On the Expressiveness and Length Generalization of Selective State-Space Models on Regular Languages
作者: Aleksandar Terzić, Michael Hersche, Giacomo Camposampiero, Thomas Hofmann, Abu Sebastian, Abbas Rahimi
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-12-26 (更新: 2025-07-04)
备注: 13 pages, 7 figures, Published in AAAI 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出选择性稠密状态空间模型(SD-SSM),实现正则语言任务上的完美长度泛化。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 状态空间模型 正则语言 长度泛化 有限状态自动机 序列建模
📋 核心要点
- 现有选择性状态空间模型(SSM)在长度泛化能力方面存在局限性,尤其是在处理复杂正则语言时。
- 论文提出选择性稠密状态空间模型(SD-SSM),利用稠密转移矩阵字典和softmax选择机制,实现动态的状态转移。
- 实验表明,SD-SSM在多种正则语言任务上实现了完美的长度泛化,优于现有的对角选择性SSM变体。
📝 摘要(中文)
选择性状态空间模型(SSM)作为Transformer的新兴替代方案,具有并行训练和顺序推理的独特优势。尽管这些模型在各种任务中表现出良好的性能,但其形式表达能力和长度泛化特性仍未得到充分探索。本文通过分析选择性SSM在正则语言任务(即有限状态自动机(FSA)仿真)上的表达能力和长度泛化性能,深入了解其工作原理。我们通过引入选择性稠密状态空间模型(SD-SSM)来解决现代基于SSM的架构的某些局限性,这是第一个在各种正则语言任务集上使用单层展示完美长度泛化的选择性SSM。它利用稠密转移矩阵字典、softmax选择机制(在每个时间步创建字典矩阵的凸组合)以及由层归一化和线性映射组成的读出层。然后,我们通过考虑对换和非对换自动机的经验性能来评估对角选择性SSM的变体。我们用理论考虑解释了实验结果。代码可在https://github.com/IBM/selective-dense-state-space-model获取。
🔬 方法详解
问题定义:现有的选择性状态空间模型(SSM)在处理正则语言任务时,尤其是在需要长度泛化的情况下,表现出一定的局限性。传统的SSM,特别是对角SSM,可能无法充分捕捉复杂的状态转移模式,导致在不同长度的序列上性能下降。因此,如何设计一种能够有效学习和泛化正则语言的SSM架构是一个关键问题。
核心思路:论文的核心思路是引入稠密转移矩阵字典,并使用softmax选择机制动态地组合这些矩阵。这种方法允许模型在每个时间步选择最合适的转移矩阵组合,从而更好地适应不同的状态转移模式。通过学习一组丰富的转移矩阵,模型能够更灵活地表示复杂的正则语言,并实现更好的长度泛化能力。
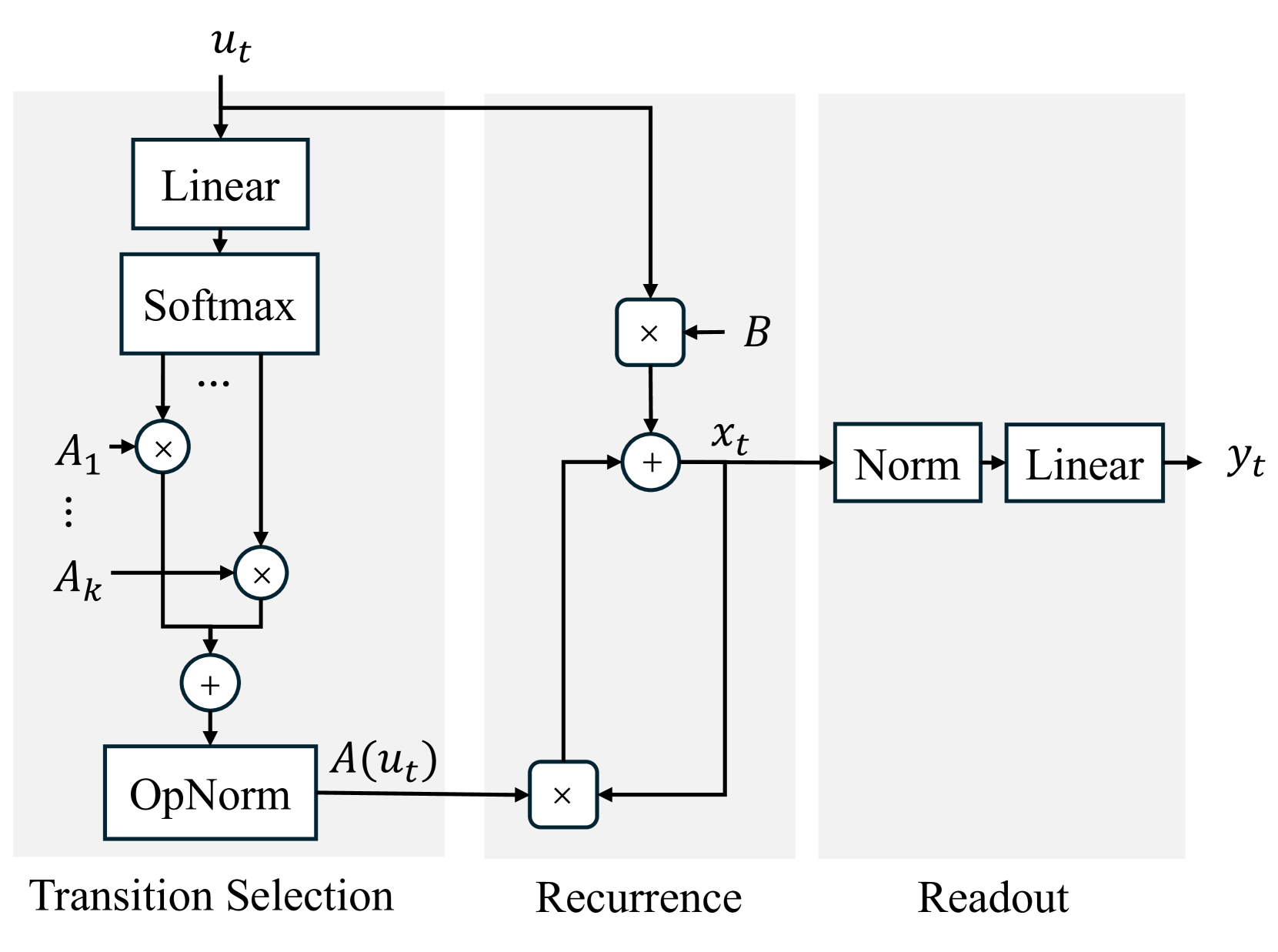
技术框架:SD-SSM模型的整体架构包括以下几个主要模块:1) 稠密转移矩阵字典:存储一组预定义的稠密转移矩阵。2) Softmax选择机制:根据输入序列,使用softmax函数计算每个转移矩阵的权重,生成一个凸组合。3) 状态更新:使用加权后的转移矩阵更新状态向量。4) 读出层:包含层归一化和线性映射,将状态向量映射到输出。整个流程是端到端可训练的。
关键创新:SD-SSM的关键创新在于使用稠密转移矩阵字典和softmax选择机制。与传统的对角SSM相比,SD-SSM能够学习更丰富的状态转移模式,从而更好地捕捉正则语言的复杂性。此外,softmax选择机制允许模型在每个时间步动态地调整状态转移,从而提高了模型的灵活性和适应性。
