Quantum framework for Reinforcement Learning: Integrating Markov decision process, quantum arithmetic, and trajectory search
作者: Thet Htar Su, Shaswot Shresthamali, Masaaki Kondo
分类: quant-ph, cs.LG
发布日期: 2024-12-24 (更新: 2025-05-28)
期刊: Physical Review A (2025)
DOI: 10.1103/5lfr-xb8m
💡 一句话要点
提出一种量子强化学习框架,利用量子算术和轨迹搜索实现全量子MDP。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 量子强化学习 量子计算 马尔可夫决策过程 量子算法 量子搜索 量子叠加 机器学习
📋 核心要点
- 传统强化学习计算复杂度高,尤其是在状态空间大的情况下,探索效率低。
- 论文提出完全基于量子的强化学习框架,利用量子叠加和量子搜索算法加速学习过程。
- 实验结果表明,该量子模型在强化学习任务中具有量子增强的潜力,验证了其可行性。
📝 摘要(中文)
本文提出了一种用于解决强化学习(RL)任务的量子框架,该框架基于量子原理并利用经典马尔可夫决策过程(MDP)的完全量子模型。通过采用量子概念和量子搜索算法,这项工作展示了在量子域内完全实现和优化智能体-环境交互,消除了对经典计算的依赖。主要贡献包括基于量子的状态转移、回报计算和轨迹搜索机制,这些机制利用量子原理来展示通过量子现象实现RL过程。该实现强调了量子叠加在提高RL任务计算效率方面的根本作用。结果表明,量子模型能够在RL中实现量子增强,突出了完全量子实现在决策任务中的潜力。这项工作不仅强调了量子计算在机器学习中的适用性,而且通过为理解和利用RL系统中的量子计算提供一个强大的框架,为量子强化学习(QRL)领域做出了贡献。
🔬 方法详解
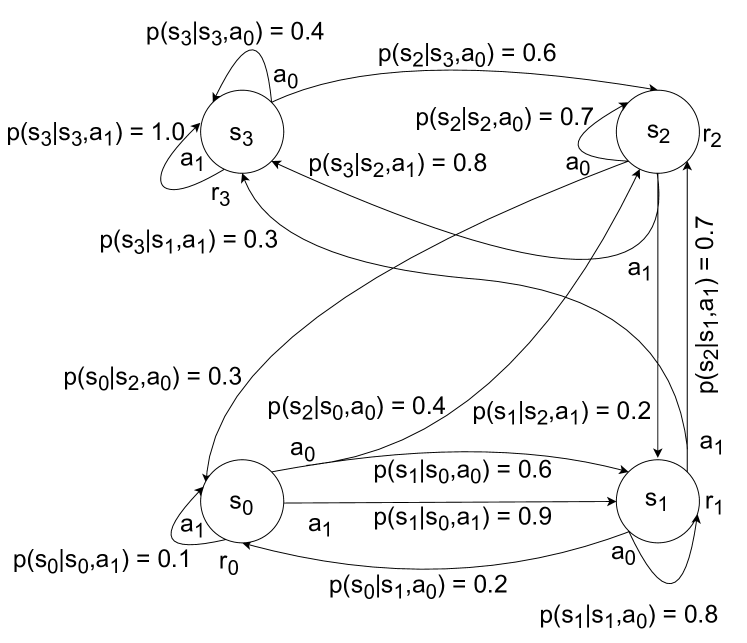
问题定义:论文旨在解决传统强化学习在复杂环境下的计算效率问题。经典强化学习算法,如Q-learning和SARSA,在状态空间较大时,需要大量的迭代才能收敛,计算成本高昂。此外,探索-利用的平衡也是一个挑战,传统的探索方法效率较低。
核心思路:论文的核心思路是将强化学习过程完全映射到量子域中,利用量子计算的优势来加速状态转移、回报计算和轨迹搜索。通过量子叠加,可以同时探索多个状态,提高探索效率。利用量子搜索算法,可以更快地找到最优策略。
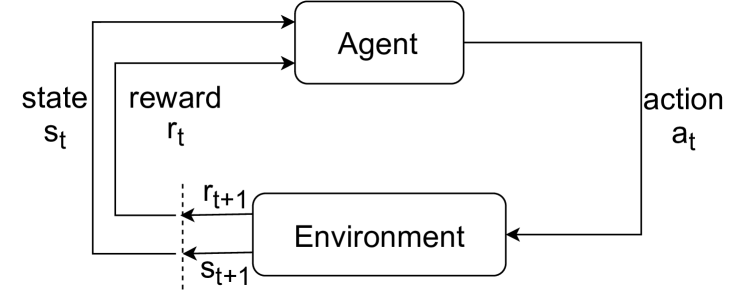
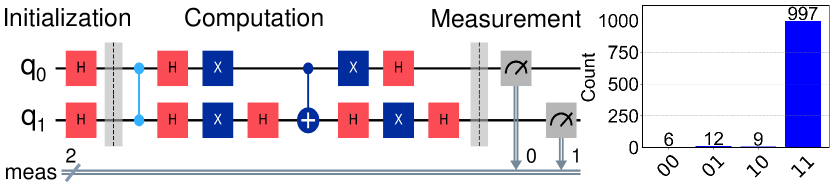
技术框架:该量子强化学习框架主要包含以下几个模块:1) 量子状态表示:使用量子比特表示环境的状态。2) 量子动作表示:使用量子比特表示智能体的动作。3) 量子状态转移:使用量子算子模拟环境的状态转移过程。4) 量子回报计算:使用量子算术计算智能体获得的回报。5) 量子轨迹搜索:使用量子搜索算法寻找最优轨迹。整个过程都在量子计算机上进行,无需与经典计算进行交互。
关键创新:该论文最重要的创新点在于提出了一个完全基于量子的强化学习框架,实现了智能体与环境交互的完全量子化。与以往的量子强化学习方法不同,该框架避免了经典计算的参与,充分利用了量子计算的优势。此外,该框架还提出了基于量子算术的回报计算方法和基于量子搜索算法的轨迹搜索方法。
