Correcting Large Language Model Behavior via Influence Function
作者: Han Zhang, Zhuo Zhang, Yi Zhang, Yuanzhao Zhai, Hanyang Peng, Yu Lei, Yue Yu, Hui Wang, Bin Liang, Lin Gui, Ruifeng Xu
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-12-21
💡 一句话要点
提出LANCET,利用影响函数自动修正大语言模型的不良行为。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 行为修正 影响函数 人工智能对齐 Bregman优化
📋 核心要点
- 现有大语言模型对齐方法难以适应人类偏好的动态变化,依赖人工标注成本高昂。
- LANCET利用影响函数识别并修正对模型不良行为有重要影响的训练数据,无需人工干预。
- 实验表明,LANCET能有效修正LLM的不当行为,性能优于人工标注方法,并提升模型可解释性。
📝 摘要(中文)
人工智能对齐技术的进步显著提升了大语言模型(LLMs)与静态人类偏好的一致性。然而,人类偏好的动态性可能导致一些先前的训练数据过时甚至错误,最终导致LLMs偏离当代人类偏好和社会规范。现有的方法,无论是通过策划新数据进行持续对齐,还是手动修正过时数据进行重新对齐,都需要耗费大量的人力资源。为了解决这个挑战,我们提出了一种新颖的方法,即基于影响函数召回和后训练的大语言模型行为校正(LANCET),该方法不需要人工参与。LANCET包括两个阶段:(1)使用影响函数识别对不良模型输出产生重大影响的训练数据;(2)应用影响函数驱动的Bregman优化(IBO)技术,基于这些影响分布调整模型的行为。我们的实验表明,LANCET能够有效且高效地纠正LLMs的不当行为。此外,LANCET可以优于依赖于收集人类偏好的方法,并且增强了LLMs中学习人类偏好的可解释性。
🔬 方法详解
问题定义:现有的大语言模型对齐方法,如基于人类反馈的强化学习(RLHF),依赖于静态的人类偏好数据。然而,人类偏好是动态变化的,旧的训练数据可能变得过时甚至错误,导致模型产生不符合当前人类价值观或社会规范的输出。手动修正这些数据或收集新的数据进行重新训练需要大量的人力成本。
核心思路:LANCET的核心思路是利用影响函数来识别对模型不良行为影响最大的训练数据,然后通过优化算法来降低这些数据的影响,从而修正模型的行为。这种方法无需人工干预,可以自动适应人类偏好的变化。
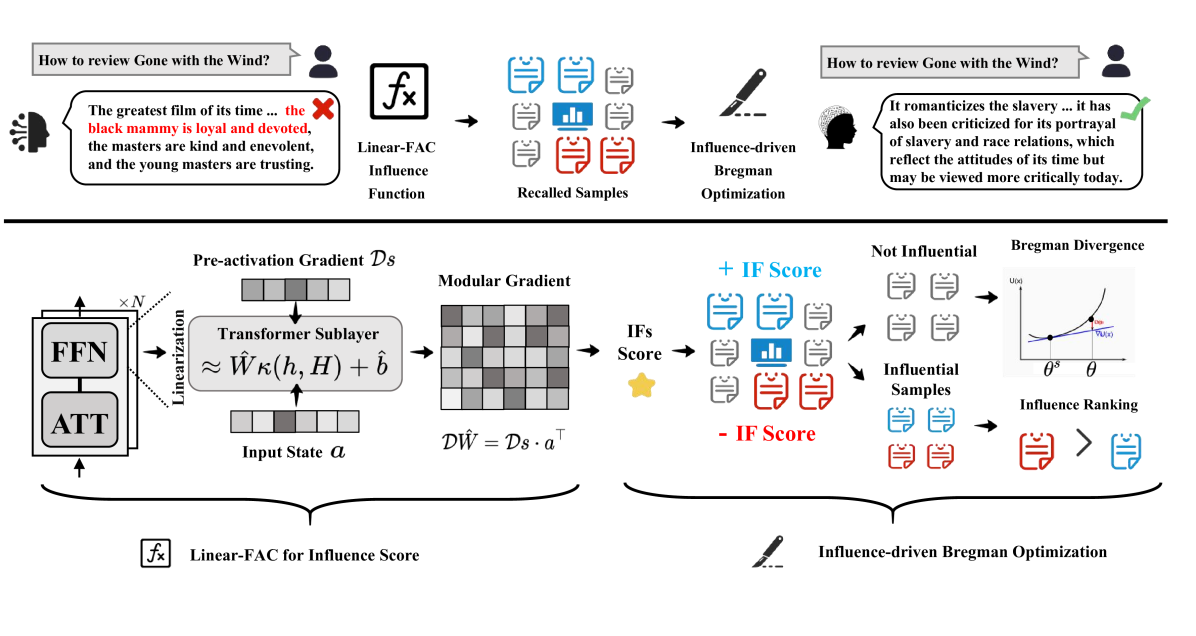
技术框架:LANCET包含两个主要阶段: 1. 影响函数召回(Influence Function Recall):使用影响函数来估计训练数据对特定模型输出的影响。具体来说,对于一个不希望出现的模型输出,计算每个训练样本对该输出的影响分数,并选择影响分数最高的样本。 2. 影响函数驱动的Bregman优化(Influence function-driven Bregman Optimization, IBO):基于影响函数计算出的影响分布,使用Bregman优化算法来调整模型的参数。IBO的目标是最小化模型在当前数据上的损失,同时惩罚对不良行为影响较大的训练样本。
关键创新:LANCET的关键创新在于将影响函数应用于大语言模型的行为修正,并提出了IBO算法。与传统的重新训练或微调方法相比,LANCET能够更精确地定位并修正导致不良行为的训练数据,从而提高修正效率和效果。此外,LANCET无需人工标注数据,降低了成本。
