GFormer: Accelerating Large Language Models with Optimized Transformers on Gaudi Processors
作者: Chengming Zhang, Xinheng Ding, Baixi Sun, Xiaodong Yu, Weijian Zheng, Zhen Xie, Dingwen Tao
分类: cs.AR, cs.LG
发布日期: 2024-12-19
💡 一句话要点
GFormer:利用优化Transformer加速Gaudi处理器上的大语言模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 Transformer Gaudi处理器 稀疏注意力 线性注意力 硬件加速 模型优化 异构计算
📋 核心要点
- 现有Transformer模型在Gaudi等异构硬件上存在优化不足,尤其在非矩阵运算和长序列处理方面。
- GFormer融合稀疏和线性注意力机制,旨在充分利用Gaudi处理器的MME和TPC,提升计算效率。
- 实验结果表明,GFormer在Gaudi处理器上显著提高了效率和模型性能,超越了现有GPU方案。
📝 摘要(中文)
为了提升生成式AI任务中基于Transformer的大语言模型(LLM)的计算效率,异构硬件如Gaudi处理器应运而生,尤其擅长矩阵运算。然而,我们的分析表明,Transformer在此类新兴硬件上并未得到充分优化,主要原因是Softmax等非矩阵计算内核的优化不足,以及异构资源利用不充分,尤其是在处理长序列时。为了解决这些问题,我们提出了一种集成方法(称为GFormer),它融合了稀疏和线性注意力机制。GFormer旨在最大限度地发挥Gaudi处理器的矩阵乘法引擎(MME)和张量处理核心(TPC)的计算能力,同时不影响模型质量。GFormer包括一个窗口自注意力内核和一个用于因果线性注意力的有效外积内核,旨在优化Gaudi处理器上的LLM推理。评估表明,GFormer显著提高了Gaudi处理器上各种任务的效率和模型性能,并优于最先进的GPU。
🔬 方法详解
问题定义:论文旨在解决Transformer模型在大语言模型推理过程中,在Gaudi处理器等异构硬件上效率不高的问题。现有方法未能充分优化非矩阵计算内核(如Softmax),并且在处理长序列时,异构资源的利用率较低,导致计算瓶颈。
核心思路:论文的核心思路是通过融合稀疏注意力和线性注意力机制,设计一种新的Transformer架构(GFormer),以更好地适应Gaudi处理器的硬件特性。通过优化计算内核和资源分配,最大化矩阵乘法引擎(MME)和张量处理核心(TPC)的利用率,从而提高整体推理效率。
技术框架:GFormer的整体框架基于Transformer架构,主要包含以下模块:1) 嵌入层:将输入文本转换为向量表示。2) Transformer层:核心计算层,包含自注意力机制和前馈神经网络。3) 线性注意力模块:使用高效的外积内核实现因果线性注意力。4) 稀疏注意力模块:使用窗口自注意力内核,减少计算量。5) 输出层:将Transformer层的输出转换为最终的预测结果。
关键创新:GFormer的关键创新在于融合了稀疏注意力和线性注意力机制,并针对Gaudi处理器的硬件特性进行了优化。窗口自注意力内核减少了计算复杂度,而高效的外积内核加速了线性注意力的计算。这种混合方法在保持模型性能的同时,显著提高了推理速度。
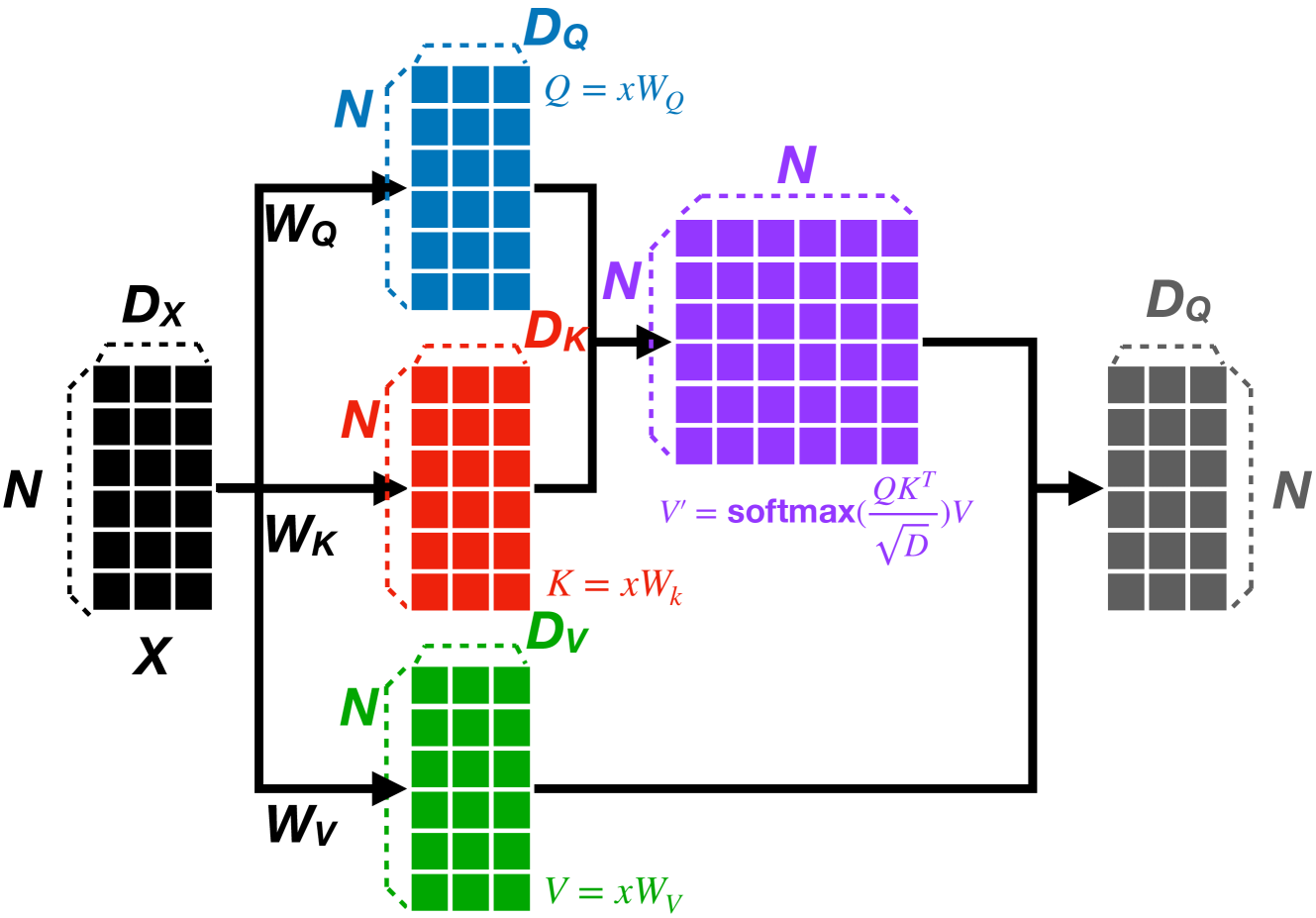
