Efficient and Scalable Deep Reinforcement Learning for Mean Field Control Games
作者: Nianli Peng, Yilin Wang
分类: cs.LG, cs.GT, cs.MA
发布日期: 2024-12-28
💡 一句话要点
提出高效可扩展的深度强化学习算法,求解平均场控制博弈问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 平均场控制博弈 深度强化学习 强化学习 Actor-Critic 近端策略优化
📋 核心要点
- 求解高维或复杂环境下的平均场控制博弈(MFCG)均衡解,面临着计算量大的挑战,现有方法难以有效处理。
- 将无限Agent随机控制问题转化为马尔可夫决策过程,并利用深度强化学习算法逼近MFCG均衡解。
- 通过并行采样、小批量处理、PPO等技术,显著提升了算法的效率、可扩展性和训练稳定性,并在线性二次问题上验证了有效性。
📝 摘要(中文)
平均场控制博弈(MFCG)为分析无限多个交互Agent的系统提供了一个强大的理论框架,它融合了平均场博弈(MFG)和平均场控制(MFC)的元素。然而,求解表征MFCG均衡的耦合Hamilton-Jacobi-Bellman和Fokker-Planck方程仍然是一个重大的计算挑战,尤其是在高维或复杂环境中。本文提出了一种可扩展的深度强化学习(RL)方法来近似MFCG的均衡解。在先前工作的基础上,我们将无限Agent的随机控制问题重新表述为一个马尔可夫决策过程,其中每个代表性Agent与不断演变的平均场分布进行交互。我们使用先前论文(Angiuli et.al., 2024)中基于Actor-Critic的算法作为基线,并提出了几个更具可扩展性和效率的算法版本,利用了包括并行样本收集(批处理)、小批量处理、目标网络、近端策略优化(PPO)、广义优势估计(GAE)和熵正则化等技术。通过利用这些技术,我们有效地提高了基线算法的效率、可扩展性和训练稳定性。我们在一个线性二次基准问题上评估了我们的方法,其中MFCG均衡的解析解是可用的。我们的结果表明,我们提出的某些版本的方法实现了更快的收敛,并紧密地逼近了理论最优值,在样本效率方面优于基线算法一个数量级。我们的工作为调整深度强化学习以解决与现实生活密切相关的更复杂的MFCG奠定了基础,例如大规模自动驾驶交通系统、多公司经济竞争和银行间借贷问题。
🔬 方法详解
问题定义:论文旨在解决平均场控制博弈(MFCG)的求解问题,尤其是在高维和复杂环境下,求解耦合的Hamilton-Jacobi-Bellman和Fokker-Planck方程计算量巨大,现有方法难以有效扩展到大规模问题。
核心思路:论文的核心思路是将无限Agent的随机控制问题重新建模为一个马尔可夫决策过程(MDP),其中每个代表性Agent与平均场分布进行交互。通过这种方式,可以将MFCG问题转化为一个可以使用强化学习方法求解的单Agent控制问题。
