ResQ: Mixed-Precision Quantization of Large Language Models with Low-Rank Residuals
作者: Utkarsh Saxena, Sayeh Sharify, Kaushik Roy, Xin Wang
分类: cs.LG, cs.CL
发布日期: 2024-12-18 (更新: 2025-02-03)
备注: 18 pages, 7 figures, 10 tables
🔗 代码/项目: GITHUB
💡 一句话要点
提出ResQ以解决大语言模型量化中的高量化误差问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 后训练量化 大语言模型 混合精度 主成分分析 低秩子空间 计算效率 异常值抑制
📋 核心要点
- 现有方法在将大语言模型的权重和激活量化为低位数时,面临高量化误差的问题,尤其是由于激活中的极端异常值。
- ResQ方法通过主成分分析识别低秩子空间,在该空间内保持高精度,而将其他部分量化为4位,从而有效降低量化误差。
- 在Llama和Qwen2.5模型上,ResQ在多个基准测试中表现优异,困惑度降低33%,并实现了比16位基线快3倍的推理速度。
📝 摘要(中文)
后训练量化(PTQ)大语言模型(LLMs)有助于降低推理时的计算成本。然而,将所有权重、激活和关键值(KV)缓存张量量化为4位而不显著降低模型的泛化能力是一个挑战,主要由于激活中的极端异常值导致的高量化误差。为了解决这一问题,本文提出了ResQ,一种PTQ方法,通过主成分分析(PCA)识别激活方差最高的低秩子空间,并在该子空间内保持高精度系数(如8位),而将其余部分量化为4位。实验结果表明,ResQ在多个基准测试中优于近期的均匀和混合精度PTQ方法,Wikitext上的困惑度降低了33%。
🔬 方法详解
问题定义:本文旨在解决大语言模型在后训练量化过程中面临的高量化误差问题,现有方法在处理激活中的极端异常值时效果不佳,导致模型性能下降。
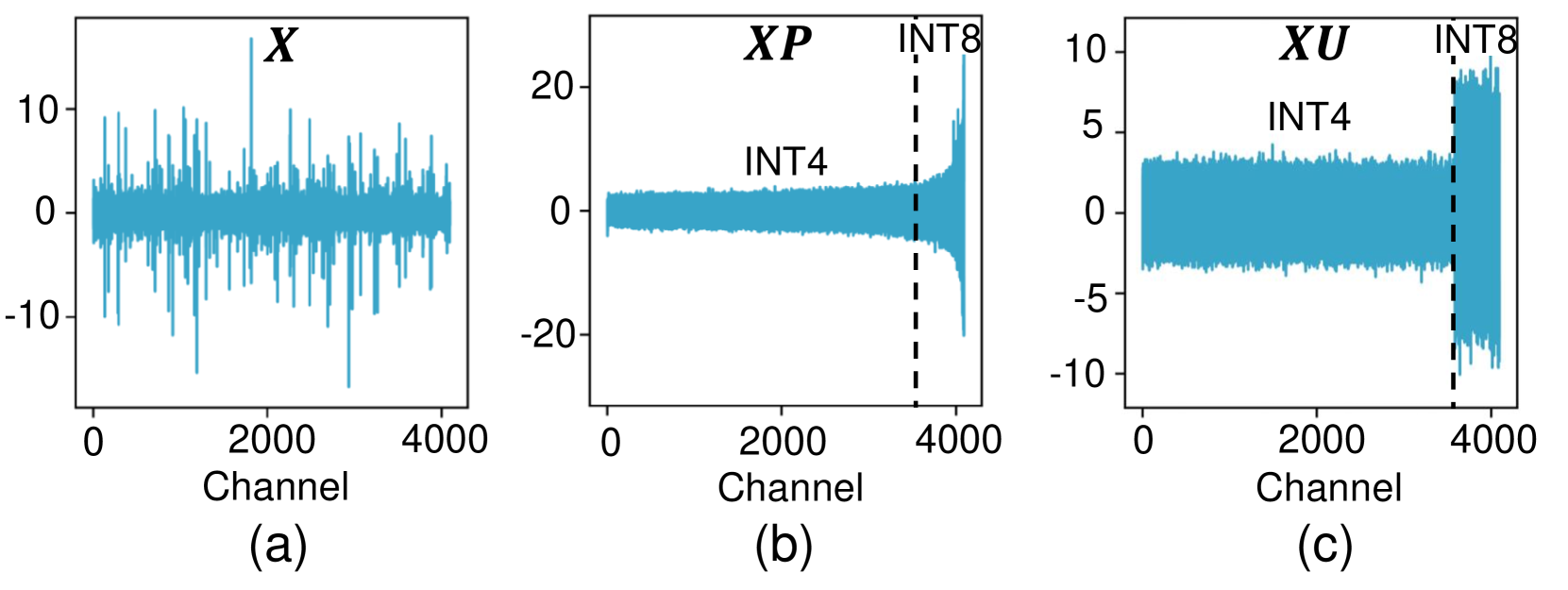
