Extracting Interpretable Task-Specific Circuits from Large Language Models for Faster Inference
作者: Jorge García-Carrasco, Alejandro Maté, Juan Trujillo
分类: cs.LG
发布日期: 2024-12-20
备注: Accepted to AAAI 25 Main Technical Track
💡 一句话要点
提出一种从大语言模型中提取任务特定电路的方法,加速推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 任务特定电路 模型提取 机制可解释性 快速推理
📋 核心要点
- 大型语言模型体积庞大,在资源受限场景应用受限,且通用能力在特定任务中存在浪费。
- 该论文提出一种自动提取LLM中任务特定电路的方法,无需额外训练,仅需少量数据。
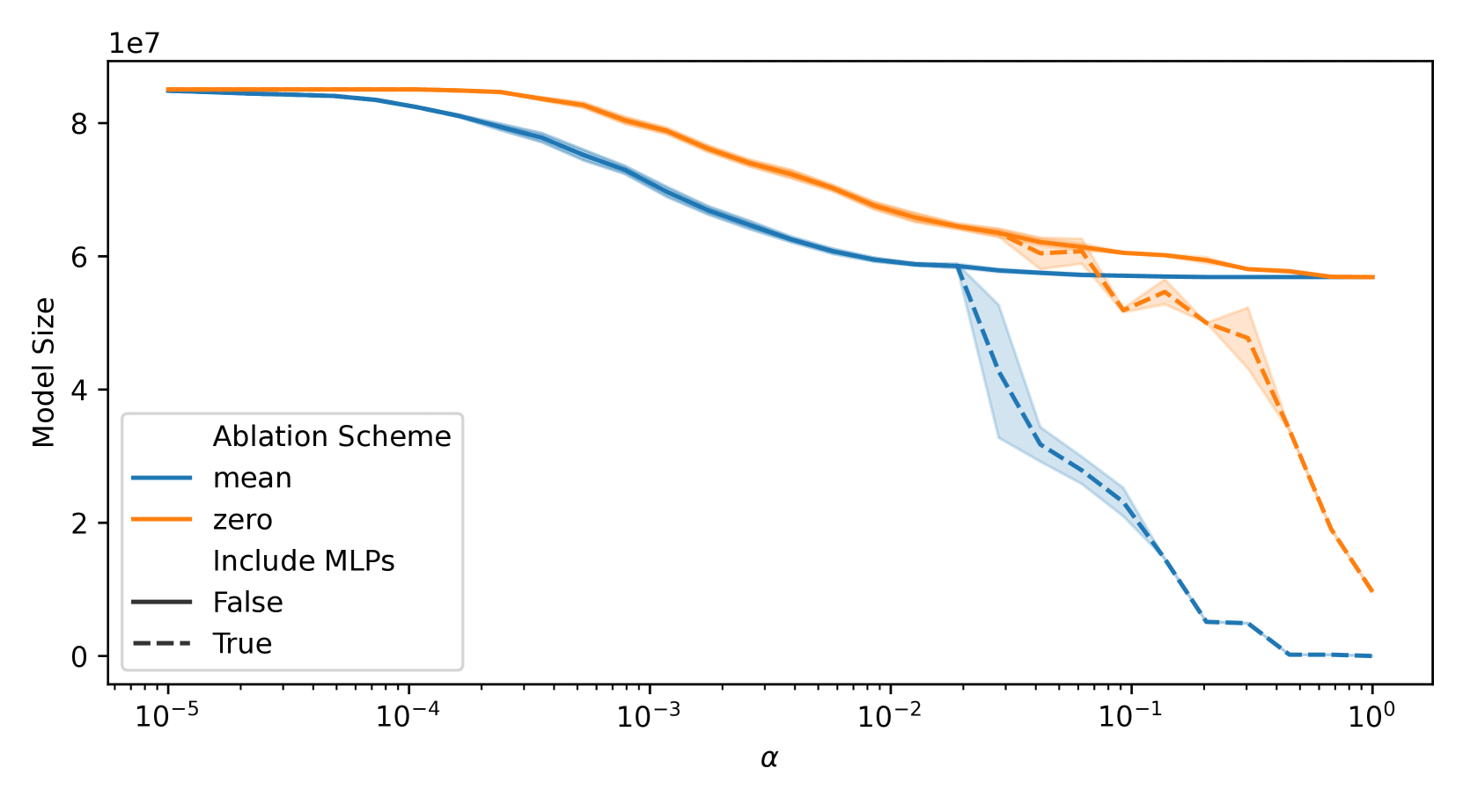
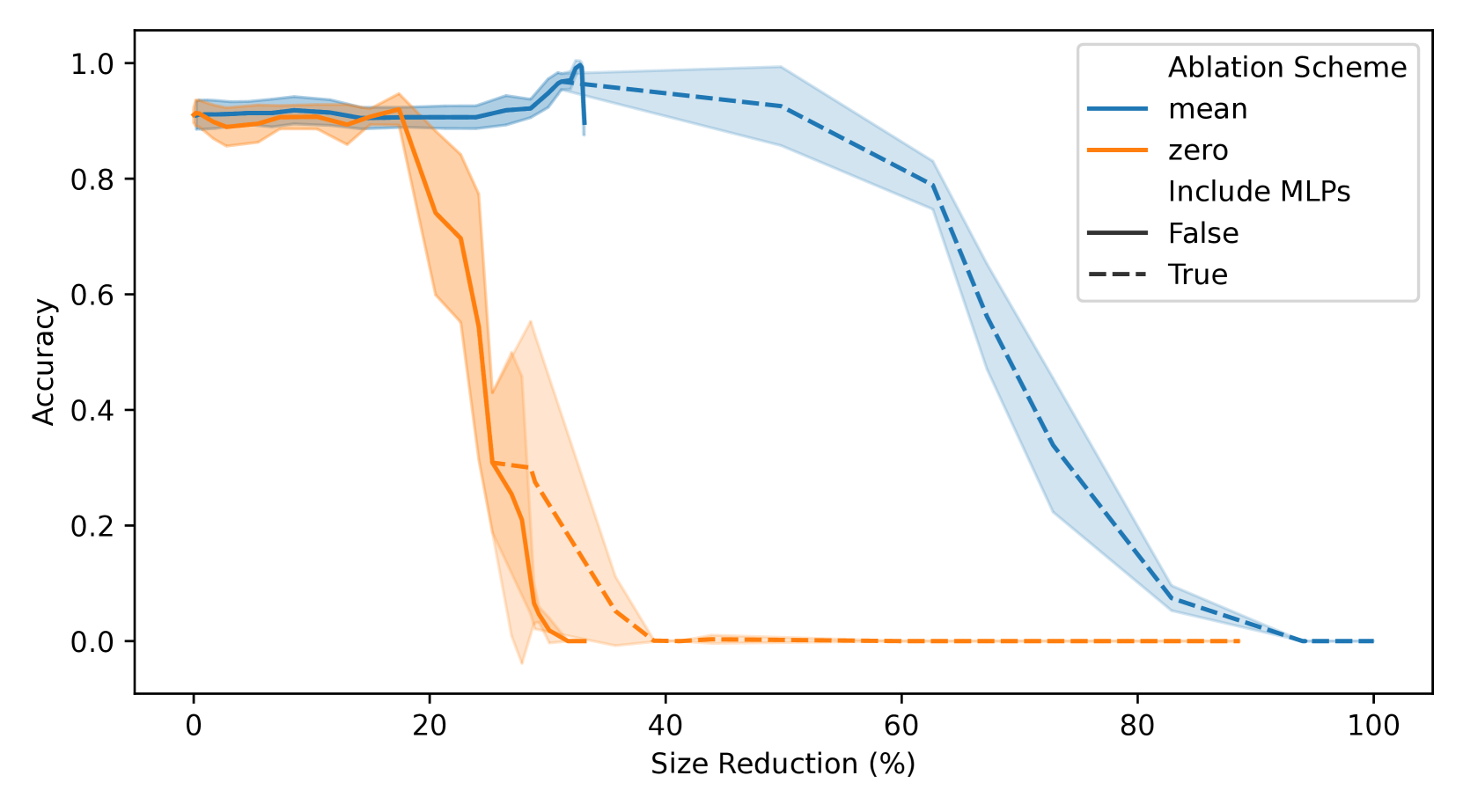
- 实验表明,提取后的模型参数量显著减少(高达82.77%),且更易于使用机制可解释性技术理解。
📝 摘要(中文)
大型语言模型(LLMs)在各种任务中表现出令人印象深刻的性能。然而,LLMs的规模正在稳步增长,阻碍了它们在计算受限环境中的应用。另一方面,尽管它们具有通用能力,但在许多情况下只执行一项特定任务,使得所有其他能力变得不必要且浪费。这引出了以下问题:是否可以从LLM中提取最小的子集,使其能够以更快、独立的方式执行特定任务?最近关于机制可解释性(MI)的研究表明,特定任务是由组件或电路的局部子集执行的。然而,目前用于识别电路的技术不能用于提取它以供独立使用。在这项工作中,我们提出了一种新方法,可以自动提取LLM的子集,该子集能够正确执行目标任务,无需额外的训练,只需要少量的数据样本。我们在不同的任务上评估了我们的方法,结果表明,由此产生的模型(i)显著更小,参数数量减少高达82.77%,并且(ii)更具可解释性,因为它们专注于用于执行特定任务的电路,因此可以使用MI技术来理解。
🔬 方法详解
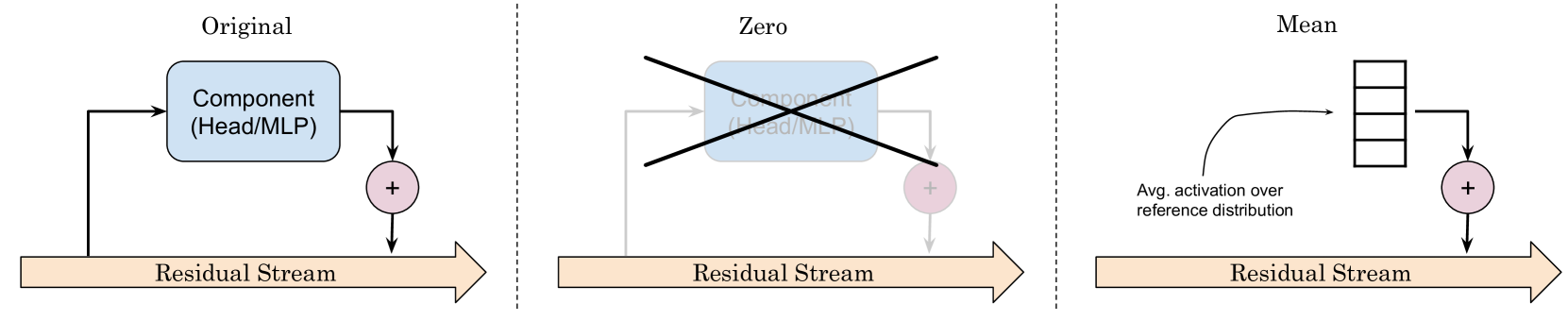