关键设计:SD-SSM的关键设计包括:1) 稠密转移矩阵字典的大小:需要根据任务的复杂性进行调整。2) Softmax选择机制的温度参数:控制选择的锐度。3) 读出层的层归一化:有助于稳定训练过程。4) 损失函数:使用交叉熵损失函数来训练模型,目标是正确预测每个时间步的输出符号。
🖼️ 关键图片


📊 实验亮点
实验结果表明,SD-SSM在多种正则语言任务上实现了完美的长度泛化,即在训练集长度之外的序列上也能保持高性能。相比于对角选择性SSM,SD-SSM在处理非交换自动机等复杂任务时表现出显著优势,验证了其在学习复杂状态转移模式方面的有效性。
🎯 应用场景
该研究成果可应用于序列建模、自然语言处理等领域,尤其是在需要处理具有复杂状态转移模式的任务中,例如语音识别、机器翻译和生物序列分析。SD-SSM的完美长度泛化能力使其在处理变长序列时具有优势,有望提升相关应用的性能和鲁棒性。
📄 摘要(原文)
Selective state-space models (SSMs) are an emerging alternative to the Transformer, offering the unique advantage of parallel training and sequential inference. Although these models have shown promising performance on a variety of tasks, their formal expressiveness and length generalization properties remain underexplored. In this work, we provide insight into the workings of selective SSMs by analyzing their expressiveness and length generalization performance on regular language tasks, i.e., finite-state automaton (FSA) emulation. We address certain limitations of modern SSM-based architectures by introducing the Selective Dense State-Space Model (SD-SSM), the first selective SSM that exhibits perfect length generalization on a set of various regular language tasks using a single layer. It utilizes a dictionary of dense transition matrices, a softmax selection mechanism that creates a convex combination of dictionary matrices at each time step, and a readout consisting of layer normalization followed by a linear map. We then proceed to evaluate variants of diagonal selective SSMs by considering their empirical performance on commutative and non-commutative automata. We explain the experimental results with theoretical considerations. Our code is available at https://github.com/IBM/selective-dense-state-space-model.