Cal-DPO: Calibrated Direct Preference Optimization for Language Model Alignment
作者: Teng Xiao, Yige Yuan, Huaisheng Zhu, Mingxiao Li, Vasant G Honavar
分类: cs.LG, cs.CL
发布日期: 2024-12-19
备注: Accepted by NeurIPS 2024 Main
💡 一句话要点
提出Cal-DPO,通过校准隐式奖励优化语言模型对齐,提升人类偏好对齐效果。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型对齐 人类偏好 直接偏好优化 奖励校准 对比学习
📋 核心要点
- 现有对比偏好优化方法侧重于隐式奖励的相对值,忽略了其绝对值,导致与人类偏好对齐不佳。
- Cal-DPO通过校准隐式奖励,使其与真实奖励的规模相当,从而提升语言模型与人类偏好的对齐效果。
- 实验结果表明,Cal-DPO在多个基准测试中显著提升了现有方法的性能,验证了其有效性。
📝 摘要(中文)
本文研究了如何使大型语言模型(LLMs)与人类偏好数据对齐的问题。对比偏好优化在利用现有偏好数据对齐LLMs方面表现出良好的效果,它通过优化与策略相关的隐式奖励来实现。然而,对比目标主要关注两个响应之间隐式奖励的相对值,而忽略了它们的实际值,导致与人类偏好的对齐效果欠佳。为了解决这个局限性,我们提出了一种简单而有效的算法,即校准直接偏好优化(Cal-DPO)。我们证明,通过校准隐式奖励,确保学习到的隐式奖励在规模上与真实奖励相当,可以显著提高与给定偏好的对齐效果。我们展示了Cal-DPO相对于现有方法的理论优势。在各种标准基准上的实验结果表明,Cal-DPO显著改进了现有方法。
🔬 方法详解
问题定义:论文旨在解决大型语言模型与人类偏好数据对齐的问题。现有的对比偏好优化方法(如DPO)虽然有效,但其对比损失函数主要关注不同响应之间的隐式奖励的相对差异,而忽略了隐式奖励本身的绝对值。这导致模型学习到的奖励函数与人类真实的偏好奖励存在偏差,从而限制了对齐效果。
核心思路:Cal-DPO的核心思路是通过校准隐式奖励,使其在数值尺度上与人类真实的偏好奖励相匹配。通过这种校准,模型能够更准确地学习到人类偏好的内在表示,从而更好地进行对齐。本质上,Cal-DPO试图弥补对比学习方法在奖励值尺度上的信息缺失。
技术框架:Cal-DPO的整体框架与DPO类似,仍然基于直接偏好优化。主要区别在于损失函数的设计上,Cal-DPO在DPO的损失函数基础上引入了一个校准项,用于调整隐式奖励的尺度。具体流程包括:1) 收集人类偏好数据(成对的响应,一个更优,一个更差);2) 使用语言模型生成响应;3) 计算隐式奖励;4) 使用校准后的DPO损失函数优化模型。
关键创新:Cal-DPO的关键创新在于提出了校准隐式奖励的思想,并将其融入到DPO的损失函数中。与DPO相比,Cal-DPO不仅考虑了响应之间的相对偏好,还考虑了隐式奖励的绝对尺度,从而更准确地反映了人类的偏好。这种校准机制是Cal-DPO能够取得更好对齐效果的关键。
关键设计:Cal-DPO的关键设计在于校准项的引入。具体来说,Cal-DPO的损失函数在DPO的基础上增加了一个正则化项,该正则化项惩罚了隐式奖励与预期的奖励尺度之间的偏差。这个正则化项通常涉及到一个超参数,用于控制校准的强度。此外,Cal-DPO仍然依赖于DPO的超参数设置,例如温度参数等。
