Decoding fairness: a reinforcement learning perspective
作者: Guozhong Zheng, Jiqiang Zhang, Xin Ou, Shengfeng Deng, Li Chen
分类: cs.LG, cond-mat.dis-nn, nlin.AO, physics.soc-ph, q-bio.PE
发布日期: 2024-12-20
备注: 12 pages, 13 figures. Comments are appreciated
💡 一句话要点
基于强化学习在最后通牒博弈中解码公平性行为
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 最后通牒博弈 公平性 Q学习 多智能体系统
📋 核心要点
- 传统经济学理论难以解释最后通牒博弈中人类的公平偏好,现有解释侧重于模仿学习框架下的外生因素。
- 本研究采用强化学习范式,通过Q学习模拟博弈参与者的决策过程,探索公平行为的内生涌现机制。
- 实验结果表明,在重视经验和未来奖励的情况下,博弈系统能够自发演化出公平策略,且结果对多种环境设置具有鲁棒性。
📝 摘要(中文)
本研究采用强化学习范式,探索最后通牒博弈(UG)中公平行为的涌现。与传统经济学预测相反,人类倾向于公平行为。现有解释多归因于模仿学习框架下的外生因素。本文采用Q学习方法,为博弈中的每个参与者分配两个Q表,分别指导其作为提议者和响应者的决策。在双人博弈中,当经验和未来奖励都被重视时,公平性显著出现。特别是,交易成功概率随着提议报价的增加而提高,这与行为实验中的观察结果一致。机制分析表明,系统经历了两个阶段,最终稳定为公平或理性策略。当轮换角色分配被随机或固定方式取代,或场景扩展到格子状群体时,这些结果仍然稳健。研究结果表明,内生因素足以解释公平性的出现,不需要外生因素。
🔬 方法详解
问题定义:论文旨在解决最后通牒博弈中公平行为的涌现问题。现有方法,如基于模仿学习的解释,通常依赖于外生因素,未能充分解释公平行为的内生驱动力。传统经济学理论也无法解释人类在博弈中的公平偏好,认为理性人会接受任何大于零的提议。
核心思路:论文的核心思路是利用强化学习模拟博弈参与者的决策过程,通过最大化累积奖励来学习策略。通过Q学习,参与者可以根据自身经验和对未来奖励的预期,逐步调整其提议和响应策略,从而涌现出公平行为。这种方法强调了内生因素在公平行为形成中的作用。
