Beyond Human Data: Aligning Multimodal Large Language Models by Iterative Self-Evolution
作者: Wentao Tan, Qiong Cao, Yibing Zhan, Chao Xue, Changxing Ding
分类: cs.LG
发布日期: 2024-12-20
备注: AAAI 2025. The code is available at https://github.com/WentaoTan/SENA
💡 一句话要点
提出迭代自进化框架,无需人工标注对齐多模态大语言模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 自进化学习 图像理解 视觉问答 偏好对齐
📋 核心要点
- 现有MLLM对齐方法依赖人工或GPT标注数据,成本高且可扩展性差,限制了模型性能。
- 提出一种多模态自进化框架,通过图像驱动的自提问和答案自增强机制,实现自主数据生成和模型优化。
- 实验表明,该框架性能与依赖外部信息的方法相当,提供了一种更高效且可扩展的MLLM对齐方案。
📝 摘要(中文)
人工偏好对齐能够显著提升多模态大语言模型(MLLM)的性能,但高质量偏好数据的收集成本高昂。一种有前景的解决方案是自进化策略,即模型在自身生成的数据上迭代训练。然而,现有技术仍然依赖于人工或GPT标注的数据,有时还需要额外的模型或标准答案。为了解决这些问题,我们提出了一种新颖的多模态自进化框架,该框架仅使用未标注的图像,就能使模型自主生成高质量的问题和答案。首先,我们实现了一种图像驱动的自提问机制,允许模型基于图像内容创建和评估问题,并在问题不相关或无法回答时重新生成。这为答案生成奠定了坚实的基础。其次,我们引入了一种答案自增强技术,从图像描述开始,以提高答案质量。我们还使用损坏的图像来生成拒绝的答案,形成不同的偏好对以进行优化。最后,我们将图像内容对齐损失函数与直接偏好优化(DPO)损失相结合,以减少幻觉,确保模型专注于图像内容。实验表明,我们的框架在性能上与使用外部信息的方法具有竞争力,为MLLM提供了一种更高效和可扩展的方法。
🔬 方法详解
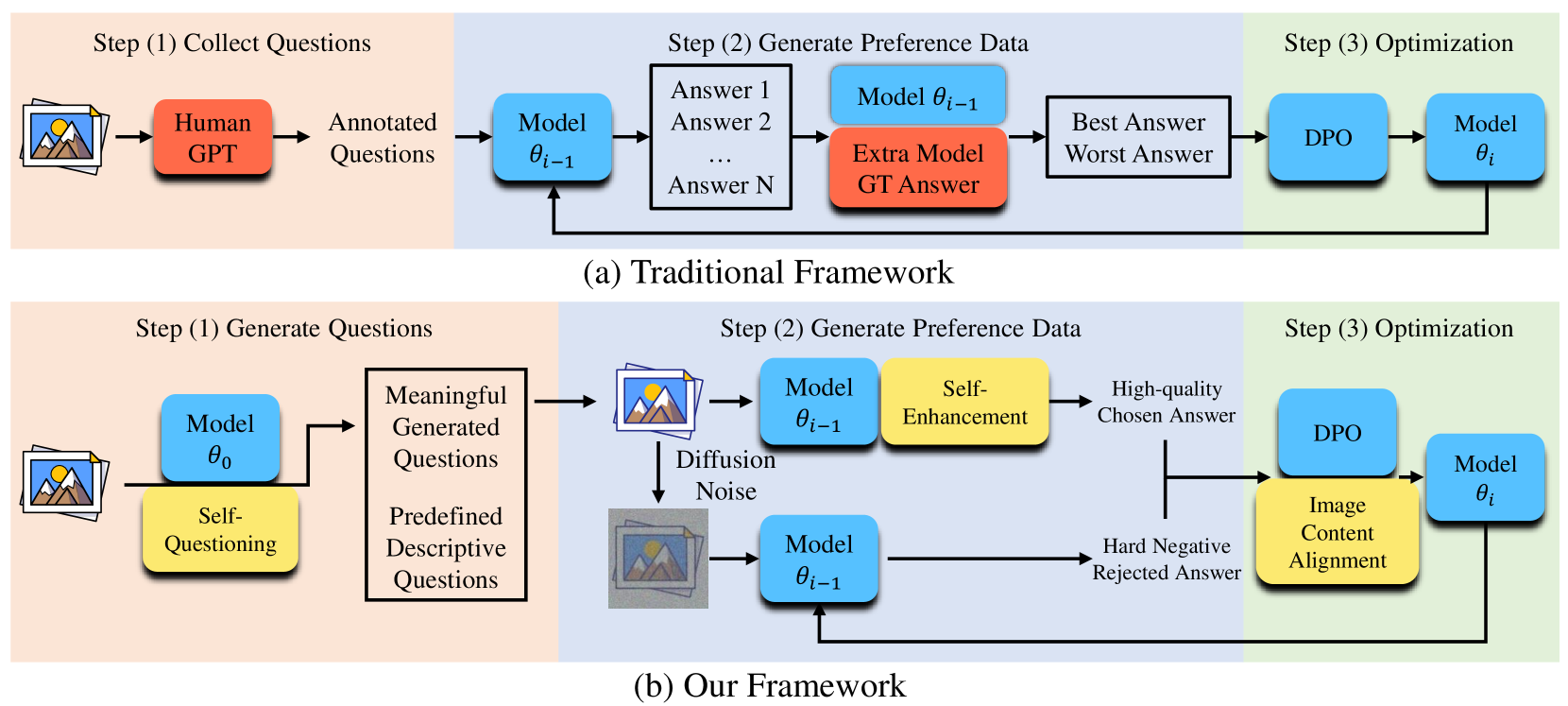
问题定义:现有方法在对齐多模态大语言模型时,需要大量人工标注或GPT生成的数据,成本高昂且难以扩展。此外,部分方法依赖额外的模型或标准答案,增加了复杂性。因此,如何降低数据依赖,实现高效、可扩展的MLLM对齐是一个关键问题。
核心思路:论文的核心思路是利用模型自身的生成能力,通过迭代自进化,在无需人工干预的情况下,逐步提升模型对图像内容的理解和表达能力。通过设计自提问和答案自增强机制,使模型能够自主生成高质量的训练数据,并利用这些数据进行优化。
技术框架:整体框架包含三个主要模块:1) 图像驱动的自提问:模型根据图像内容生成问题,并评估问题的相关性和可回答性,不合格的问题会被重新生成。2) 答案自增强:首先使用图像描述作为初始答案,然后通过进一步的优化和提炼,提高答案的质量。同时,利用损坏的图像生成负样本答案。3) 偏好对齐与内容对齐:使用直接偏好优化(DPO)损失函数,基于生成的正负样本答案进行偏好对齐。此外,引入图像内容对齐损失,以减少幻觉,确保模型关注图像内容。
关键创新:最重要的创新点在于完全摆脱了对人工标注或GPT生成数据的依赖,实现了完全自主的MLLM对齐。通过自提问和答案自增强机制,模型能够自主生成高质量的训练数据,并利用这些数据进行迭代优化。这种自进化的方式具有更高的效率和可扩展性。
关键设计:在自提问阶段,设计了问题相关性和可回答性的评估指标,用于筛选和重新生成不合格的问题。在答案自增强阶段,使用图像描述作为初始答案,并通过进一步的优化和提炼,提高答案的质量。同时,利用损坏的图像生成负样本答案,形成偏好对。在损失函数方面,结合了DPO损失和图像内容对齐损失,以实现偏好对齐和减少幻觉。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该框架在无需人工标注的情况下,性能与使用外部信息的方法具有竞争力。具体而言,在视觉问答任务上,该方法取得了与现有SOTA方法相当甚至更好的结果,证明了其有效性和优越性。同时,该方法显著降低了对数据的依赖,提高了训练效率和可扩展性。