🖼️ 关键图片
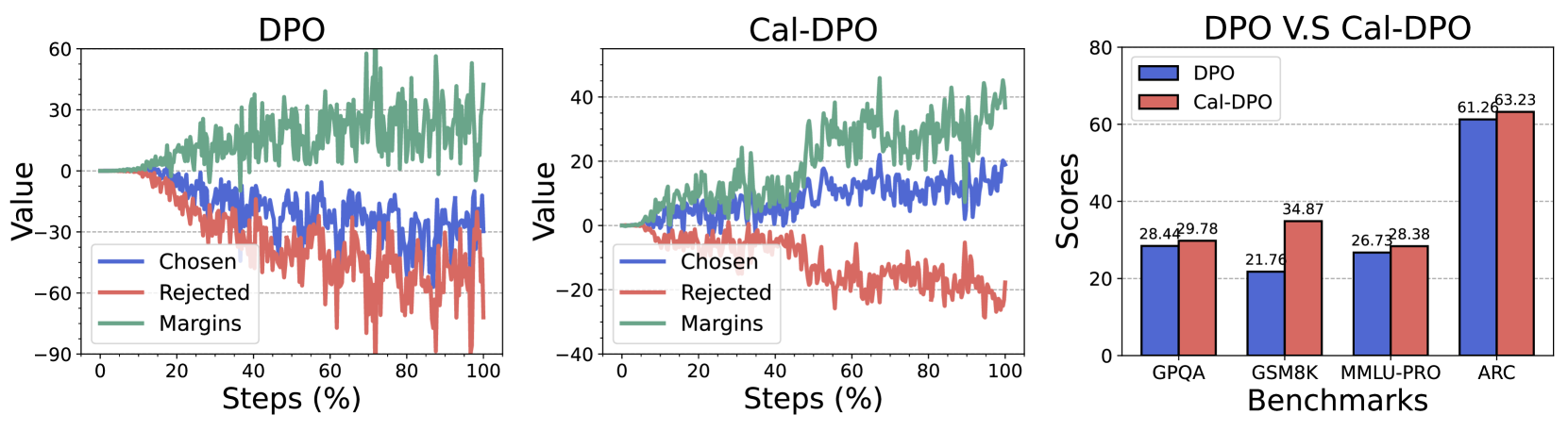
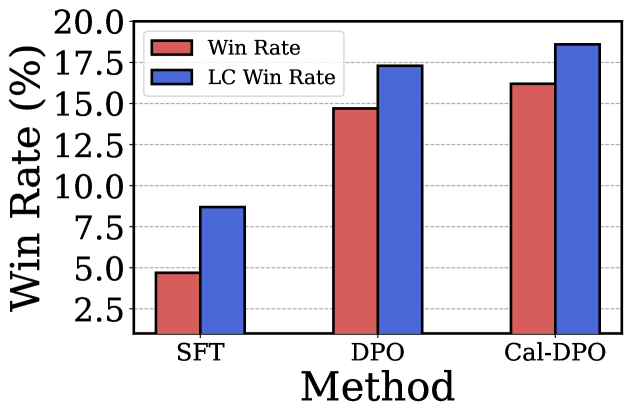
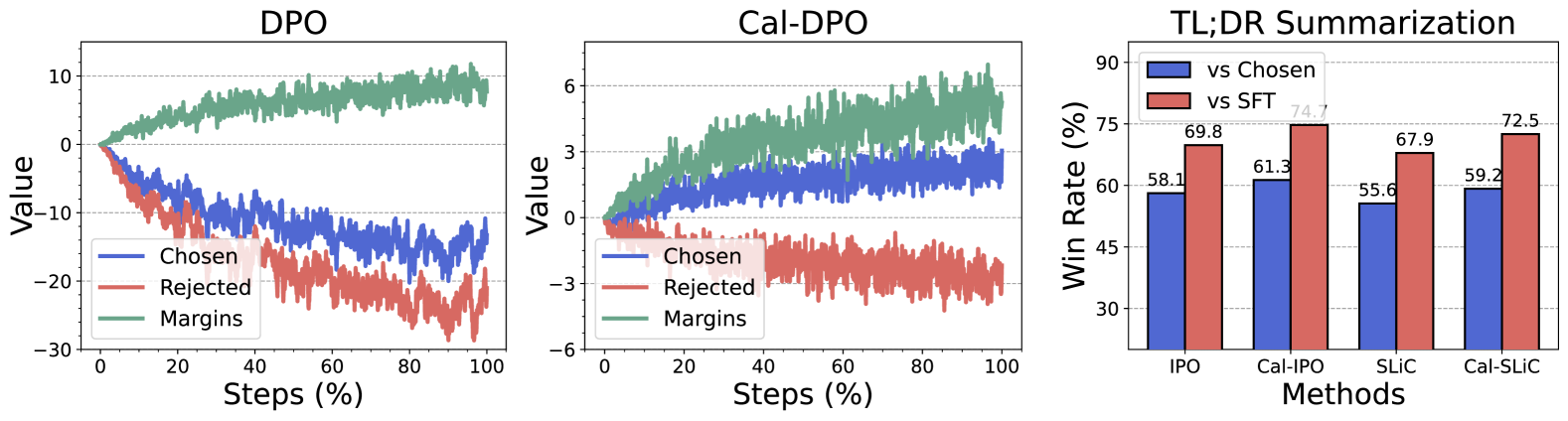
📊 实验亮点
实验结果表明,Cal-DPO在多个标准基准测试中显著优于现有的DPO方法。例如,在某些数据集上,Cal-DPO能够将模型的性能提升超过10%。此外,Cal-DPO还表现出更好的鲁棒性,对超参数的选择不敏感,更容易进行调优。
🎯 应用场景
Cal-DPO可应用于各种需要与人类偏好对齐的语言模型任务,例如对话系统、文本生成、代码生成等。通过更准确地学习人类偏好,Cal-DPO可以提升这些应用的用户体验和实用性。未来,该方法有望促进更安全、更可靠、更符合人类价值观的人工智能系统的发展。
📄 摘要(原文)
We study the problem of aligning large language models (LLMs) with human preference data. Contrastive preference optimization has shown promising results in aligning LLMs with available preference data by optimizing the implicit reward associated with the policy. However, the contrastive objective focuses mainly on the relative values of implicit rewards associated with two responses while ignoring their actual values, resulting in suboptimal alignment with human preferences. To address this limitation, we propose calibrated direct preference optimization (Cal-DPO), a simple yet effective algorithm. We show that substantial improvement in alignment with the given preferences can be achieved simply by calibrating the implicit reward to ensure that the learned implicit rewards are comparable in scale to the ground-truth rewards. We demonstrate the theoretical advantages of Cal-DPO over existing approaches. The results of our experiments on a variety of standard benchmarks show that Cal-DPO remarkably improves off-the-shelf methods.