Lillama: Large Language Models Compression via Low-Rank Feature Distillation
作者: Yaya Sy, Christophe Cerisara, Irina Illina
分类: cs.LG, cs.AI
发布日期: 2024-12-21 (更新: 2024-12-28)
备注: 20 pages, 8 figures
💡 一句话要点
Lillama:通过低秩特征蒸馏压缩大型语言模型,显著降低参数量并保持性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型压缩 低秩蒸馏 结构化剪枝 激活值蒸馏 模型加速
📋 核心要点
- 现有LLM压缩方法依赖耗时的持续预训练来弥补压缩带来的性能损失,成本高昂。
- Lillama通过低秩特征蒸馏,在压缩过程中保持激活值的信息,从而避免了大规模的持续预训练。
- 实验表明,Lillama能有效压缩Mixtral、Phi-2和Mamba等模型,在显著减少参数量的同时,保持了较高的性能。
📝 摘要(中文)
现有的LLM结构化剪枝方法通常包含两个步骤:(1)使用校准数据进行压缩;(2)进行代价高昂的持续预训练,以恢复损失的性能。第二个步骤是必要的,因为第一个步骤会显著影响模型精度。先前的研究表明,预训练Transformer的权重本质上不是低秩的,但其激活值可能是低秩的,这可能解释了性能下降的原因。基于此,我们提出Lillama,一种通过低秩权重局部蒸馏激活值的压缩方法。使用SVD进行初始化,并结合教师和学生激活值的联合损失,我们加速了收敛,并通过局部梯度更新减少了内存使用。Lillama可以在单个A100 GPU上在几分钟内压缩Mixtral-8x7B,移除100亿个参数,同时保留超过95%的原始性能。Phi-2 3B可以使用仅1300万个校准token压缩40%,从而产生一个与最近类似大小的模型竞争的小型模型。该方法可以很好地推广到非Transformer架构,将Mamba-3B压缩20%,同时保持99%的性能。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)压缩过程中,结构化剪枝导致性能显著下降,以及后续需要大量计算资源进行持续预训练的问题。现有方法直接剪枝权重,破坏了模型原有的知识结构,导致性能损失难以恢复。
