U-Mamba-Net: A highly efficient Mamba-based U-net style network for noisy and reverberant speech separation
作者: Shaoxiang Dang, Tetsuya Matsumoto, Yoshinori Takeuchi, Hiroaki Kudo
分类: cs.SD, cs.LG, eess.AS
发布日期: 2024-12-24
期刊: 2024 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC)
💡 一句话要点
提出U-Mamba-Net,一种高效的基于Mamba的U型网络,用于噪声和混响语音分离
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 语音分离 Mamba模型 U-Net 深度学习 Libri2mix 轻量级模型 状态空间模型
📋 核心要点
- 现有语音分离模型计算量大,复现和比较成本高昂,限制了研究进展。
- U-Mamba-Net结合Mamba的特征选择能力和U-Net的多分辨率特征学习能力,实现高效语音分离。
- 在Libri2mix数据集上,U-Mamba-Net在计算成本较低的情况下,实现了性能的提升。
📝 摘要(中文)
语音分离旨在将包含多个重叠说话者的混合语音分离成多个独立的语音流,每个语音流仅包含一个说话者的语音。目前涌现了许多高效的模型,但这些模型的规模和计算量也随之增加。这给研究人员带来了挑战,因为他们需要更多的时间和计算资源来复现和比较现有模型。本文提出了U-Mamba-Net:一个轻量级的基于Mamba的U型模型,用于复杂环境下的语音分离。Mamba是一种状态空间序列模型,具有特征选择能力。U型网络是一种全卷积神经网络,其对称的收缩和扩张路径能够学习多分辨率特征。在本文中,Mamba作为特征过滤器,与U-Net交替使用。在Libri2mix数据集上的实验结果表明,U-Mamba-Net以相当低的计算成本实现了性能的提升。
🔬 方法详解
问题定义:论文旨在解决复杂声学环境下的语音分离问题,特别是当混合语音包含噪声和混响时。现有深度学习模型在提升分离性能的同时,也带来了巨大的计算开销,使得研究人员难以复现和比较这些模型,阻碍了该领域的发展。因此,如何在保证分离性能的前提下,降低模型的计算复杂度,是本文要解决的核心问题。
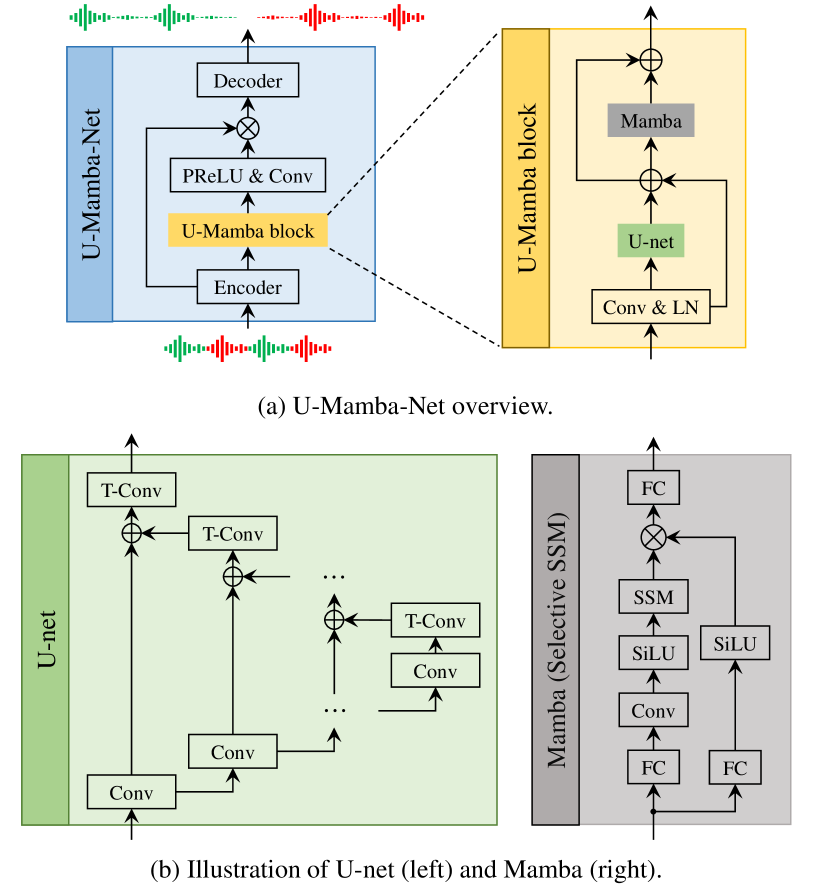
核心思路:论文的核心思路是将Mamba状态空间模型与U-Net架构相结合,利用Mamba的特征选择能力和U-Net的多分辨率特征提取能力,构建一个轻量级且高效的语音分离模型。Mamba可以动态地选择输入特征,从而减少冗余计算,而U-Net可以有效地提取不同尺度的特征,从而提高分离性能。
技术框架:U-Mamba-Net采用U-Net的编码器-解码器结构,其中编码器和解码器都由多个Mamba块组成。编码器负责提取输入语音的特征,并逐步降低特征图的分辨率;解码器负责将编码器的特征图恢复到原始分辨率,并生成分离后的语音。Mamba块在U-Net的收缩和扩张路径中交替使用,以实现特征过滤和多分辨率特征学习。
关键创新:该论文的关键创新在于将Mamba状态空间模型引入到U-Net架构中,用于语音分离任务。Mamba具有线性复杂度,并且能够动态地选择输入特征,从而显著降低了模型的计算复杂度。此外,Mamba与U-Net的结合,使得模型能够同时利用Mamba的特征选择能力和U-Net的多分辨率特征提取能力,从而提高了分离性能。
