Adaptive Concept Bottleneck for Foundation Models Under Distribution Shifts
作者: Jihye Choi, Jayaram Raghuram, Yixuan Li, Somesh Jha
分类: cs.LG, cs.AI, cs.CV
发布日期: 2024-12-18
备注: The preliminary version of the work appeared in the ICML 2024 Workshop on Foundation Models in the Wild
💡 一句话要点
提出自适应概念瓶颈模型,提升基础模型在分布偏移下的可解释性和准确率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 概念瓶颈模型 可解释性 分布偏移 自适应学习 基础模型
📋 核心要点
- 现有基础模型微调后缺乏可解释性,在医疗等关键领域构成挑战,难以理解模型的决策依据。
- 提出自适应概念瓶颈框架,通过动态调整概念向量库和预测层,提升模型在分布偏移下的可解释性和准确率。
- 实验表明,该方法在多种真实分布偏移下,显著提升了概念对齐度和部署后准确率,最高提升达28%。
📝 摘要(中文)
本文探讨了概念瓶颈模型(CBMs)在将复杂、不可解释的基础模型转化为可解释决策流程中的潜力,利用高级概念向量实现可解释性。特别关注CBM流程在测试时部署于“野外”环境,即输入分布与原始训练分布存在偏移的情况。首先,识别了这种流程在不同类型分布偏移下的潜在失效模式。然后,提出了一个自适应概念瓶颈框架来解决这些失效模式,该框架仅基于来自目标域的无标签数据动态地调整概念向量库和预测层,无需访问源(训练)数据集。在各种真实世界分布偏移下的经验评估表明,该自适应方法产生了与测试数据更好对齐的基于概念的解释,并将部署后的准确率提高了高达28%,使CBM的性能与不可解释的分类性能相匹配。
🔬 方法详解
问题定义:论文旨在解决基础模型在分布偏移下,通过概念瓶颈模型(CBM)实现可解释性时,性能下降的问题。现有CBM方法在训练集和测试集分布一致时表现良好,但当测试集分布发生变化时,由于概念向量和预测层是固定的,导致概念表示与实际数据不符,最终影响预测准确率。
核心思路:核心思路是使CBM能够自适应目标域的分布变化。通过仅使用目标域的无标签数据,动态调整概念向量库和预测层,从而使概念表示更好地适应新的数据分布,提高模型在分布偏移下的性能和可解释性。
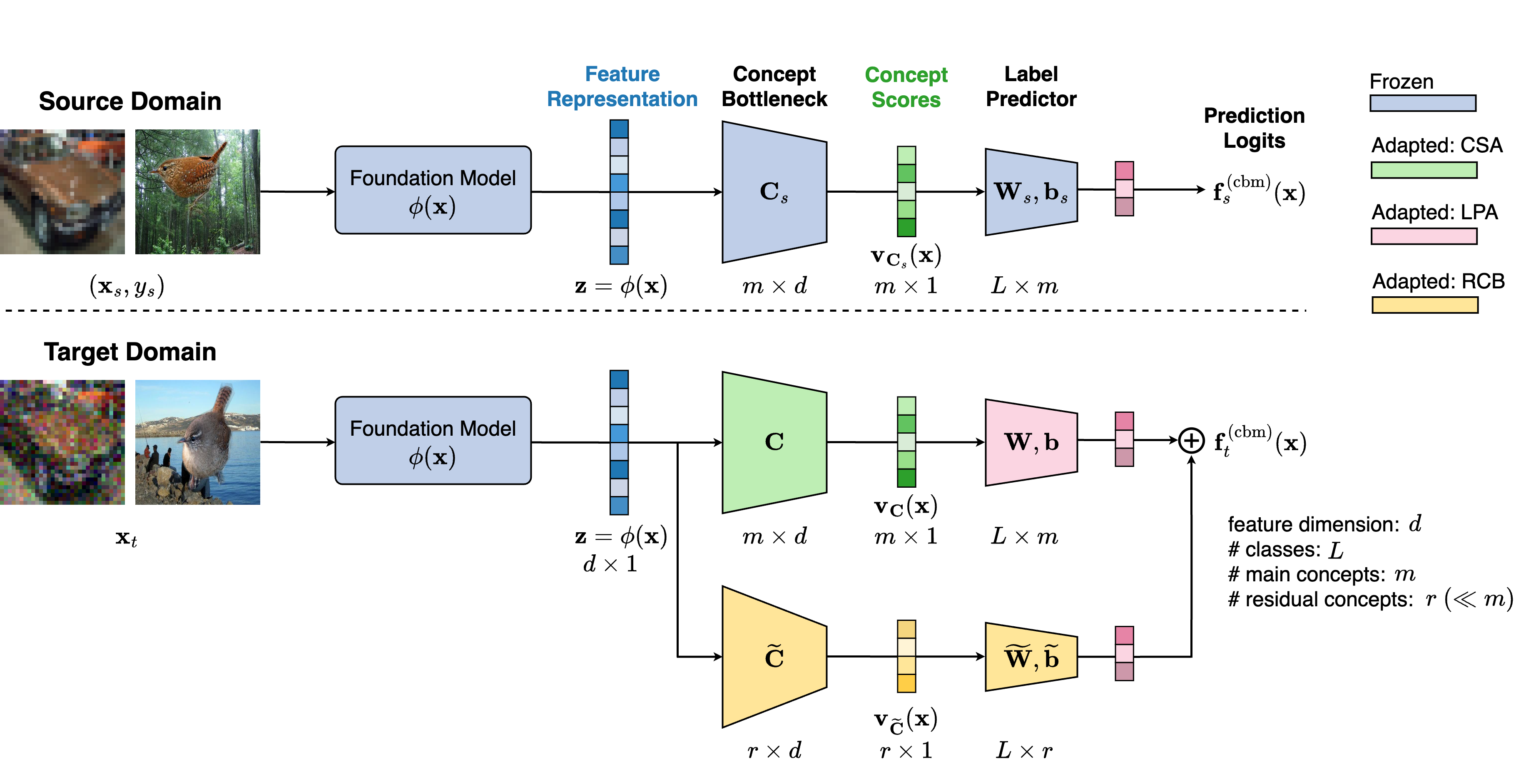