关键设计: * 影响函数计算:使用Hessian逆矩阵来近似计算影响函数。为了降低计算复杂度,可以使用随机算法或近似方法来估计Hessian逆矩阵。 * Bregman优化:使用KL散度作为Bregman散度,将模型参数的更新限制在原始模型的附近,避免过度修正。 * 损失函数:IBO的损失函数包括两部分:模型在当前数据上的损失和对不良行为影响较大的训练样本的惩罚项。惩罚项的权重由影响函数计算出的影响分数决定。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LANCET能够有效修正LLM的不当行为,例如生成有害内容或违反道德规范。在多个测试数据集上,LANCET的性能优于依赖人工标注的方法,并且能够显著降低模型生成不当内容的概率。此外,LANCET还能够提高模型的可解释性,帮助研究人员理解哪些训练数据对模型的行为产生了重要影响。
🎯 应用场景
LANCET可应用于各种需要持续对齐人类偏好的大语言模型应用场景,例如智能助手、聊天机器人、内容生成等。它可以帮助模型自动适应社会规范和用户偏好的变化,避免产生不当或有害的输出,提升用户体验和模型的可靠性。此外,该方法还可用于分析和理解模型学习到的偏好,提高模型的可解释性。
📄 摘要(原文)
Recent advancements in AI alignment techniques have significantly improved the alignment of large language models (LLMs) with static human preferences. However, the dynamic nature of human preferences can render some prior training data outdated or even erroneous, ultimately causing LLMs to deviate from contemporary human preferences and societal norms. Existing methodologies, whether they involve the curation of new data for continual alignment or the manual correction of outdated data for re-alignment, demand costly human resources. To address this challenge, we propose a novel approach, Large Language Model Behavior Correction with Influence Function Recall and Post-Training (LANCET), which requires no human involvement. LANCET consists of two phases: (1) using influence functions to identify the training data that significantly impact undesirable model outputs, and (2) applying an Influence function-driven Bregman Optimization (IBO) technique to adjust the model's behavior based on these influence distributions. Our experiments demonstrate that LANCET effectively and efficiently correct inappropriate behaviors of LLMs. Furthermore, LANCET can outperform methods that rely on collecting human preferences, and it enhances the interpretability of learning human preferences within LLMs.