Graph-attention-based Casual Discovery with Trust Region-navigated Clipping Policy Optimization
作者: Shixuan Liu, Yanghe Feng, Keyu Wu, Guangquan Cheng, Jincai Huang, Zhong Liu
分类: cs.LG, cs.AI
发布日期: 2024-12-27
DOI: 10.1109/TCYB.2021.3116762
💡 一句话要点
提出基于图注意力的因果发现方法,通过信任域引导的裁剪策略优化提升性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 因果发现 强化学习 图注意力网络 策略优化 信任域 裁剪策略 因果图结构学习
📋 核心要点
- 传统因果发现方法易受无向边和潜在假设违反的影响,强化学习方法如REINFORCE存在局部收敛和训练不稳定问题。
- 提出信任域引导的裁剪策略优化方法,提升搜索效率和策略优化稳定性,并设计SDGAT图注意力编码器以更有效地编码变量。
- 实验结果表明,该方法在合成数据集和基准数据集上,相比于REINFORCE和PPO等方法,在输出结果和优化鲁棒性方面均有提升。
📝 摘要(中文)
在许多经验科学领域中,发现变量之间的因果结构仍然是一项不可或缺的任务。最近,为了解决传统方法中存在的无向边或潜在假设违反问题,研究人员将因果发现形式化为一个强化学习(RL)过程,并配备REINFORCE算法来搜索最佳奖励的有向无环图。该过程整体性能的两个关键是RL方法的鲁棒性和变量的有效编码。然而,一方面,REINFORCE容易出现局部收敛和训练期间的不稳定性能。信任域策略优化虽然计算成本高昂,但近端策略优化(PPO)存在聚合约束偏差,都不是具有相当大的个体子动作的组合优化问题的理想替代方案。我们提出了一种用于因果发现的信任域引导的裁剪策略优化方法,与REINFORCE、PPO和我们优先采样引导的REINFORCE实现相比,该方法保证了更好的搜索效率和策略优化中的稳定性。另一方面,为了提高变量的有效编码,我们提出了一种改进的图注意力编码器,称为SDGAT,它可以掌握更多的特征信息而无需先验邻域信息。通过这些改进,所提出的方法在合成数据集和基准数据集上的输出结果和优化鲁棒性方面均优于之前的RL方法。
🔬 方法详解
问题定义:论文旨在解决因果发现中,传统方法对无向边和潜在假设的敏感性,以及现有强化学习方法(如REINFORCE)在训练过程中易收敛于局部最优和性能不稳定的问题。现有方法在变量编码效率方面也存在提升空间。
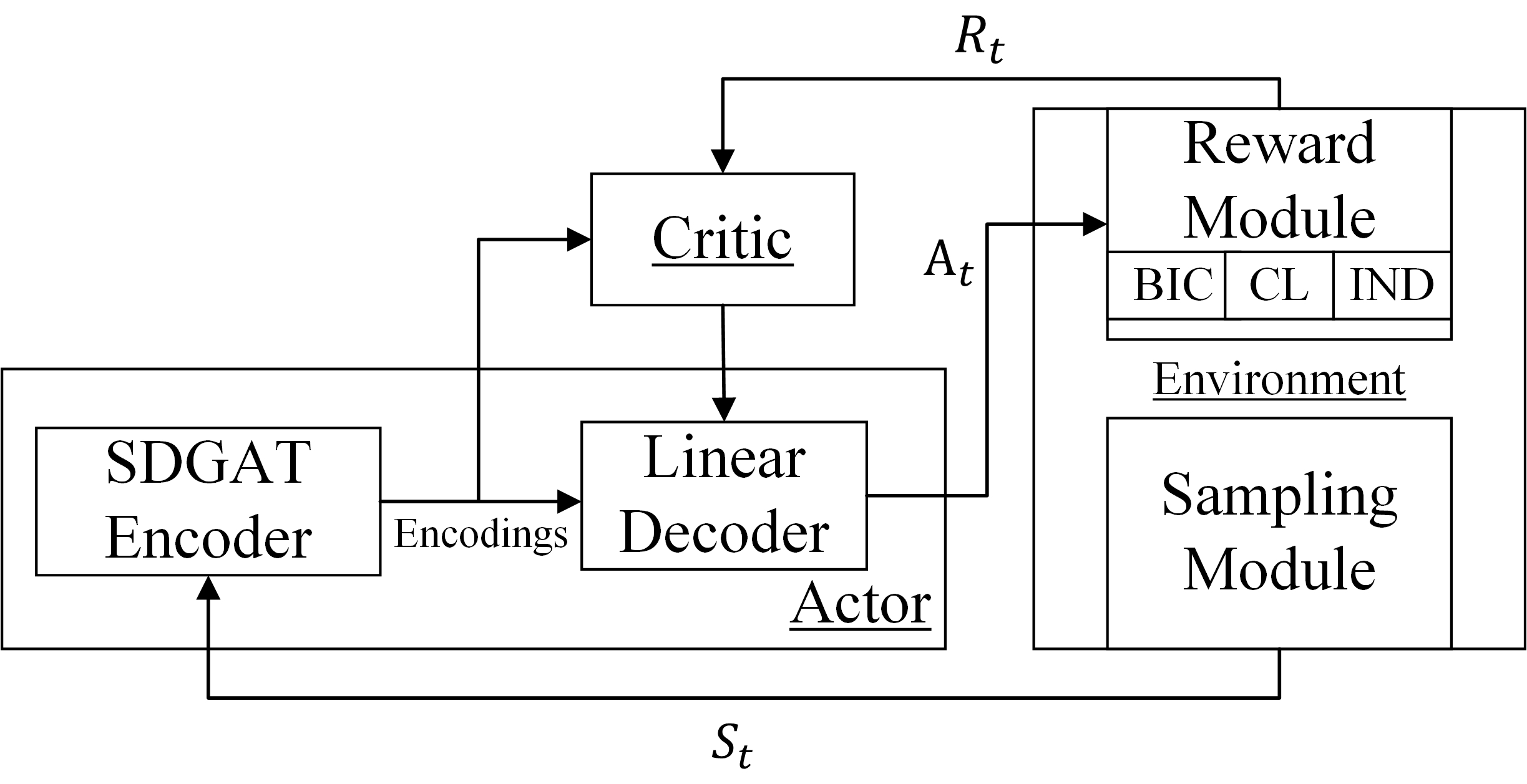
核心思路:论文的核心思路是结合信任域策略优化和裁剪策略优化,提出一种新的强化学习方法,以提高因果结构搜索的效率和稳定性。同时,设计一种改进的图注意力网络(SDGAT)来更有效地编码变量特征,从而提升因果发现的准确性。
技术框架:整体框架包含两个主要部分:一是基于信任域引导的裁剪策略优化算法,用于学习因果图结构;二是SDGAT图注意力编码器,用于提取变量的特征表示。算法首先使用SDGAT编码变量,然后利用强化学习策略选择边的操作,并根据环境反馈(奖励)更新策略。信任域和裁剪机制用于约束策略更新,保证训练的稳定性和效率。
关键创新:论文的关键创新在于:1) 提出了一种信任域引导的裁剪策略优化方法,克服了REINFORCE的局部收敛问题和PPO的聚合约束偏差问题,实现了更稳定和高效的策略学习。2) 设计了SDGAT图注意力编码器,无需先验邻域信息即可有效提取变量特征,提升了变量编码的效率。
关键设计:信任域引导的裁剪策略优化方法结合了信任域优化和裁剪优化的优点,通过信任域约束保证策略更新的幅度,避免过大的更新导致性能下降,同时利用裁剪机制限制策略更新的范围,防止策略过于激进。SDGAT编码器在图注意力网络的基础上进行了改进,具体的技术细节(如注意力机制的计算方式、网络层数等)未知。
🖼️ 关键图片


📊 实验亮点
