩散模型,通过回报导向的目标条件和选择机制生成高质量样本。
- 实验表明,GODA在D4RL和交通信号控制任务上,显著提升了数据质量和策略性能。
📝 摘要(中文)
离线强化学习(RL)允许从预先收集的离线数据集中学习策略,从而避免了与环境的直接交互。然而,由于离线数据集质量的限制,它通常无法在次优数据集中学习到高质量的策略。为了解决缺乏足够最优演示的数据集问题,我们引入了目标条件数据增强(GODA),这是一种新颖的基于目标条件扩散的方法,用于增强具有更高质量的样本。利用生成建模的最新进展,GODA结合了一种新颖的面向回报的目标条件和各种选择机制。具体来说,我们引入了一种可控的缩放技术,以在数据采样期间提供增强的基于回报的指导。GODA学习原始离线数据集的全面分布表示,同时生成具有选择性更高回报目标的新数据,从而最大限度地利用有限的最优演示。此外,我们提出了一种新颖的自适应门控条件方法,用于处理嘈杂的输入和条件,从而增强了对面向目标的指导的捕获。我们在D4RL基准和现实世界的挑战,特别是交通信号控制(TSC)任务上进行了实验,以证明GODA在提高数据质量和优于各种离线RL算法的最新数据增强方法方面的有效性。
🔬 方法详解
问题定义:离线强化学习旨在利用预先收集的静态数据集训练策略,无需与环境交互。然而,当数据集质量不高,例如包含大量次优行为时,现有的离线强化学习算法难以学习到高性能的策略。缺乏高质量的样本是主要瓶颈。
核心思路:GODA的核心思路是利用生成模型,特别是扩散模型,来增强离线数据集。通过学习原始数据集的分布,并结合目标条件,生成具有更高回报的样本,从而提升数据集的质量。这种方法旨在弥补原始数据集中最优行为的不足,引导策略学习朝着更好的方向发展。
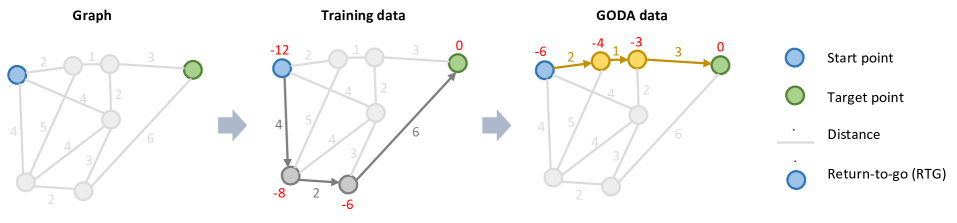
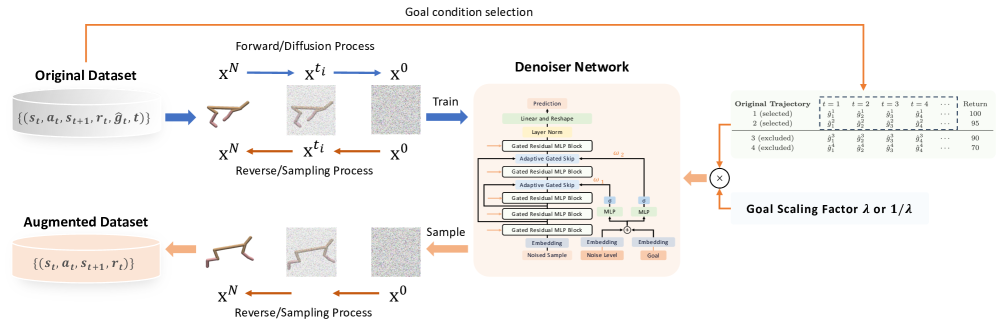
技术框架:GODA的整体框架包含以下几个主要模块:1) 离线数据集:作为输入,包含状态、动作、奖励等信息。2) 目标条件扩散模型:学习离线数据的分布,并根据目标条件生成新的样本。3) 回报导向的目标条件:根据期望的回报值,引导扩散模型生成更高质量的样本。4) 可控缩放技术:调整目标条件的影响程度,平衡生成样本的多样性和质量。5) 自适应门控条件方法:处理噪声输入和条件,提高模型的鲁棒性。
关键创新:GODA的关键创新在于:1) 引入了回报导向的目标条件,直接引导数据生成过程朝着更高回报的方向发展。2) 提出了可控缩放技术,允许灵活地调整目标条件的影响,平衡生成样本的质量和多样性。3) 提出了自适应门控条件方法,增强了模型对噪声的鲁棒性,提高了目标条件指导的有效性。与传统的数据增强方法相比,GODA能够更有效地生成高质量的样本,从而提升离线强化学习的性能。
关键设计:GODA的关键设计包括:1) 扩散模型的选择:可以使用各种扩散模型架构,例如DDPM、DDIM等。2) 目标条件的表示:可以使用期望回报值、未来回报的估计等作为目标条件。3) 可控缩放系数的设置:需要根据具体任务调整缩放系数,以平衡生成样本的质量和多样性。4) 自适应门控机制的设计:可以使用神经网络学习门控系数,根据输入和条件动态调整其影响。
🖼️ 关键图片

📊 实验亮点
实验结果表明,GODA在D4RL基准测试中,相比于现有的数据增强方法,显著提升了离线强化学习算法的性能。例如,在部分任务上,GODA能够将策略的回报提升超过20%。此外,在交通信号控制任务中,GODA也取得了优异的成绩,证明了其在实际应用中的有效性。
🎯 应用场景
GODA具有广泛的应用前景,例如在机器人控制、自动驾驶、推荐系统等领域,可以利用离线数据学习高性能的策略。尤其是在难以进行在线交互或数据收集成本高昂的场景下,GODA能够有效提升离线强化学习的性能,降低开发成本,加速应用落地。未来,GODA可以进一步扩展到更复杂的任务和数据集,例如多智能体强化学习、部分观测马尔可夫决策过程等。
📄 摘要(原文)
Offline reinforcement learning (RL) enables policy learning from pre-collected offline datasets, relaxing the need to interact directly with the environment. However, limited by the quality of offline datasets, it generally fails to learn well-qualified policies in suboptimal datasets. To address datasets with insufficient optimal demonstrations, we introduce Goal-cOnditioned Data Augmentation (GODA), a novel goal-conditioned diffusion-based method for augmenting samples with higher quality. Leveraging recent advancements in generative modelling, GODA incorporates a novel return-oriented goal condition with various selection mechanisms. Specifically, we introduce a controllable scaling technique to provide enhanced return-based guidance during data sampling. GODA learns a comprehensive distribution representation of the original offline datasets while generating new data with selectively higher-return goals, thereby maximizing the utility of limited optimal demonstrations. Furthermore, we propose a novel adaptive gated conditioning method for processing noisy inputs and conditions, enhancing the capture of goal-oriented guidance. We conduct experiments on the D4RL benchmark and real-world challenges, specifically traffic signal control (TSC) tasks, to demonstrate GODA's effectiveness in enhancing data quality and superior performance compared to state-of-the-art data augmentation methods across various offline RL algorithms.