RAG with Differential Privacy
作者: Nicolas Grislain
分类: cs.LG, cs.AI, cs.CR
发布日期: 2024-12-26 (更新: 2025-01-22)
💡 一句话要点
提出基于差分隐私的RAG方法,解决LLM在知识库中暴露隐私数据的问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 差分隐私 大型语言模型 隐私保护 知识库
📋 核心要点
- RAG方法在提升LLM性能的同时,面临暴露文档中隐私数据的风险,现有方法难以保证生成内容不泄露隐私。
- 论文提出差分隐私token生成方法,旨在RAG过程中保护用户隐私,避免LLM无意泄露敏感信息。
- 论文探索了差分隐私token生成在私有RAG中的可行性,为通用知识提取提供了一种潜在的隐私保护方案,具体性能提升未知。
📝 摘要(中文)
检索增强生成(RAG)已成为主流技术,为大型语言模型(LLM)提供最新和相关的上下文,从而减轻幻觉风险并提高在大型和快速移动的知识库中响应的整体质量。然而,将外部文档集成到生成过程中会引发重大的隐私问题。事实上,当添加到提示中时,无法保证响应不会无意中暴露机密数据,从而导致潜在的隐私泄露和伦理困境。本文探讨了一种适用于从个人数据中进行通用知识提取的实用解决方案。它表明,差分隐私token生成是私有RAG的可行方法。
🔬 方法详解
问题定义:论文旨在解决检索增强生成(RAG)框架下,大型语言模型(LLM)在利用外部知识库生成文本时可能泄露隐私数据的问题。现有的RAG方法无法保证生成的文本不包含敏感信息,存在潜在的隐私泄露风险,尤其是在处理包含个人数据的知识库时。
核心思路:论文的核心思路是引入差分隐私(Differential Privacy, DP)机制到token生成过程中。通过在生成token时添加噪声,使得即使攻击者获得了LLM的输出,也难以推断出原始知识库中的敏感信息。这种方法旨在在保证LLM生成质量的同时,提供可证明的隐私保护。
技术框架:论文提出的技术框架主要包含以下几个阶段:1) 检索阶段:从知识库中检索与用户查询相关的文档。2) 增强阶段:将检索到的文档作为上下文添加到用户查询中,形成新的prompt。3) 生成阶段:LLM基于prompt生成文本,关键在于此阶段引入差分隐私机制,对token生成过程进行扰动。4) 输出阶段:输出经过隐私保护的生成文本。
关键创新:论文的关键创新在于将差分隐私应用于RAG框架的token生成过程。与传统的隐私保护方法(如数据脱敏)相比,差分隐私提供了一种更强的隐私保证,即无论攻击者拥有多少背景知识,都无法确定某个特定数据是否被用于生成文本。
