Enabling Realtime Reinforcement Learning at Scale with Staggered Asynchronous Inference
作者: Matthew Riemer, Gopeshh Subbaraj, Glen Berseth, Irina Rish
分类: cs.LG, cs.AI
发布日期: 2024-12-18
💡 一句话要点
提出交错异步推理,解决实时强化学习中大规模模型推理延迟问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 实时强化学习 异步推理 大规模模型 推理延迟 游戏AI
📋 核心要点
- 现有实时强化学习方法难以兼顾模型规模和推理速度,大型模型推理延迟导致智能体无法及时响应环境变化。
- 论文提出交错异步推理算法,通过并行执行多个推理过程,确保智能体以恒定时间间隔采取行动,从而克服推理延迟的限制。
- 实验表明,该方法允许使用比现有方法大几个数量级的模型,并在Game Boy游戏模拟环境中实现了有效的实时强化学习。
📝 摘要(中文)
实时环境在智能体执行动作推理和学习时不断变化,因此需要高交互频率以有效降低遗憾。然而,机器学习的最新进展涉及更大的神经网络,推理时间更长,这引发了它们在反应时间至关重要的实时系统中的适用性问题。我们分析了实时强化学习(RL)环境中遗憾的下界,表明在典型的顺序交互和学习范式中,通常不可能最小化长期遗憾,但当有足够的异步计算可用时,通常变得可能。我们提出了用于交错异步推理过程的新算法,以确保以一致的时间间隔采取行动,并证明使用具有高动作推理时间的模型仅受环境在推理范围内的有效随机性的约束,而不受动作频率的约束。我们的分析表明,所需推理过程的数量随着推理时间的增加而线性增加,同时能够使用比现有方法大几个数量级的模型,当从Game Boy游戏(如Pokémon和Tetris)的实时模拟中学习时。
🔬 方法详解
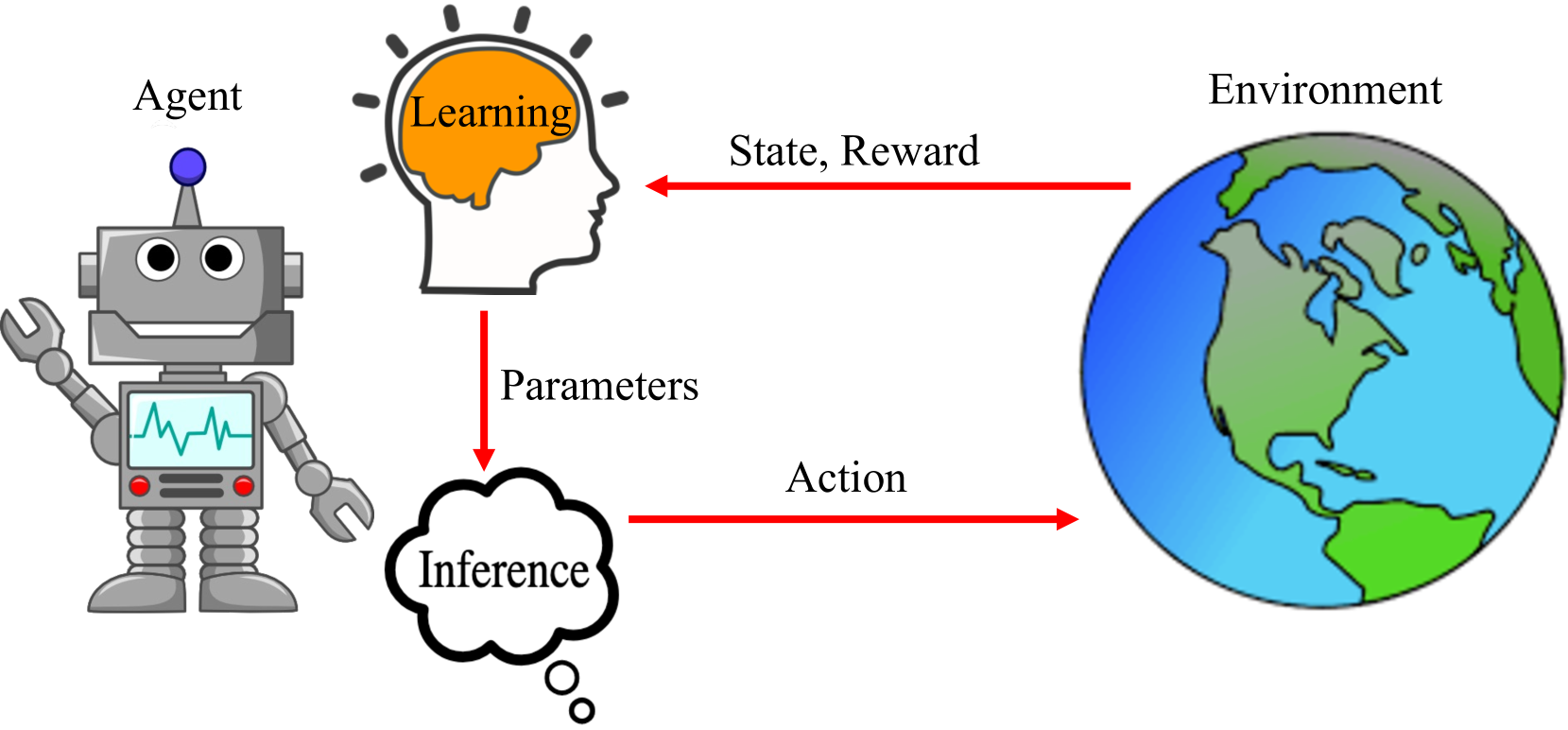
问题定义:实时强化学习面临的主要挑战是,智能体需要在快速变化的环境中进行决策。传统的顺序交互和学习范式中,智能体首先观察环境,然后进行推理,最后执行动作。当使用大型神经网络作为策略模型时,推理时间会显著增加,导致智能体无法及时响应环境变化,从而影响学习效果。现有方法难以在模型规模和推理速度之间取得平衡。
核心思路:论文的核心思路是利用异步计算,通过并行执行多个推理过程来克服推理延迟的限制。具体来说,智能体维护多个独立的推理进程,每个进程基于不同的环境状态进行推理。通过交错这些异步推理过程,智能体可以确保在每个时间步都有可用的动作,而无需等待单个推理过程完成。
技术框架:该方法的核心是交错异步推理算法。该算法维护一个推理进程池,每个进程负责基于不同的环境状态进行推理。算法的关键步骤包括:1) 从环境中采样新的状态;2) 将状态分配给一个空闲的推理进程;3) 当推理进程完成时,选择一个动作并将其发送到环境;4) 基于环境的反馈更新策略模型。通过这种方式,算法可以确保智能体以恒定的时间间隔采取行动,而无需等待单个推理过程完成。
关键创新:该方法最重要的创新点在于其异步推理机制。与传统的顺序推理方法不同,该方法允许智能体并行执行多个推理过程,从而显著减少了推理延迟。此外,该方法还提出了一种交错策略,确保智能体在每个时间步都有可用的动作,从而提高了学习效率。
关键设计:算法的关键设计包括:1) 推理进程池的大小:进程池的大小决定了智能体可以并行执行的推理过程的数量。进程池越大,推理延迟越小,但计算成本也越高。2) 动作选择策略:当多个推理进程完成时,需要选择一个动作发送到环境。论文中使用了简单的选择策略,例如选择具有最高概率的动作。3) 模型更新策略:基于环境的反馈更新策略模型。可以使用各种强化学习算法,例如Q-learning或策略梯度方法。