关键设计:论文中关键的设计包括:1) 使用量子叠加表示状态和动作,允许同时探索多个可能性。2) 使用量子算术进行回报计算,利用量子并行性加速计算过程。3) 使用Grover搜索算法进行轨迹搜索,加速寻找最优策略。具体的参数设置和网络结构(如果存在)在论文中未详细说明,可能需要参考相关量子算法的实现细节。
🖼️ 关键图片
📊 实验亮点
论文结果表明,该量子模型在强化学习任务中能够实现量子增强,但具体的性能数据和对比基线未在摘要中明确给出。摘要强调了量子模型在决策任务中展现出的潜力,暗示了其在特定场景下可能优于经典强化学习算法。具体的提升幅度未知,需要在论文正文中查找。
🎯 应用场景
该研究成果可应用于需要快速决策和优化的领域,如金融交易、资源调度、机器人控制等。在这些领域,状态空间通常很大,传统的强化学习方法难以有效应用。量子强化学习有望利用量子计算的优势,实现更高效的决策和优化,从而提高效率和降低成本。未来,随着量子计算技术的不断发展,量子强化学习将在更多领域发挥重要作用。
📄 摘要(原文)
This paper introduces a quantum framework for addressing reinforcement learning (RL) tasks, grounded in the quantum principles and leveraging a fully quantum model of the classical Markov decision process (MDP). By employing quantum concepts and a quantum search algorithm, this work presents the implementation and optimization of the agent-environment interactions entirely within the quantum domain, eliminating reliance on classical computations. Key contributions include the quantum-based state transitions, return calculation, and trajectory search mechanism that utilize quantum principles to demonstrate the realization of RL processes through quantum phenomena. The implementation emphasizes the fundamental role of quantum superposition in enhancing computational efficiency for RL tasks. Results demonstrate the capacity of a quantum model to achieve quantum enhancement in RL, highlighting the potential of fully quantum implementations in decision-making tasks. This work not only underscores the applicability of quantum computing in machine learning but also contributes to the field of quantum reinforcement learning (QRL) by offering a robust framework for understanding and exploiting quantum computing in RL systems.