🎯 应用场景
该研究成果可广泛应用于各种需要多模态理解和交互的场景,例如智能客服、图像搜索、视觉问答、机器人导航等。通过降低对人工标注数据的依赖,可以更高效地训练和部署MLLM,从而加速这些技术的普及和应用。此外,该方法也为其他领域的自监督学习提供了新的思路。
📄 摘要(原文)
Human preference alignment can greatly enhance Multimodal Large Language Models (MLLMs), but collecting high-quality preference data is costly. A promising solution is the self-evolution strategy, where models are iteratively trained on data they generate. However, current techniques still rely on human- or GPT-annotated data and sometimes require additional models or ground truth answers. To address these issues, we propose a novel multimodal self-evolution framework that enables the model to autonomously generate high-quality questions and answers using only unannotated images. First, we implement an image-driven self-questioning mechanism, allowing the model to create and evaluate questions based on image content, regenerating them if they are irrelevant or unanswerable. This sets a strong foundation for answer generation. Second, we introduce an answer self-enhancement technique, starting with image captioning to improve answer quality. We also use corrupted images to generate rejected answers, forming distinct preference pairs for optimization. Finally, we incorporate an image content alignment loss function alongside Direct Preference Optimization (DPO) loss to reduce hallucinations, ensuring the model focuses on image content. Experiments show that our framework performs competitively with methods using external information, offering a more efficient and scalable approach to MLLMs.