Numerical solutions of fixed points in two-dimensional Kuramoto-Sivashinsky equation expedited by reinforcement learning
作者: Juncheng Jiang, Dongdong Wan, Mengqi Zhang
分类: cs.LG
发布日期: 2024-12-27
💡 一句话要点
提出基于强化学习优化的JFNK方法,加速求解二维Kuramoto-Sivashinsky方程的定点
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: Kuramoto-Sivashinsky方程 定点求解 雅可比无矩阵牛顿-克雷洛夫方法 深度强化学习 初始猜测优化
📋 核心要点
- 二维Kuramoto-Sivashinsky方程的定点求解计算量大,传统JFNK方法对初始猜测敏感,收敛性难以保证。
- 利用深度强化学习预先优化JFNK方法的初始猜测,提高其收敛速度和求解效率,并探索系统轨迹控制。
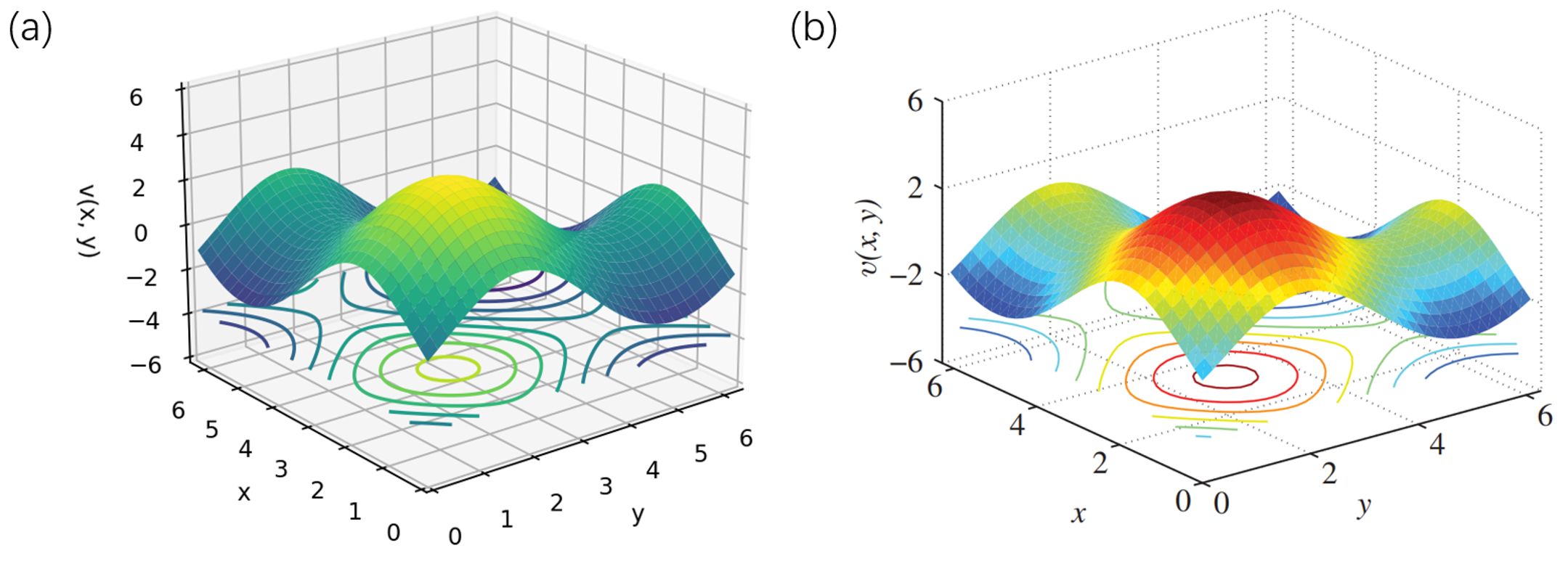
- 实验发现了二维KSE中未被报道的新定点,验证了该组合方法在求解高维动力系统定点问题上的有效性。
📝 摘要(中文)
本文提出了一种结合深度强化学习(DRL)的雅可比无矩阵牛顿-克雷洛夫(JFNK)方法,以提高在二维Kuramoto-Sivashinsky方程(KSE)中识别定点的效率。JFNK方法在寻找定点时,需要一个良好的初始猜测以改善收敛性。通过适当定义的奖励函数,我们利用DRL作为初步步骤来增强收敛过程中的初始猜测。我们报告了二维KSE中尚未在文献中报道的新的定点结果。此外,我们基于并行强化学习技术,探索了二维KSE的控制优化,以导航已知定点之间的系统轨迹。这种组合方法强调了改进的JFNK方法在二维KSE中寻找新的定点解,这可能对其他高维动力系统具有指导意义。
🔬 方法详解
问题定义:论文旨在解决二维Kuramoto-Sivashinsky方程(KSE)定点求解的问题。传统的雅可比无矩阵牛顿-克雷洛夫(JFNK)方法在求解该问题时,对初始猜测非常敏感,如果初始猜测不佳,则可能导致不收敛或收敛速度慢。因此,如何获得一个好的初始猜测是提高JFNK方法效率的关键。