问题定义:现有的大型语言模型虽然能力强大,但在特定任务上部署时,模型体积过大导致推理速度慢,资源消耗高。同时,模型中存在大量与当前任务无关的参数,造成了计算资源的浪费。现有的机制可解释性方法虽然可以识别出执行特定任务的电路,但无法将其提取出来独立使用。
核心思路:该论文的核心思路是,通过某种方式自动识别并提取出大型语言模型中执行特定任务的关键子网络(即任务特定电路),从而创建一个更小、更高效的模型,专门用于该任务。这样既可以减少计算量,提高推理速度,又可以提高模型的可解释性。
技术框架:该方法主要包含以下几个阶段:1. 确定目标任务;2. 收集少量与目标任务相关的数据样本;3. 使用某种算法自动识别并提取出LLM中执行该任务的关键子网络;4. 将提取出的子网络作为一个独立的模型进行部署和推理。具体的技术细节未知,摘要中没有详细描述。
关键创新:该方法最重要的创新点在于,它能够自动地从大型语言模型中提取出任务特定的电路,而无需进行额外的训练。这与传统的模型压缩方法(如剪枝、量化等)不同,后者通常需要对模型进行微调才能保持性能。此外,该方法提取出的模型更具可解释性,因为它们只包含执行特定任务的关键组件。
关键设计:由于摘要中没有提供详细的技术细节,因此无法得知具体的参数设置、损失函数、网络结构等关键设计。这部分内容需要在阅读完整论文后才能进行分析。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法能够显著减小模型体积,参数数量减少高达82.77%。同时,提取后的模型更具可解释性,可以利用机制可解释性技术进行理解。这些结果表明,该方法在提高模型效率和可解释性方面具有显著优势。
🎯 应用场景
该研究成果可应用于各种需要快速推理和资源受限的场景,例如移动设备上的自然语言处理、边缘计算环境中的智能助手等。通过提取任务特定电路,可以显著减小模型体积,提高推理速度,降低功耗,从而使得大型语言模型能够在更多场景中得到应用。
📄 摘要(原文)
Large Language Models (LLMs) have shown impressive performance across a wide range of tasks. However, the size of LLMs is steadily increasing, hindering their application on computationally constrained environments. On the other hand, despite their general capabilities, there are many situations where only one specific task is performed, rendering all other capabilities unnecessary and wasteful. This leads us to the following question: Is it possible to extract the minimal subset from an LLM that is able to perform a specific task in a faster, standalone manner? Recent works on Mechanistic Interpretability (MI) have shown that specific tasks are performed by a localized subset of components, or circuit. However, current techniques used to identify the circuit cannot be used to extract it for its standalone usage. In this work, we propose a novel approach to automatically extract the subset of the LLM that properly performs a targeted task requiring no additional training and a small amount of data samples. We evaluate our approach on different tasks and show that the resulting models are (i) considerably smaller, reducing the number of parameters up to 82.77% and (ii) more interpretable, as they focus on the circuit that is used to carry out the specific task, and can therefore be understood using MI techniques.