Highly Optimized Kernels and Fine-Grained Codebooks for LLM Inference on Arm CPUs
作者: Dibakar Gope, David Mansell, Danny Loh, Ian Bratt
分类: cs.LG, cs.AI, cs.AR, cs.CL
发布日期: 2024-12-23
🔗 代码/项目: GITHUB
💡 一句话要点
针对Arm CPU,提出优化kernel与细粒度码本加速LLM推理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 LLM推理 Arm CPU kernel优化 量化 低精度量化 非均匀码本 模型压缩
📋 核心要点
- 现有LLM推理在CPU上部署时,由于模型规模大和分组量化的高计算开销,难以满足延迟需求。
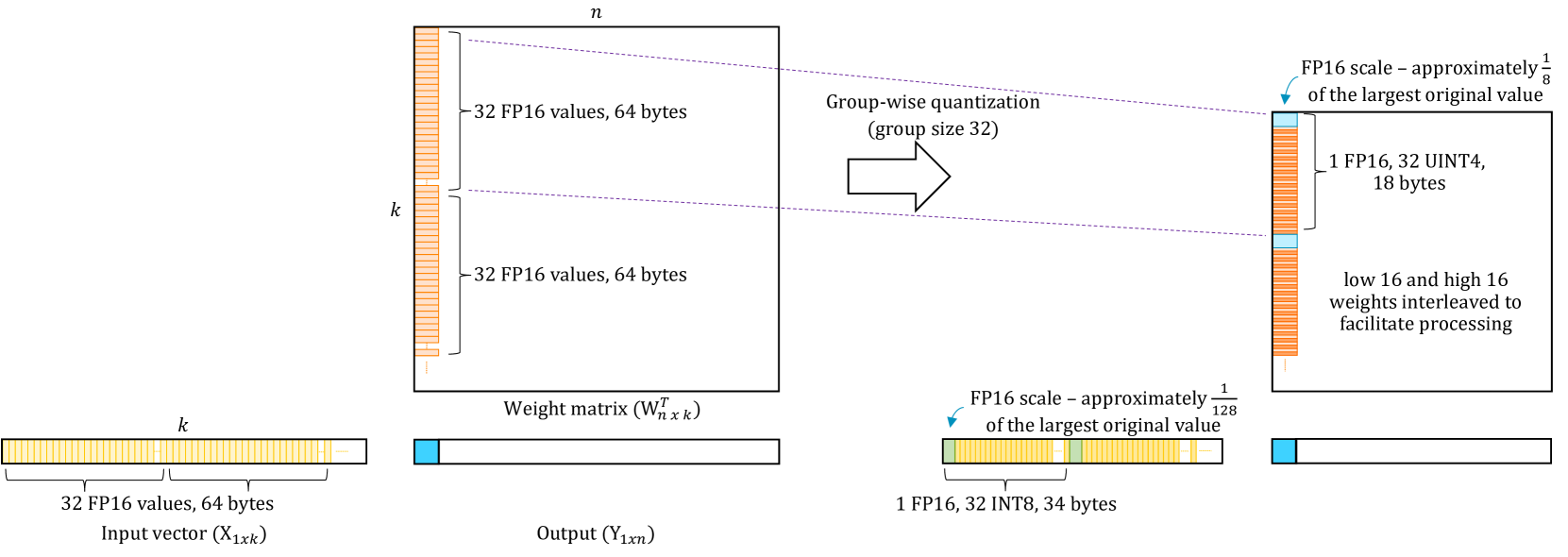
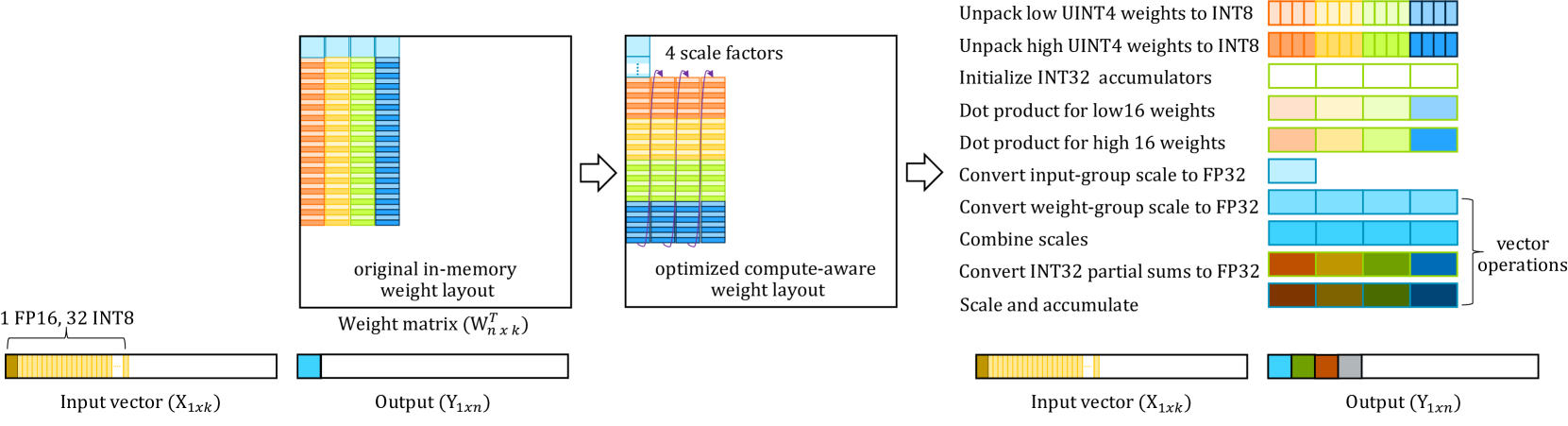
- 论文提出优化的kernel,通过分摊操作数加载和权重解包成本,并优化数据布局和解压缩路径来提升MAC效率。
- 实验表明,在Arm CPU上,该方法使4-bit LLM的prompt处理速度提升3-3.2倍,自回归解码速度提升2倍。
📝 摘要(中文)
大型语言模型(LLM)改变了我们对语言理解和生成的看法。然而,由于其前所未有的规模和资源需求,部署LLM进行推理一直是一个重大挑战。虽然将模型权重量化到亚字节精度已成为缓解内存压力的一个有希望的解决方案,但常用于LLM量化的分组量化格式具有显著的计算开销和资源密集型反量化过程。因此,更高比例的计算指令没有执行乘法,即实际工作,这使得它们不适合满足部署在商品CPU上的LLM所需的延迟要求。在这项工作中,我们提出了一组高度优化的内核来加速LLM推理,并释放CPU,特别是Arm CPU的全部潜力。这些内核分摊了跨多个输出行加载操作数和权重解包的成本。此外,我们引入了一种优化的交错组数据布局用于权重,并优化了解压缩路径,以减少不必要的操作和反量化开销,同时最大限度地利用向量和矩阵乘法运算,从而显著提高了MAC运算的效率。此外,我们提出了一种基于分组非均匀码本的量化方法,用于LLM的超低精度量化,以更好地匹配其权重分布中的非均匀模式,从而在token生成期间表现出更好的吞吐量,同时确保比最先进技术更好的质量。与基于LLaMA.cpp的解决方案相比,将这些改进应用于4-bit LLM,在Arm CPU上实现了3-3.2倍的prompt处理改进和2倍的自回归解码改进。优化的内核可在https://github.com/ggerganov/llama.cpp获得。
🔬 方法详解
问题定义:论文旨在解决在Arm CPU上部署大型语言模型(LLM)进行推理时,由于模型体积庞大和计算复杂度高而导致的性能瓶颈问题。现有方法,特别是基于分组量化的方法,虽然能有效压缩模型大小,但引入了显著的计算开销,使得CPU资源利用率不高,无法满足低延迟需求。