技术框架:论文采用Q学习算法,构建了一个双人最后通牒博弈的强化学习模型。每个参与者拥有两个Q表,分别用于指导其作为提议者和响应者的决策。博弈过程包括提议者提出分配方案,响应者决定接受或拒绝。参与者根据博弈结果获得奖励,并更新Q表。通过多次迭代,参与者逐步学习最优策略。
关键创新:论文的关键创新在于将强化学习应用于最后通牒博弈,并证明了内生因素足以解释公平行为的涌现。与以往依赖外生因素的解释不同,该研究表明,通过合理的奖励机制和学习过程,参与者可以自发地演化出公平策略。此外,该研究还分析了系统演化的两个阶段,并验证了结果的鲁棒性。
关键设计:论文的关键设计包括:1) 使用Q学习算法,允许参与者学习最优策略;2) 为每个参与者分配两个Q表,分别用于提议者和响应者角色;3) 设计合理的奖励函数,鼓励公平行为;4) 通过调整学习率、折扣因子等参数,控制学习过程;5) 在不同的环境设置下进行实验,验证结果的鲁棒性,例如改变角色分配方式(轮换、随机、固定)和扩展到格子状群体。
🖼️ 关键图片
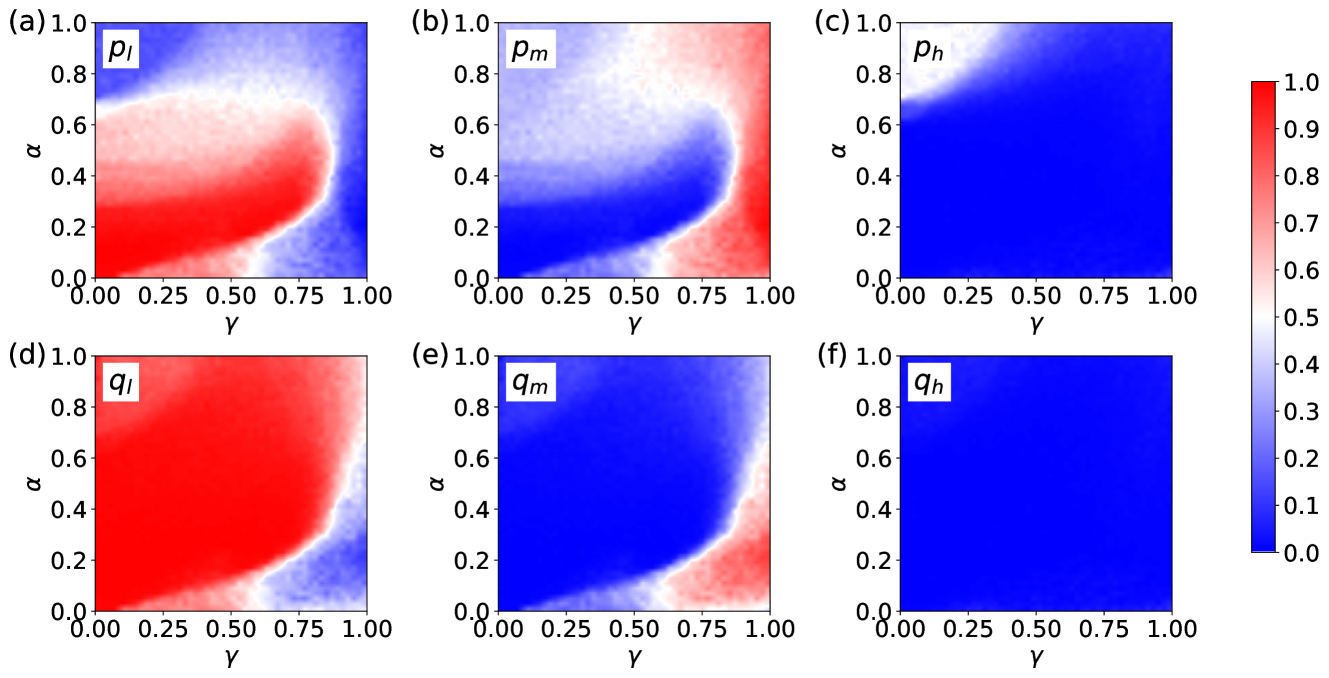

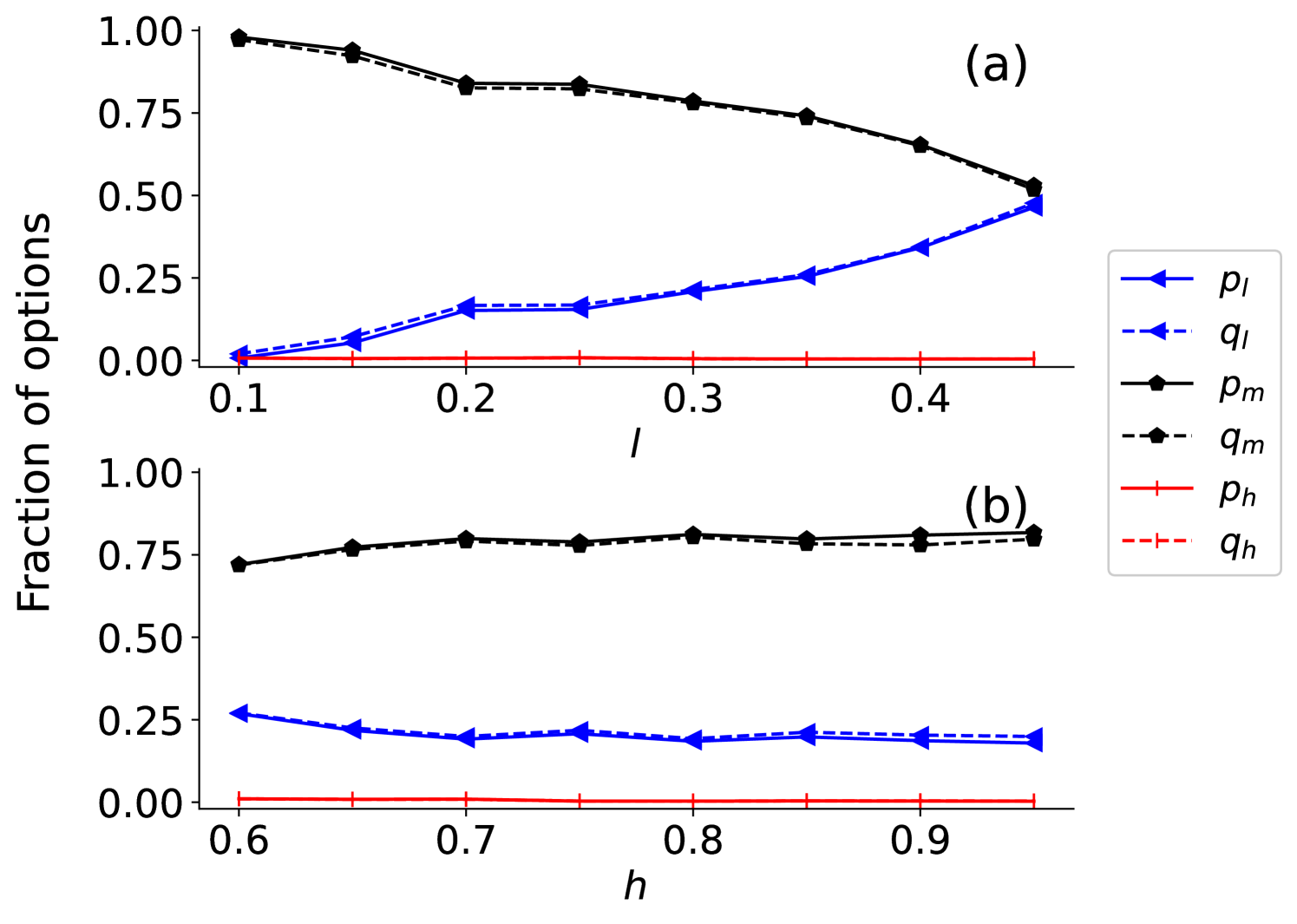
📊 实验亮点
研究表明,当参与者重视经验和未来奖励时,最后通牒博弈中会涌现出公平行为。具体而言,随着提议报价的增加,交易成功的概率也随之增加,这与行为实验中的观察结果一致。机制分析表明,系统经历了两个阶段,最终稳定为公平或理性策略。这些结果在不同的环境设置下都具有鲁棒性,例如改变角色分配方式或扩展到格子状群体。
🎯 应用场景
该研究成果可应用于理解和设计更公平的社会系统和人工智能代理。例如,在多智能体系统中,可以利用强化学习训练代理,使其在资源分配和合作博弈中表现出公平行为。此外,该研究还可以为经济学、心理学和社会学等领域提供新的视角,帮助人们更好地理解人类的公平偏好。
📄 摘要(原文)
Behavioral experiments on the ultimatum game (UG) reveal that we humans prefer fair acts, which contradicts the prediction made in orthodox Economics. Existing explanations, however, are mostly attributed to exogenous factors within the imitation learning framework. Here, we adopt the reinforcement learning paradigm, where individuals make their moves aiming to maximize their accumulated rewards. Specifically, we apply Q-learning to UG, where each player is assigned two Q-tables to guide decisions for the roles of proposer and responder. In a two-player scenario, fairness emerges prominently when both experiences and future rewards are appreciated. In particular, the probability of successful deals increases with higher offers, which aligns with observations in behavioral experiments. Our mechanism analysis reveals that the system undergoes two phases, eventually stabilizing into fair or rational strategies. These results are robust when the rotating role assignment is replaced by a random or fixed manner, or the scenario is extended to a latticed population. Our findings thus conclude that the endogenous factor is sufficient to explain the emergence of fairness, exogenous factors are not needed.