关键设计:论文中没有明确给出关键参数设置和损失函数的具体细节,这部分信息未知。但是,可以推断,Mamba块的参数设置(例如状态维度、选择机制等)以及U-Net的层数和滤波器数量等超参数,会对模型的性能产生重要影响。此外,损失函数的设计(例如SI-SNR损失、L1损失等)也会影响模型的训练效果。
🖼️ 关键图片
📊 实验亮点
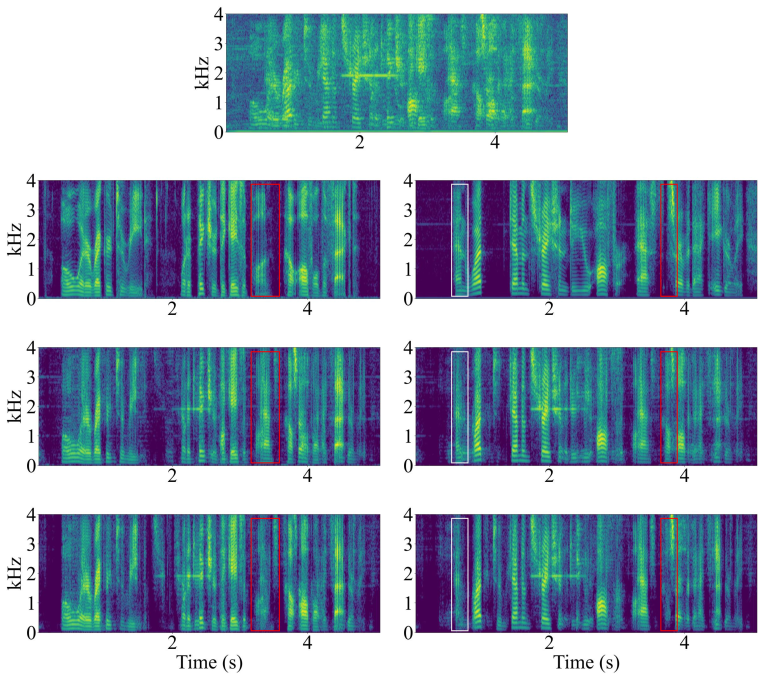
U-Mamba-Net在Libri2mix数据集上进行了评估,实验结果表明,该模型在计算成本较低的情况下,实现了语音分离性能的提升。具体的性能数据和提升幅度在摘要中没有明确给出,这部分信息未知。但是,可以推断,U-Mamba-Net在分离质量和计算效率方面都优于现有的基于深度学习的语音分离模型。
🎯 应用场景
U-Mamba-Net在语音分离领域具有广泛的应用前景,例如助听器、语音识别、语音增强、会议系统等。该模型可以有效地分离混合语音中的不同说话者,提高语音质量和可懂度。由于其计算复杂度较低,U-Mamba-Net更适合在资源受限的设备上部署,例如移动设备和嵌入式系统。未来,该模型可以进一步扩展到其他语音处理任务,例如语音合成和语音转换。
📄 摘要(原文)
The topic of speech separation involves separating mixed speech with multiple overlapping speakers into several streams, with each stream containing speech from only one speaker. Many highly effective models have emerged and proliferated rapidly over time. However, the size and computational load of these models have also increased accordingly. This is a disaster for the community, as researchers need more time and computational resources to reproduce and compare existing models. In this paper, we propose U-mamba-net: a lightweight Mamba-based U-style model for speech separation in complex environments. Mamba is a state space sequence model that incorporates feature selection capabilities. U-style network is a fully convolutional neural network whose symmetric contracting and expansive paths are able to learn multi-resolution features. In our work, Mamba serves as a feature filter, alternating with U-Net. We test the proposed model on Libri2mix. The results show that U-Mamba-Net achieves improved performance with quite low computational cost.