论文通过在合成数据集和基准数据集上的实验,验证了所提出方法的有效性。实验结果表明,相比于REINFORCE和PPO等基线方法,该方法在因果发现的准确性和优化鲁棒性方面均有显著提升。具体的性能数据和提升幅度未知。
🎯 应用场景
该研究成果可应用于多个领域,包括但不限于:基因调控网络推断、社交网络因果关系分析、经济学因果模型构建等。通过更准确地发现变量之间的因果关系,可以为决策提供更可靠的依据,并促进相关领域的科学研究和应用。
📄 摘要(原文)
In many domains of empirical sciences, discovering the causal structure within variables remains an indispensable task. Recently, to tackle with unoriented edges or latent assumptions violation suffered by conventional methods, researchers formulated a reinforcement learning (RL) procedure for causal discovery, and equipped REINFORCE algorithm to search for the best-rewarded directed acyclic graph. The two keys to the overall performance of the procedure are the robustness of RL methods and the efficient encoding of variables. However, on the one hand, REINFORCE is prone to local convergence and unstable performance during training. Neither trust region policy optimization, being computationally-expensive, nor proximal policy optimization (PPO), suffering from aggregate constraint deviation, is decent alternative for combinatory optimization problems with considerable individual subactions. We propose a trust region-navigated clipping policy optimization method for causal discovery that guarantees both better search efficiency and steadiness in policy optimization, in comparison with REINFORCE, PPO and our prioritized sampling-guided REINFORCE implementation. On the other hand, to boost the efficient encoding of variables, we propose a refined graph attention encoder called SDGAT that can grasp more feature information without priori neighbourhood information. With these improvements, the proposed method outperforms former RL method in both synthetic and benchmark datasets in terms of output results and optimization robustness.