核心思路:论文的核心思路是通过优化底层计算kernel和改进量化策略,来提升LLM在Arm CPU上的推理效率。具体而言,通过精心设计的kernel来分摊数据加载和权重解包的开销,并采用优化的数据布局和解压缩路径来减少不必要的操作,从而最大限度地利用CPU的向量和矩阵乘法能力。
技术框架:论文的技术框架主要包含两个方面:一是优化计算kernel,二是改进量化方法。优化的kernel专注于提升矩阵乘法的效率,通过分摊数据加载和权重解包的开销来降低计算成本。改进的量化方法则采用分组非均匀码本,以更好地匹配LLM权重分布的非均匀性,从而在保证模型质量的同时,进一步压缩模型大小。
关键创新:论文的关键创新在于提出了高度优化的kernel和分组非均匀码本量化方法。优化的kernel通过分摊计算开销和减少不必要的操作,显著提升了CPU的计算效率。分组非均匀码本量化方法则能够更好地适应LLM权重分布的特点,在保证模型性能的同时,实现更高的压缩率。与现有方法相比,该方法能够更有效地利用CPU资源,实现更低的推理延迟。
关键设计:在kernel优化方面,关键设计包括操作数加载和权重解包的分摊策略,以及向量和矩阵乘法运算的最大化利用。在量化方法方面,关键设计包括分组非均匀码本的构建方式,以及如何根据权重分布的特点来选择合适的码本。此外,论文还针对Arm CPU的特性进行了专门的优化,例如利用NEON指令集来加速向量计算。
🖼️ 关键图片

📊 实验亮点
实验结果表明,与基于LLaMA.cpp的解决方案相比,该方法在Arm CPU上实现了显著的性能提升。对于4-bit LLM,prompt处理速度提升了3-3.2倍,自回归解码速度提升了2倍。这些数据表明,该方法能够有效地提升LLM在Arm CPU上的推理效率,具有很强的实用性。
🎯 应用场景
该研究成果可广泛应用于移动设备、嵌入式系统等Arm架构平台上部署LLM的场景,例如智能助手、机器翻译、语音识别等。通过提升推理效率,降低延迟,可以改善用户体验,并为更多资源受限的设备提供部署LLM的能力,具有重要的实际应用价值和深远影响。
📄 摘要(原文)
Large language models (LLMs) have transformed the way we think about language understanding and generation, enthralling both researchers and developers. However, deploying LLMs for inference has been a significant challenge due to their unprecedented size and resource requirements. While quantizing model weights to sub-byte precision has emerged as a promising solution to ease memory pressure, the group quantization formats commonly used for LLM quantization have significant compute overheads and a resource-intensive dequantization process. As a result, a higher proportion of compute instructions do not perform multiplies, i.e., real work, rendering them unsuitable for meeting the required latency requirements for LLMs deployed on commodity CPUs. In this work, we propose a set of highly optimized kernels to accelerate LLM inference and unleash the full potential of CPUs, particularly Arm CPUs. These kernels amortize the cost of loading the operands and the cost of weight unpacking across multiple output rows. This, along with the introduction of an optimized interleaved group data layout for weights and decompression path optimizations to reduce unnecessary operations and dequantization overhead while maximizing the use of vector and matrix multiply operations, significantly improves the efficiency of MAC operations. Furthermore, we present a groupwise non-uniform codebook-based quantization method for ultra-low-precision quantization of LLMs to better match non-uniform patterns in their weight distributions, demonstrating better throughput during token generation while ensuring better quality than the state-of-the-art. Applying these improvements to 4-bit LLMs results in a 3-3.2x improvement in prompt processing and a 2x improvement in autoregressive decoding on Arm CPUs, compared to LLaMA.cpp-based solution. The optimized kernels are available at https://github.com/ggerganov/llama.cpp.