关键设计:GFormer的关键设计包括:1) 窗口自注意力:将全局注意力限制在局部窗口内,减少计算量。窗口大小是一个重要的超参数,需要根据具体任务进行调整。2) 因果线性注意力:使用外积内核高效计算线性注意力,避免了传统Softmax计算的瓶颈。3) 异构资源分配:根据不同计算任务的特点,合理分配MME和TPC资源,最大化硬件利用率。
🖼️ 关键图片

📊 实验亮点
论文实验结果表明,GFormer在Gaudi处理器上显著提高了效率和模型性能。具体来说,GFormer在多个NLP任务上优于现有的Transformer模型,并且在推理速度上超越了最先进的GPU方案。性能提升的具体幅度取决于任务和模型规模,但总体趋势是GFormer能够以更低的计算成本实现更高的精度。
🎯 应用场景
GFormer的潜在应用领域包括自然语言处理、机器翻译、文本生成、对话系统等。通过提高大语言模型的推理效率,GFormer可以降低部署成本,并支持更快的响应速度,从而提升用户体验。此外,GFormer还可以应用于资源受限的边缘设备,实现本地化的AI推理。
📄 摘要(原文)
Heterogeneous hardware like Gaudi processor has been developed to enhance computations, especially matrix operations for Transformer-based large language models (LLMs) for generative AI tasks. However, our analysis indicates that Transformers are not fully optimized on such emerging hardware, primarily due to inadequate optimizations in non-matrix computational kernels like Softmax and in heterogeneous resource utilization, particularly when processing long sequences. To address these issues, we propose an integrated approach (called GFormer) that merges sparse and linear attention mechanisms. GFormer aims to maximize the computational capabilities of the Gaudi processor's Matrix Multiplication Engine (MME) and Tensor Processing Cores (TPC) without compromising model quality. GFormer includes a windowed self-attention kernel and an efficient outer product kernel for causal linear attention, aiming to optimize LLM inference on Gaudi processors. Evaluation shows that GFormer significantly improves efficiency and model performance across various tasks on the Gaudi processor and outperforms state-of-the-art GPUs.