技术框架:整体框架包含三个主要部分:1) 预训练的基础模型,用于提取输入特征;2) 概念瓶颈层,将特征映射到一组预定义的概念向量;3) 预测层,基于概念向量进行最终的分类预测。关键在于,概念向量库和预测层在部署后可以根据目标域的无标签数据进行自适应调整。
关键创新:最重要的创新在于提出了自适应的概念瓶颈框架,能够在不访问源数据的情况下,仅利用目标域的无标签数据来调整概念向量库和预测层。这使得CBM能够适应分布偏移,保持甚至提升性能,同时保证模型的可解释性。与现有方法相比,该方法不需要重新训练整个模型,而是通过轻量级的自适应调整来实现性能提升。
关键设计:自适应过程的关键设计包括:1) 使用聚类算法(如K-means)对目标域的特征进行聚类,生成新的概念向量;2) 使用目标域数据微调预测层,使其更好地适应新的概念表示。损失函数的设计目标是最小化预测误差,同时保持概念表示的稀疏性和可解释性。具体的网络结构细节和参数设置在论文中有详细描述,但摘要中未提及。
🖼️ 关键图片

📊 实验亮点
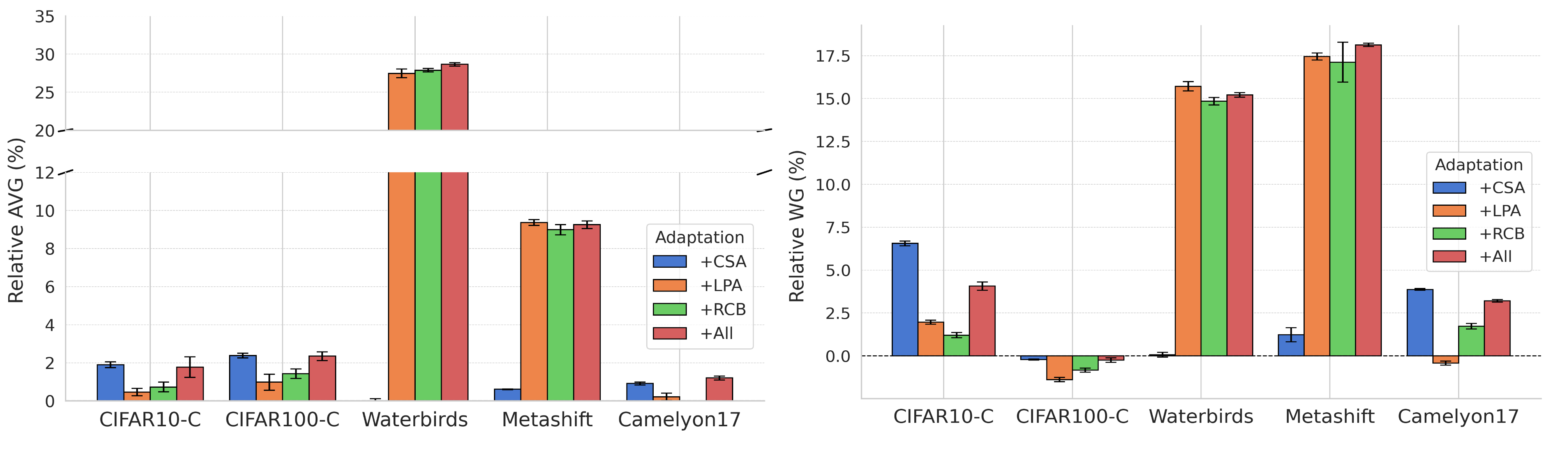
实验结果表明,提出的自适应概念瓶颈框架在各种真实世界的分布偏移下,显著提升了模型的性能。具体而言,该方法将部署后的准确率提高了高达28%,使CBM的性能与不可解释的分类性能相匹配。此外,实验还验证了该方法能够产生与测试数据更好对齐的基于概念的解释,从而提升了模型的可解释性。
🎯 应用场景
该研究成果可应用于医疗诊断、金融风控、安全监控等领域,在这些领域中,模型的可解释性至关重要。通过提供清晰的决策依据,该方法能够增强用户对模型的信任,并促进模型的部署和应用。未来,该方法可以进一步扩展到其他领域,并与其他可解释性技术相结合,构建更加可靠和透明的人工智能系统。
📄 摘要(原文)
Advancements in foundation models (FMs) have led to a paradigm shift in machine learning. The rich, expressive feature representations from these pre-trained, large-scale FMs are leveraged for multiple downstream tasks, usually via lightweight fine-tuning of a shallow fully-connected network following the representation. However, the non-interpretable, black-box nature of this prediction pipeline can be a challenge, especially in critical domains such as healthcare, finance, and security. In this paper, we explore the potential of Concept Bottleneck Models (CBMs) for transforming complex, non-interpretable foundation models into interpretable decision-making pipelines using high-level concept vectors. Specifically, we focus on the test-time deployment of such an interpretable CBM pipeline "in the wild", where the input distribution often shifts from the original training distribution. We first identify the potential failure modes of such a pipeline under different types of distribution shifts. Then we propose an adaptive concept bottleneck framework to address these failure modes, that dynamically adapts the concept-vector bank and the prediction layer based solely on unlabeled data from the target domain, without access to the source (training) dataset. Empirical evaluations with various real-world distribution shifts show that our adaptation method produces concept-based interpretations better aligned with the test data and boosts post-deployment accuracy by up to 28%, aligning the CBM performance with that of non-interpretable classification.