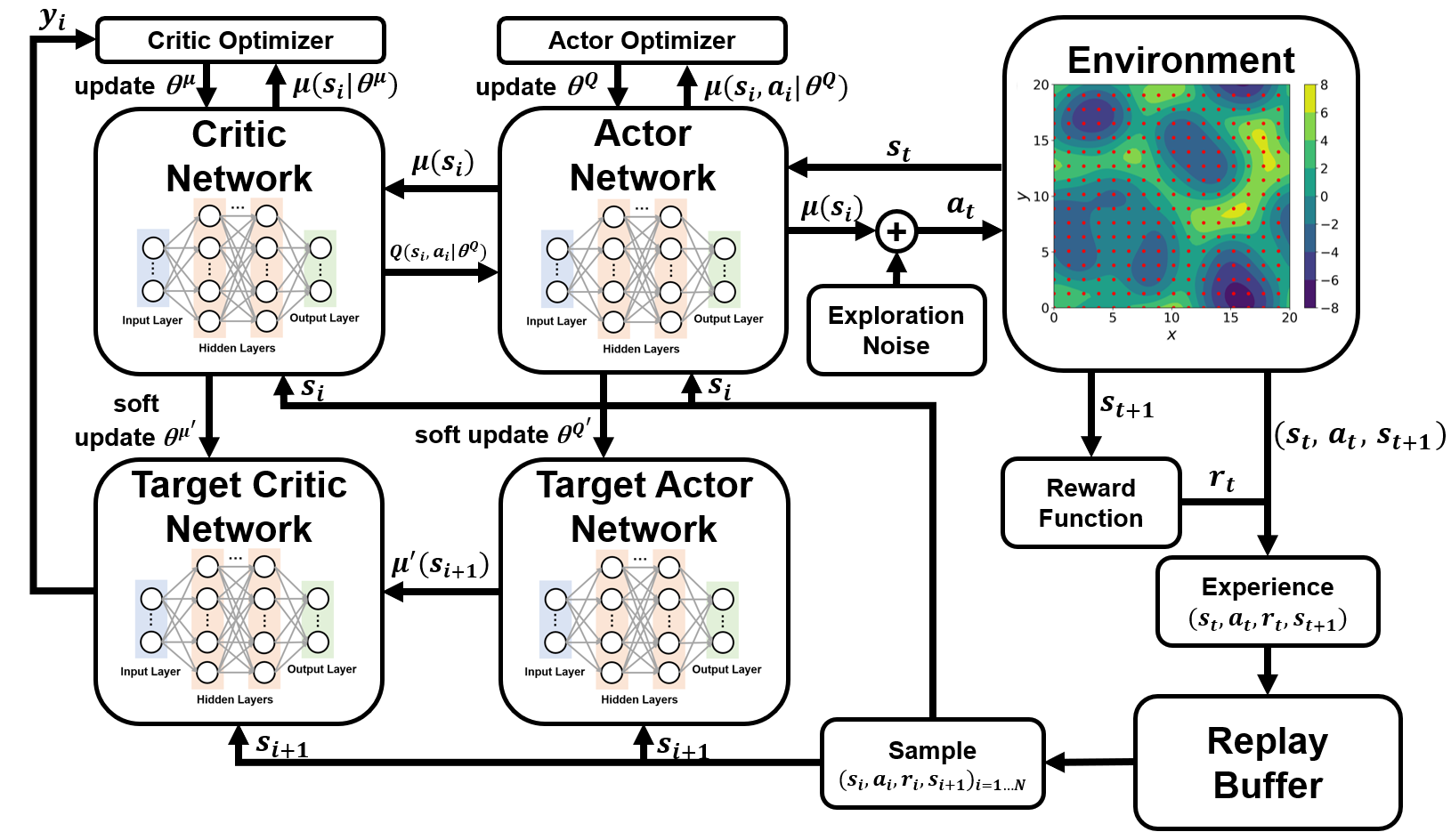
核心思路:论文的核心思路是利用深度强化学习(DRL)来预先优化JFNK方法的初始猜测。通过将求解KSE定点问题建模为一个强化学习任务,训练一个智能体来生成更好的初始猜测,从而提高JFNK方法的收敛速度和求解效率。这种思路的优势在于,DRL可以从数据中学习,自动寻找最优的初始猜测策略,而无需人工设计。
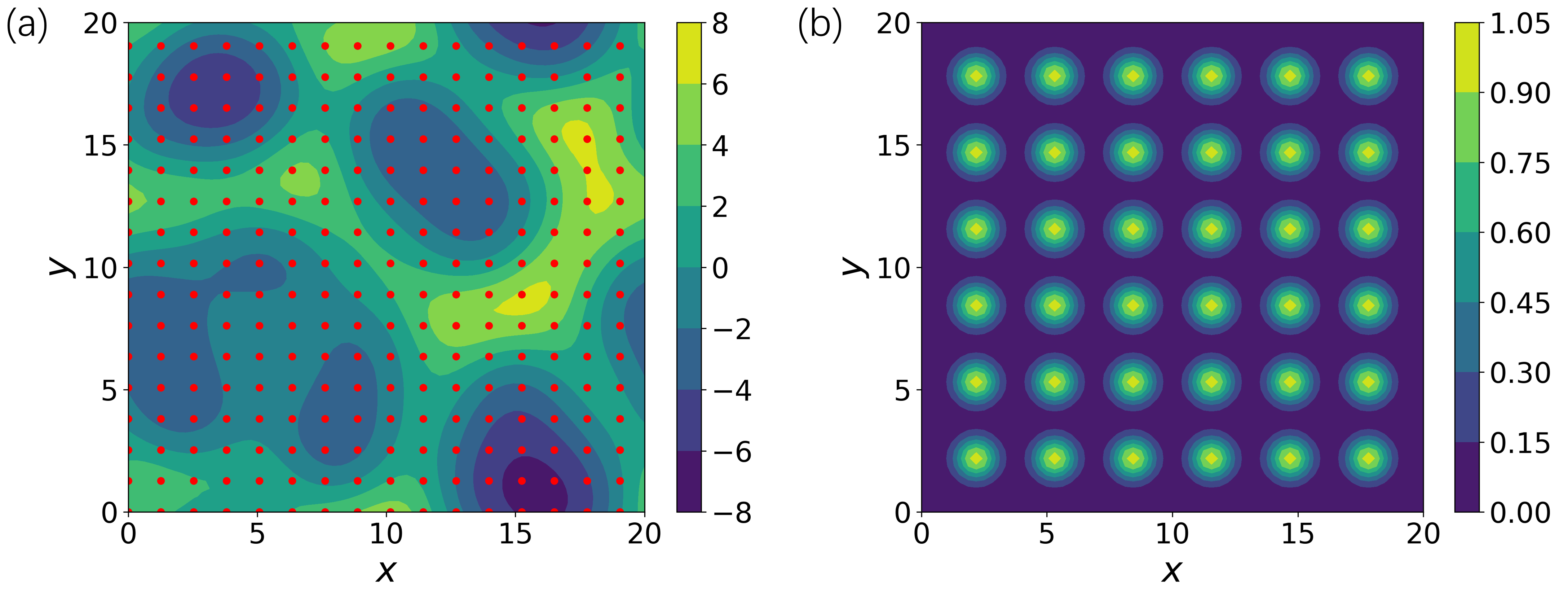
技术框架:整体框架包含两个主要阶段:1) 强化学习阶段:使用DRL训练一个智能体,该智能体以KSE的状态作为输入,输出一个初始猜测。奖励函数的设计至关重要,用于引导智能体学习生成好的初始猜测。2) JFNK求解阶段:使用DRL生成的初始猜测作为JFNK方法的输入,求解KSE的定点。
关键创新:该方法将深度强化学习与传统的数值求解方法JFNK相结合,利用DRL来优化JFNK的初始猜测,从而提高了求解效率。与传统的JFNK方法相比,该方法可以自动学习最优的初始猜测策略,无需人工干预。此外,论文还探索了基于并行强化学习的KSE系统轨迹控制。
关键设计:奖励函数的设计是DRL的关键。论文中奖励函数的设计需要引导智能体生成能够使JFNK方法快速收敛的初始猜测。具体的网络结构和参数设置未知,但通常会采用深度神经网络作为智能体的策略网络,并使用如Actor-Critic等强化学习算法进行训练。并行强化学习技术的具体实现细节也未知。
🖼️ 关键图片
📊 实验亮点
论文报告了二维KSE中未被文献报道的新定点,证明了该方法在发现新的解方面的能力。通过DRL优化初始猜测,JFNK方法的收敛速度和求解效率得到了显著提升,但具体的性能数据和提升幅度未知。此外,论文还探索了基于并行强化学习的KSE系统轨迹控制,为复杂系统的控制提供了一种新的思路。
🎯 应用场景
该研究成果可应用于流体力学、等离子体物理等领域中复杂非线性偏微分方程的定点求解和控制问题。通过结合强化学习和传统数值方法,可以更高效地分析和控制这些复杂系统,例如在湍流控制、等离子体约束等方面具有潜在应用价值。
📄 摘要(原文)
This paper presents a combined approach to enhancing the effectiveness of Jacobian-Free Newton-Krylov (JFNK) method by deep reinforcement learning (DRL) in identifying fixed points within the 2D Kuramoto-Sivashinsky Equation (KSE). JFNK approach entails a good initial guess for improved convergence when searching for fixed points. With a properly defined reward function, we utilise DRL as a preliminary step to enhance the initial guess in the converging process. We report new results of fixed points in the 2D KSE which have not been reported in the literature. Additionally, we explored control optimization for the 2D KSE to navigate the system trajectories between known fixed points, based on parallel reinforcement learning techniques. This combined method underscores the improved JFNK approach to finding new fixed-point solutions within the context of 2D KSE, which may be instructive for other high-dimensional dynamical systems.