关键设计:论文的关键设计在于如何将差分隐私有效地融入到token生成过程中,具体的技术细节未知。可能涉及对LLM的输出概率分布进行扰动,或者在token选择过程中引入噪声。具体的参数设置、损失函数和网络结构等细节需要在论文中进一步查找。
🖼️ 关键图片
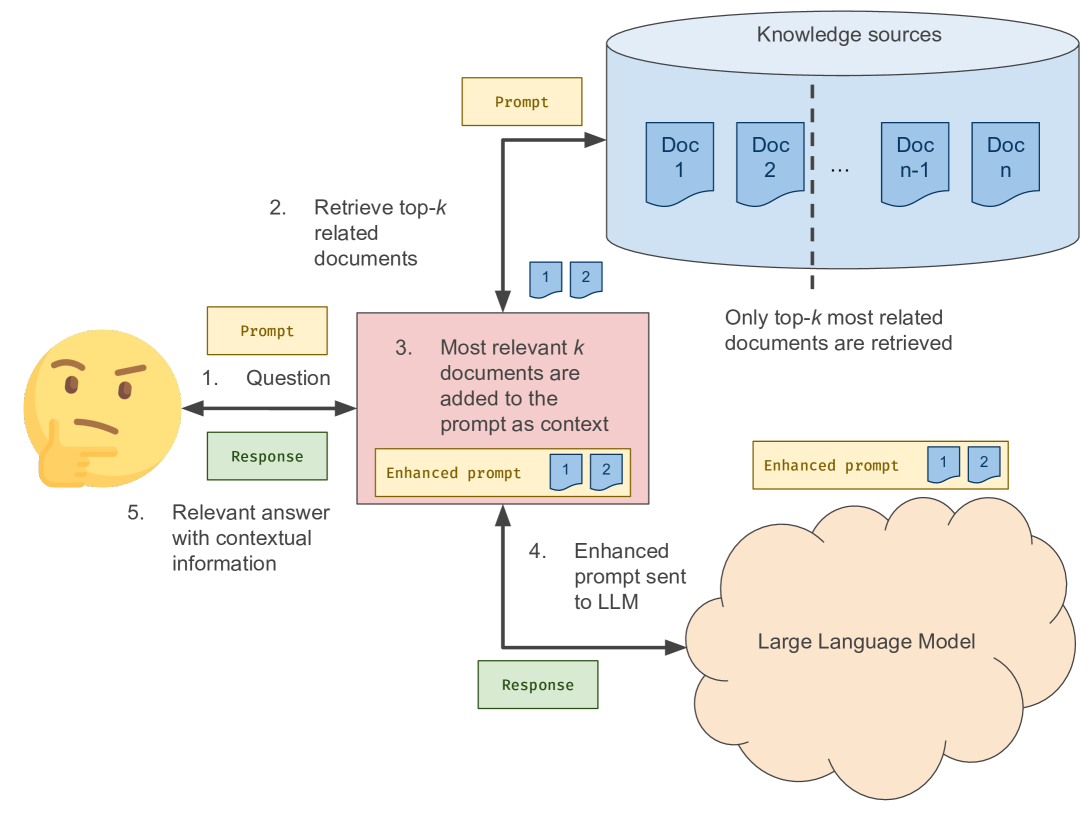

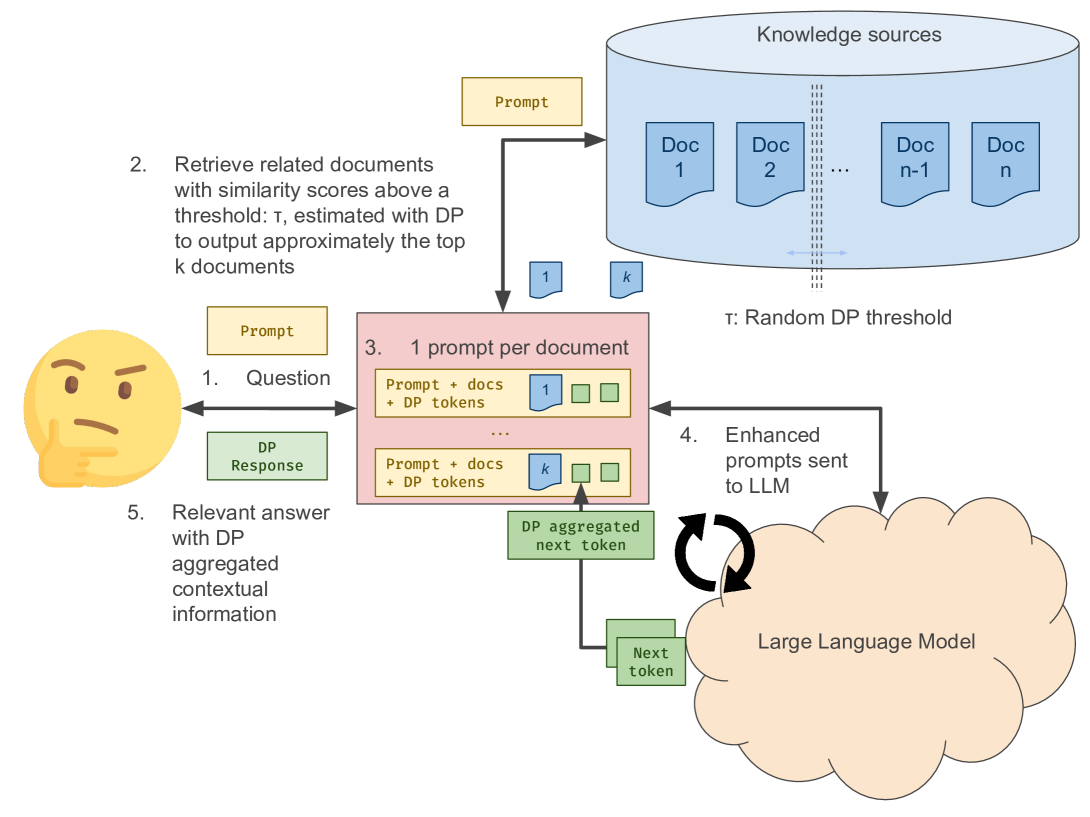
📊 实验亮点
由于论文摘要信息有限,无法提取具体的实验结果和性能数据。摘要仅表明该方法是私有RAG的可行方案,具体的性能提升和对比基线未知,需要在论文中进一步查找。
🎯 应用场景
该研究成果可应用于医疗、金融、法律等对数据隐私要求极高的领域。例如,在医疗问答系统中,可以利用该方法保护患者的病历信息;在金融领域,可以保护用户的交易记录和个人财务信息。该研究有助于推动LLM在隐私敏感场景下的应用,并促进负责任的人工智能发展。
📄 摘要(原文)
Retrieval-Augmented Generation (RAG) has emerged as the dominant technique to provide \emph{Large Language Models} (LLM) with fresh and relevant context, mitigating the risk of hallucinations and improving the overall quality of responses in environments with large and fast moving knowledge bases. However, the integration of external documents into the generation process raises significant privacy concerns. Indeed, when added to a prompt, it is not possible to guarantee a response will not inadvertently expose confidential data, leading to potential breaches of privacy and ethical dilemmas. This paper explores a practical solution to this problem suitable to general knowledge extraction from personal data. It shows \emph{differentially private token generation} is a viable approach to private RAG.