核心思路:ResQ方法的核心思路是通过主成分分析(PCA)识别激活方差最高的低秩子空间,并在该子空间内保持高精度(如8位),而将其他部分量化为4位,从而有效降低量化误差。
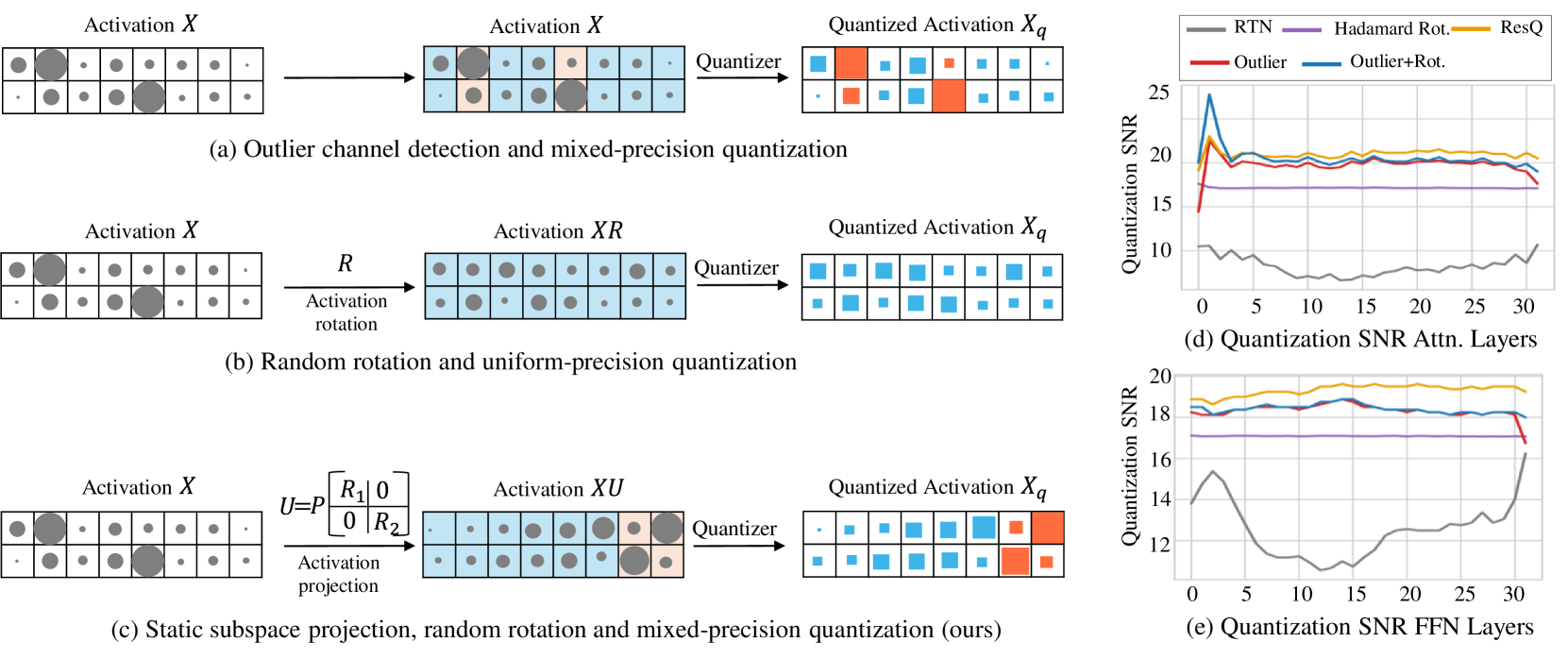
技术框架:ResQ的整体架构包括几个主要模块:首先,使用PCA识别低秩子空间;其次,在该子空间内应用高精度量化;最后,使用不变随机旋转进一步抑制异常值。
关键创新:ResQ的主要创新在于其混合精度量化方案,能够在保持模型性能的同时显著降低计算成本,与现有均匀量化方法相比,具有更优的性能表现。
关键设计:在设计中,ResQ选择了1/8的隐藏维度作为低秩子空间,并在该空间内使用8位精度进行量化,其他部分则量化为4位。此外,采用不变随机旋转技术来进一步减少异常值的影响。
🖼️ 关键图片
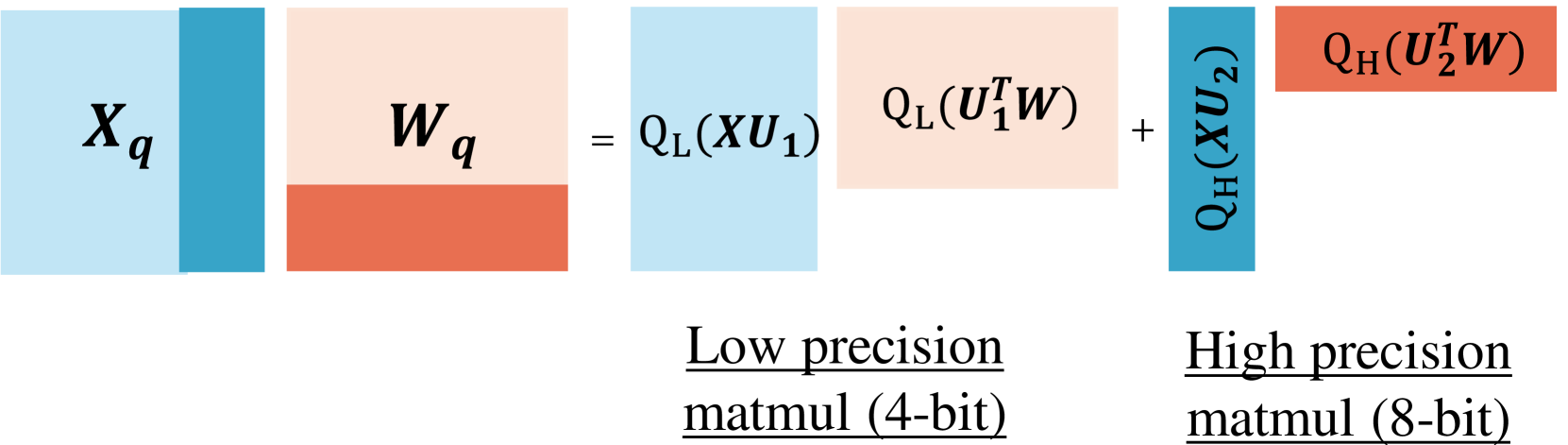
📊 实验亮点
实验结果显示,ResQ在Wikitext基准测试中实现了比SpinQuant方法低33%的困惑度,并且在推理速度上比16位基线快了3倍,展现了其在量化领域的显著优势。
🎯 应用场景
该研究在大语言模型的量化领域具有广泛的应用潜力,尤其适用于需要高效推理的场景,如自然语言处理、对话系统和机器翻译等。通过降低计算成本,ResQ能够使得大规模模型在资源受限的设备上运行,从而推动AI技术的普及与应用。
📄 摘要(原文)
Post-training quantization (PTQ) of large language models (LLMs) holds the promise in reducing the prohibitive computational cost at inference time. Quantization of all weight, activation and key-value (KV) cache tensors to 4-bit without significantly degrading generalizability is challenging, due to the high quantization error caused by extreme outliers in activations. To tackle this problem, we propose ResQ, a PTQ method that pushes further the state-of-the-art. By means of principal component analysis (PCA), it identifies a low-rank subspace (in practice 1/8 of the hidden dimension) in which activation variances are highest, and keep the coefficients within this subspace in high precision, e.g. 8-bit, while quantizing the rest to 4-bit. Within each subspace, invariant random rotation is applied to further suppress outliers. We show that this is a provably optimal mixed precision quantization scheme that minimizes error. With the Llama and Qwen2.5 families of models, we demonstrate that ResQ outperforms recent uniform and mixed precision PTQ methods on a variety of benchmarks, achieving up to 33\% lower perplexity on Wikitext than the next best method SpinQuant, and upto 3\times speedup over 16-bit baseline. Code is available at https://github.com/utkarsh-dmx/project-resq.