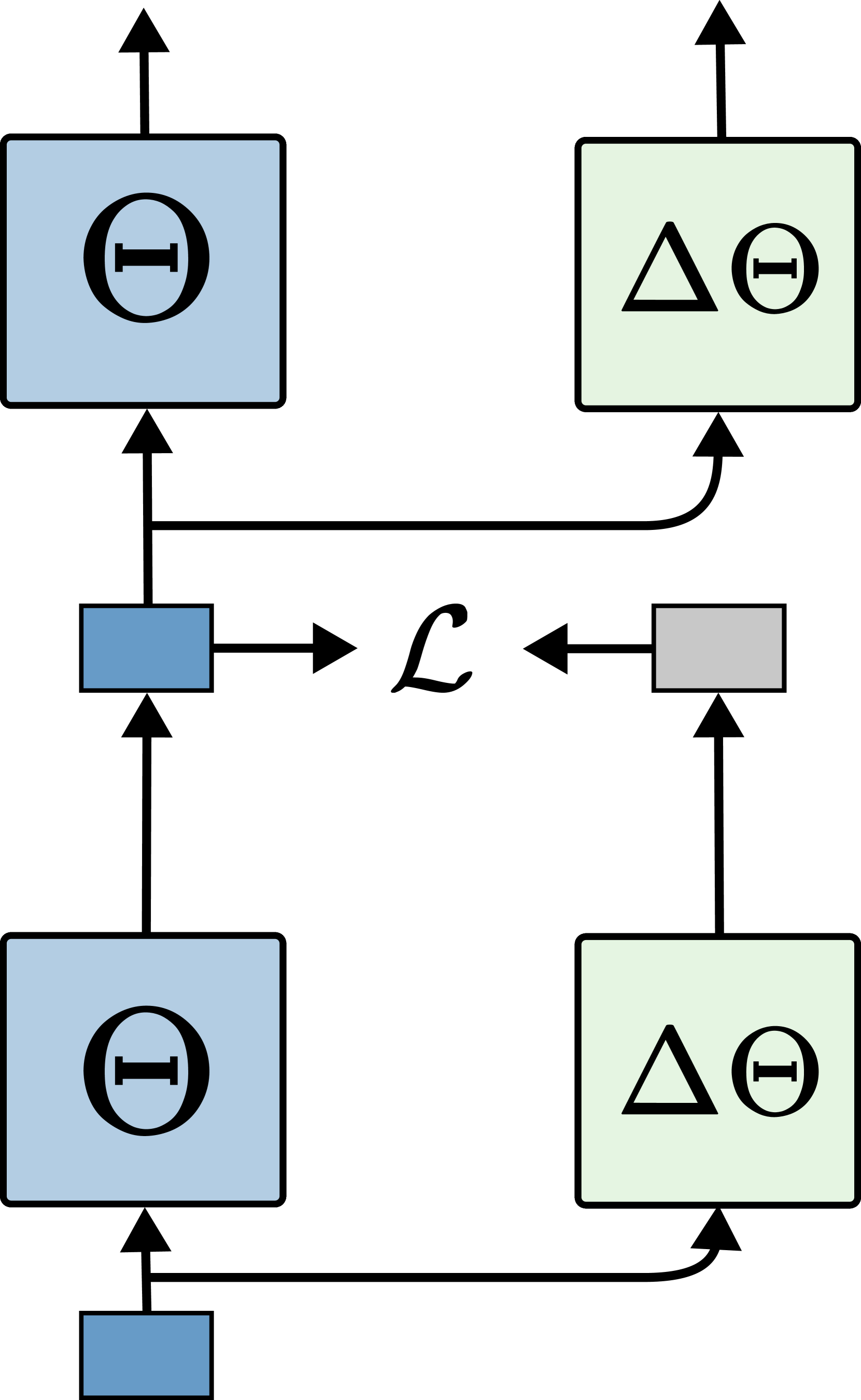
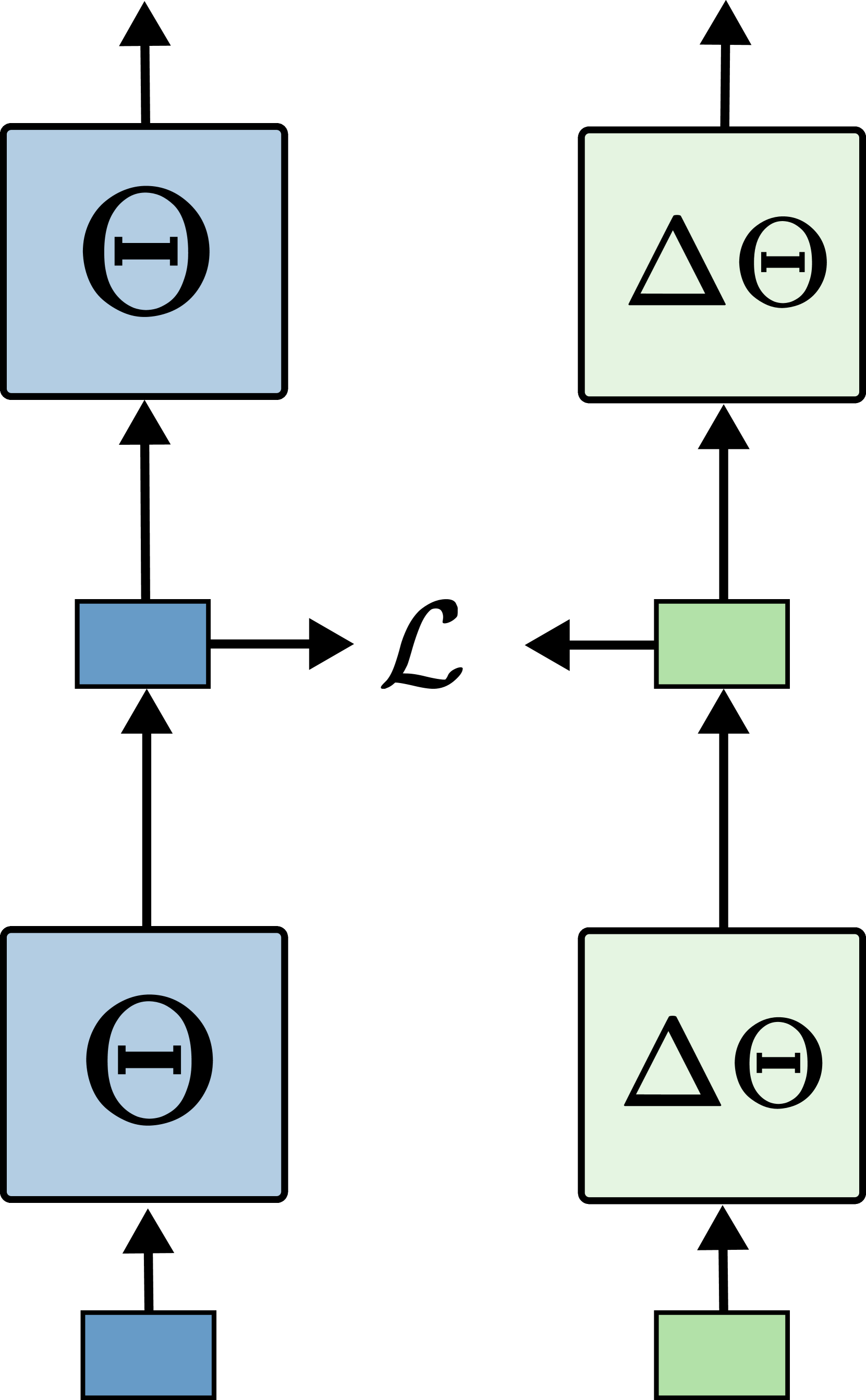
核心思路:论文的核心思路是观察到Transformer的激活值具有低秩特性,而权重本身不具备。因此,通过低秩特征蒸馏,将教师模型(原始模型)的激活值信息传递给学生模型(压缩模型),从而在压缩过程中保留模型的关键信息,避免性能大幅下降。
技术框架:Lillama的整体框架包括以下几个主要步骤:1) 使用SVD对学生模型的权重进行初始化,使其具有低秩特性;2) 使用校准数据集,计算教师模型和学生模型的激活值;3) 使用联合损失函数,同时优化学生模型的激活值和教师模型的激活值之间的差异,以及学生模型的预测结果;4) 通过局部梯度更新,加速收敛并减少内存使用。
关键创新:Lillama的关键创新在于利用了激活值的低秩特性进行蒸馏,避免了直接对权重进行剪枝,从而更好地保留了模型的知识。此外,使用SVD初始化和联合损失函数,加速了收敛过程,并提高了压缩模型的性能。
关键设计:Lillama的关键设计包括:1) 使用SVD初始化学生模型的权重,使其具有低秩特性;2) 设计联合损失函数,包括激活值蒸馏损失和预测损失,平衡压缩和性能;3) 采用局部梯度更新,减少内存占用,使得在单个A100 GPU上压缩大型模型成为可能。激活值蒸馏损失通常采用L2损失或余弦相似度损失,用于衡量学生模型和教师模型激活值之间的差异。
🖼️ 关键图片

📊 实验亮点
Lillama在压缩Mixtral-8x7B时,可以在单个A100 GPU上在几分钟内移除100亿个参数,同时保留超过95%的原始性能。对于Phi-2 3B,可以使用仅1300万个校准token压缩40%,生成的小模型可以与最近类似大小的模型竞争。此外,Lillama还可以将Mamba-3B压缩20%,同时保持99%的性能。
🎯 应用场景
Lillama具有广泛的应用前景,可用于在资源受限的设备上部署大型语言模型,例如移动设备、边缘计算设备等。通过压缩模型,可以降低模型的存储空间和计算复杂度,从而实现更高效的推理。此外,Lillama还可以用于加速模型的训练和推理,提高模型的响应速度。
📄 摘要(原文)
Current LLM structured pruning methods typically involve two steps: (1) compression with calibration data and (2) costly continued pretraining on billions of tokens to recover lost performance. This second step is necessary as the first significantly impacts model accuracy. Prior research suggests pretrained Transformer weights aren't inherently low-rank, unlike their activations, which may explain this drop. Based on this observation, we propose Lillama, a compression method that locally distills activations with low-rank weights. Using SVD for initialization and a joint loss combining teacher and student activations, we accelerate convergence and reduce memory use with local gradient updates. Lillama compresses Mixtral-8x7B within minutes on a single A100 GPU, removing 10 billion parameters while retaining over 95% of its original performance. Phi-2 3B can be compressed by 40% with just 13 million calibration tokens, resulting in a small model that competes with recent models of similar size. The method generalizes well to non-transformer architectures, compressing Mamba-3B by 20% while maintaining 99% performance.