🖼️ 关键图片


📊 实验亮点
论文在Game Boy游戏模拟环境(包括Pokémon和Tetris)中进行了实验。实验结果表明,该方法允许使用比现有方法大几个数量级的模型,同时保持了较高的学习效率。例如,在Tetris游戏中,使用该方法训练的智能体能够达到与人类玩家相当的水平。
🎯 应用场景
该研究成果可应用于需要快速响应的实时控制系统,例如机器人控制、自动驾驶、金融交易等。通过使用更大规模的模型,智能体可以更好地理解环境并做出更明智的决策。此外,该方法还可以应用于游戏AI领域,例如训练能够实时玩复杂游戏的智能体。
📄 摘要(原文)
Realtime environments change even as agents perform action inference and learning, thus requiring high interaction frequencies to effectively minimize regret. However, recent advances in machine learning involve larger neural networks with longer inference times, raising questions about their applicability in realtime systems where reaction time is crucial. We present an analysis of lower bounds on regret in realtime reinforcement learning (RL) environments to show that minimizing long-term regret is generally impossible within the typical sequential interaction and learning paradigm, but often becomes possible when sufficient asynchronous compute is available. We propose novel algorithms for staggering asynchronous inference processes to ensure that actions are taken at consistent time intervals, and demonstrate that use of models with high action inference times is only constrained by the environment's effective stochasticity over the inference horizon, and not by action frequency. Our analysis shows that the number of inference processes needed scales linearly with increasing inference times while enabling use of models that are multiple orders of magnitude larger than existing approaches when learning from a realtime simulation of Game Boy games such as Pokémon and Tetris.