Constraint-Adaptive Policy Switching for Offline Safe Reinforcement Learning
作者: Yassine Chemingui, Aryan Deshwal, Honghao Wei, Alan Fern, Janardhan Rao Doppa
分类: cs.LG, cs.AI
发布日期: 2024-12-25 (更新: 2025-05-27)
备注: Published in Proceedings of the AAAI Conference on Artificial Intelligence, 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出约束自适应策略切换(CAPS)框架,解决离线安全强化学习中约束变化适应问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 安全强化学习 策略切换 约束自适应 奖励-成本权衡
📋 核心要点
- 现有离线安全强化学习方法难以适应部署时变化的安全约束,需要重新训练。
- CAPS框架通过学习多个具有不同奖励-成本权衡的策略,实现在线策略切换以适应约束变化。
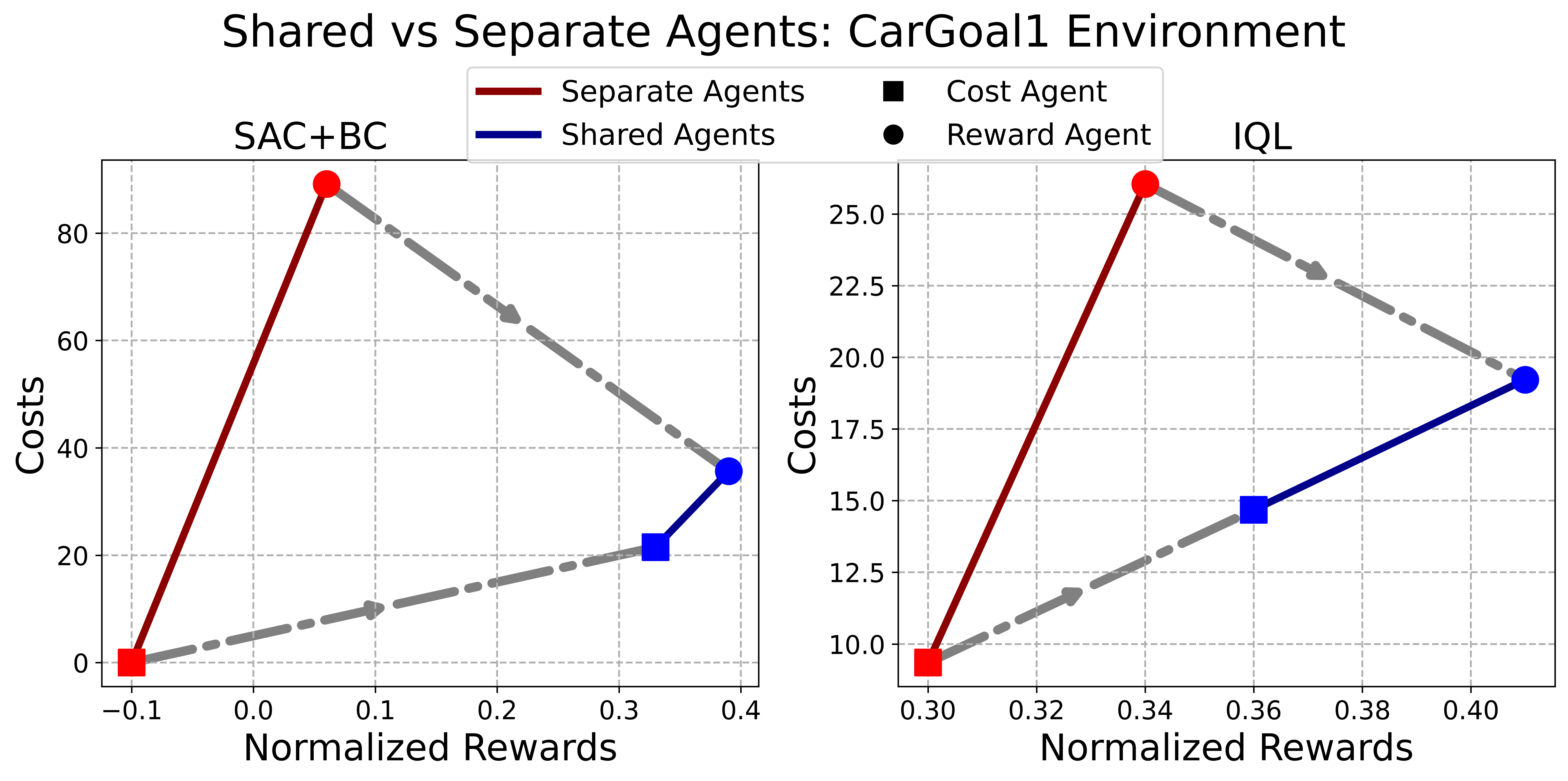
- 在DSRL基准测试中,CAPS在38个任务上显著优于现有方法,成为OSRL的强大基线。
📝 摘要(中文)
离线安全强化学习(OSRL)旨在从固定的训练数据集中学习决策策略,以最大化奖励并满足预定义的安全性约束。然而,在部署期间适应不同的安全性约束而不重新训练仍然是一个未被充分探索的挑战。为了解决这个问题,我们提出了约束自适应策略切换(CAPS),这是一个围绕现有离线强化学习算法的包装框架。在训练期间,CAPS使用离线数据学习多个具有共享表示的策略,这些策略优化不同的奖励和成本权衡。在测试期间,CAPS通过在每个状态选择满足当前成本约束的策略中最大化未来奖励的策略来在这些策略之间切换。我们在DSRL基准测试中的38个任务上的实验表明,CAPS始终优于现有方法,为OSRL建立了一个强大的基于包装器的基线。
🔬 方法详解
问题定义:离线安全强化学习(OSRL)旨在学习一个策略,在满足安全约束的前提下最大化累积奖励。然而,现有方法通常针对固定的安全约束进行优化,当部署环境中的安全约束发生变化时,需要重新训练模型,这在实际应用中是不切实际的。因此,如何使OSRL策略能够适应变化的安全约束是一个关键问题。
核心思路:CAPS的核心思路是学习一组策略,每个策略都对应于不同的奖励-成本权衡。在部署时,CAPS根据当前的安全约束,动态地选择能够满足约束并最大化未来奖励的策略。这种策略切换机制使得CAPS能够灵活地适应变化的安全约束,而无需重新训练。
技术框架:CAPS是一个包装器框架,可以应用于现有的离线强化学习算法。其主要包含两个阶段:训练阶段和测试阶段。在训练阶段,CAPS利用离线数据学习多个策略,每个策略都通过优化不同的奖励和成本函数来获得。这些策略共享一个表示,以提高学习效率。在测试阶段,CAPS根据当前的安全约束,选择能够满足约束并最大化未来奖励的策略执行动作。
关键创新:CAPS的关键创新在于其约束自适应策略切换机制。与现有方法不同,CAPS不是学习一个单一的策略,而是学习一组策略,并通过策略切换来适应变化的安全约束。这种方法避免了重新训练的需要,提高了策略的泛化能力。