技术框架:整体框架基于Actor-Critic算法,Agent与环境交互,Actor网络负责策略选择,Critic网络负责评估策略价值。算法流程包括:1) 从环境中采样数据;2) 使用采样数据更新Actor和Critic网络;3) 使用目标网络稳定训练过程。论文在基线算法的基础上,引入了并行采样、小批量处理等技术来提高效率。
关键创新:论文的关键创新在于将深度强化学习技术与平均场控制博弈相结合,并提出了一系列优化方法,包括并行采样、小批量处理、目标网络、近端策略优化(PPO)、广义优势估计(GAE)和熵正则化,显著提高了算法的效率、可扩展性和训练稳定性。
关键设计:论文使用了Actor-Critic网络结构,Actor网络输出Agent的动作,Critic网络评估Agent的价值函数。损失函数包括Actor的策略梯度损失和Critic的均方误差损失。使用了PPO算法来约束策略更新的幅度,防止策略突变。使用了GAE来估计优势函数,减少方差。使用了熵正则化来鼓励探索。
🖼️ 关键图片
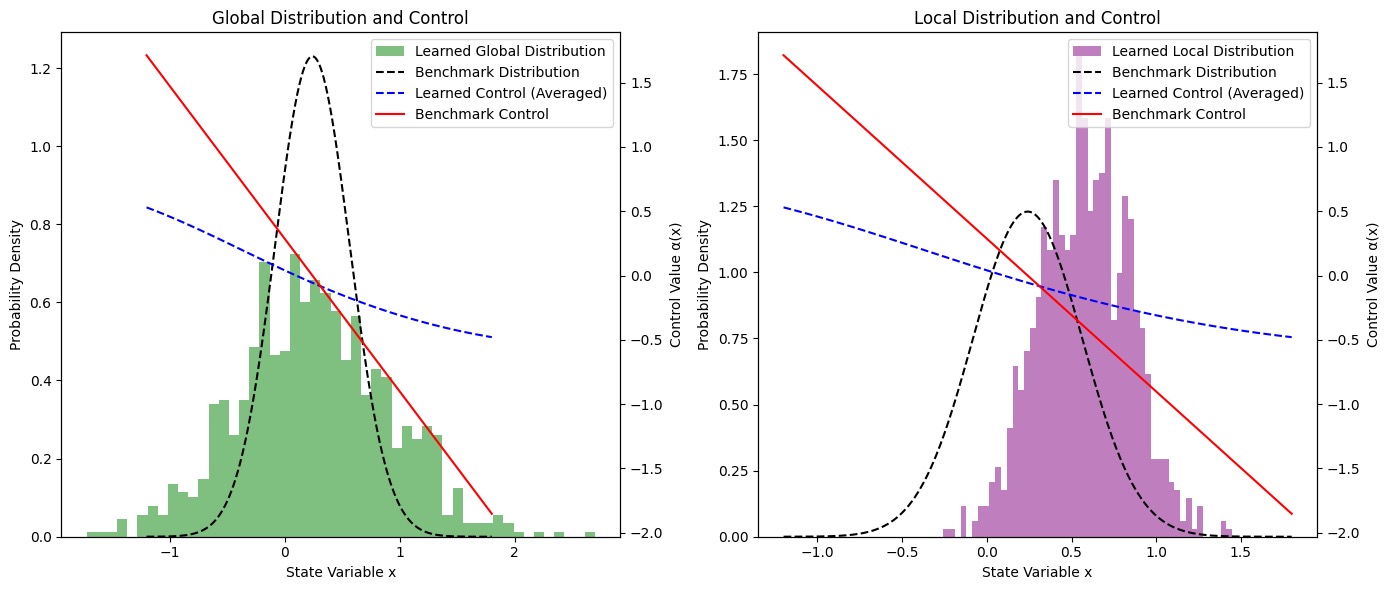
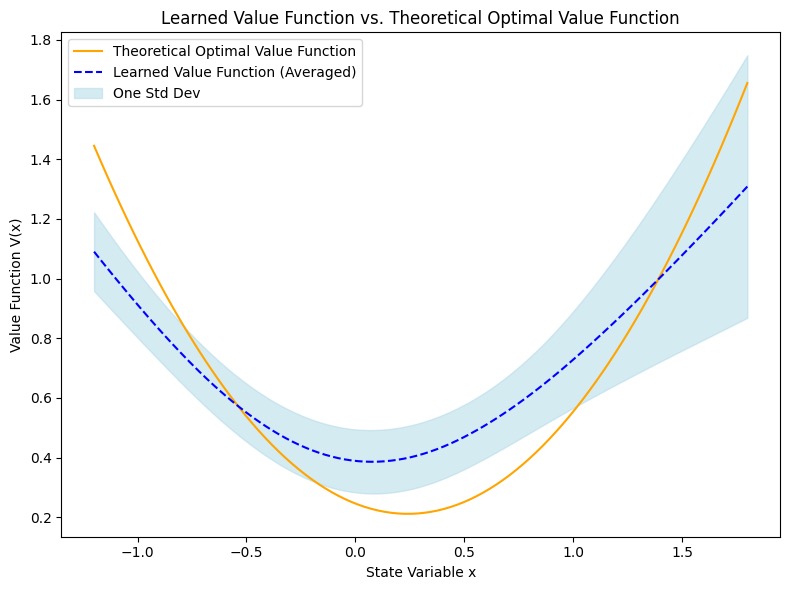
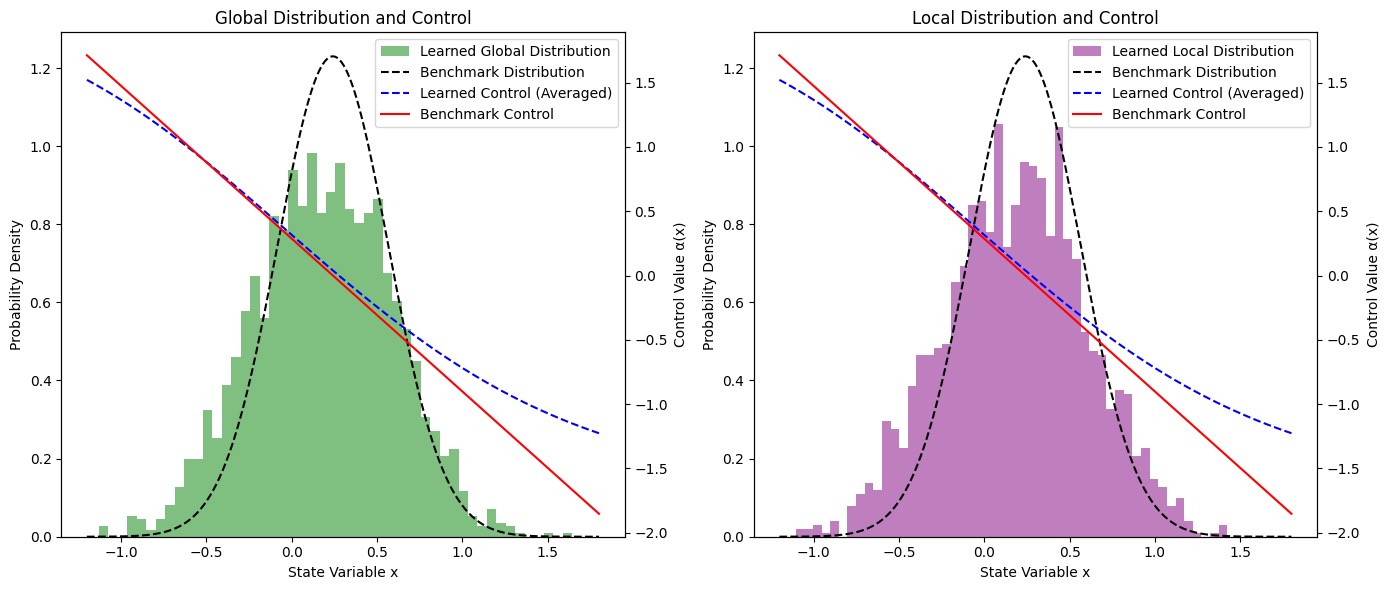
📊 实验亮点
在线性二次基准问题上,论文提出的算法在样本效率方面比基线算法提高了一个数量级,并且能够更紧密地逼近理论最优解。实验结果表明,通过并行采样、小批量处理、PPO等技术,可以显著提高深度强化学习算法在平均场控制博弈问题上的性能。
🎯 应用场景
该研究成果可应用于大规模自主交通系统、多公司经济竞争、银行间借贷等领域。通过对大量交互Agent的建模和控制,可以优化系统性能,提高资源利用率,并为决策者提供更有效的策略。
📄 摘要(原文)
Mean Field Control Games (MFCGs) provide a powerful theoretical framework for analyzing systems of infinitely many interacting agents, blending elements from Mean Field Games (MFGs) and Mean Field Control (MFC). However, solving the coupled Hamilton-Jacobi-Bellman and Fokker-Planck equations that characterize MFCG equilibria remains a significant computational challenge, particularly in high-dimensional or complex environments. This paper presents a scalable deep Reinforcement Learning (RL) approach to approximate equilibrium solutions of MFCGs. Building on previous works, We reformulate the infinite-agent stochastic control problem as a Markov Decision Process, where each representative agent interacts with the evolving mean field distribution. We use the actor-critic based algorithm from a previous paper (Angiuli et.al., 2024) as the baseline and propose several versions of more scalable and efficient algorithms, utilizing techniques including parallel sample collection (batching); mini-batching; target network; proximal policy optimization (PPO); generalized advantage estimation (GAE); and entropy regularization. By leveraging these techniques, we effectively improved the efficiency, scalability, and training stability of the baseline algorithm. We evaluate our method on a linear-quadratic benchmark problem, where an analytical solution to the MFCG equilibrium is available. Our results show that some versions of our proposed approach achieve faster convergence and closely approximate the theoretical optimum, outperforming the baseline algorithm by an order of magnitude in sample efficiency. Our work lays the foundation for adapting deep RL to solve more complicated MFCGs closely related to real life, such as large-scale autonomous transportation systems, multi-firm economic competition, and inter-bank borrowing problems.