关键设计:CAPS的关键设计包括:1) 使用共享表示来学习多个策略,以提高学习效率;2) 设计奖励和成本函数,以控制策略的奖励-成本权衡;3) 设计策略切换机制,以根据当前的安全约束选择合适的策略。具体来说,可以通过调整奖励函数和成本函数中的权重来实现不同的奖励-成本权衡。策略切换机制可以通过求解一个简单的优化问题来实现,即在满足安全约束的策略中选择最大化未来奖励的策略。
🖼️ 关键图片

📊 实验亮点
CAPS在DSRL基准测试的38个任务上进行了评估,实验结果表明,CAPS始终优于现有的离线安全强化学习方法。具体来说,CAPS在多个任务上取得了显著的性能提升,证明了其约束自适应策略切换机制的有效性。CAPS为离线安全强化学习提供了一个强大的基于包装器的基线。
🎯 应用场景
CAPS框架可应用于各种需要适应变化安全约束的强化学习任务,例如自动驾驶、机器人控制和医疗决策。在自动驾驶中,可以根据不同的交通状况和安全要求切换不同的驾驶策略。在机器人控制中,可以根据不同的任务目标和环境约束切换不同的控制策略。在医疗决策中,可以根据患者的病情和治疗目标切换不同的治疗方案。该研究具有重要的实际应用价值,可以提高强化学习算法的鲁棒性和泛化能力。
📄 摘要(原文)
Offline safe reinforcement learning (OSRL) involves learning a decision-making policy to maximize rewards from a fixed batch of training data to satisfy pre-defined safety constraints. However, adapting to varying safety constraints during deployment without retraining remains an under-explored challenge. To address this challenge, we introduce constraint-adaptive policy switching (CAPS), a wrapper framework around existing offline RL algorithms. During training, CAPS uses offline data to learn multiple policies with a shared representation that optimize different reward and cost trade-offs. During testing, CAPS switches between those policies by selecting at each state the policy that maximizes future rewards among those that satisfy the current cost constraint. Our experiments on 38 tasks from the DSRL benchmark demonstrate that CAPS consistently outperforms existing methods, establishing a strong wrapper-based baseline for OSRL. The code is publicly available at https://github.com/yassineCh/CAPS.