Energy-Based Preference Model Offers Better Offline Alignment than the Bradley-Terry Preference Model
作者: Yuzhong Hong, Hanshan Zhang, Junwei Bao, Hongfei Jiang, Yang Song
分类: cs.LG, cs.CL
发布日期: 2024-12-18
💡 一句话要点
提出基于能量的偏好模型,解决Bradley-Terry模型在离线对齐中的多解问题,提升LLM对齐效果。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 大型语言模型对齐 偏好建模 能量模型 对比学习 奖励模型
📋 核心要点
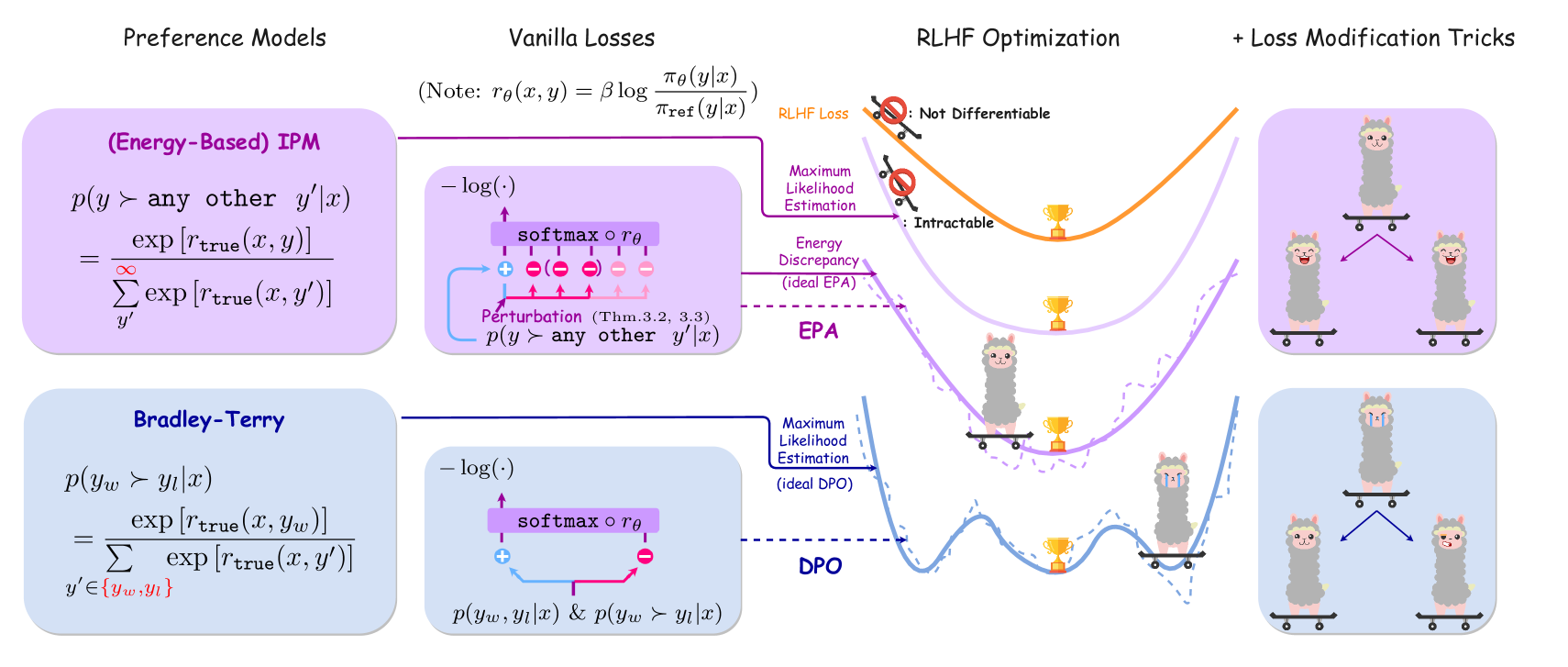
- DPO方法依赖的Bradley-Terry模型存在多解问题,导致奖励模型无法准确对齐人类偏好。
- 提出基于能量的模型(EBM)作为替代方案,该模型具有唯一的最大似然估计(MLE),天然满足线性要求。
- 设计能量偏好对齐(EPA)对比损失函数,通过对比正负样本逼近MLE,并在实验中验证了其优越性。
📝 摘要(中文)
本文指出,通过KL约束的RLHF损失对齐目标LLM与人类偏好在数学上等价于一种特殊的奖励建模任务。然而,DPO损失可能存在多个最小值,只有一个满足所需的线性条件。这个问题源于Bradley-Terry偏好模型的一个已知问题:它并不总是有唯一的最大似然估计(MLE)。因此,RLHF损失的最小值可能无法达到,因为它只是DPO损失的众多最小值之一。作为一种更好的替代方案,我们提出了一种基于能量的模型(EBM),它始终具有唯一的MLE,从而固有地满足线性要求。为了在实践中逼近MLE,我们提出了一种名为能量偏好对齐(EPA)的对比损失,其中每个正样本都与一个或多个强负样本以及许多自由弱负样本进行对比。我们的EBM的理论性质使得当使用足够数量的负样本时,EPA的逼近误差几乎肯定会消失。实验结果表明,与DPO相比,EPA在开放基准测试中始终提供更好的性能,从而证明了我们的EBM的优越性。
🔬 方法详解
问题定义:论文旨在解决使用DPO(Direct Preference Optimization)方法对齐大型语言模型(LLM)与人类偏好时遇到的问题。DPO依赖于Bradley-Terry偏好模型,该模型在某些情况下可能存在多个最大似然估计(MLE),导致训练出的奖励模型与真实奖励之间并非一一对应,从而影响对齐效果。现有方法的痛点在于无法保证奖励模型的唯一性和准确性。
核心思路:论文的核心思路是使用基于能量的模型(Energy-Based Model, EBM)替代Bradley-Terry模型。EBM具有一个关键优势:它始终存在唯一的最大似然估计(MLE)。通过将奖励建模任务转化为EBM的参数学习问题,可以确保学习到的奖励模型与真实奖励之间存在唯一的对应关系,从而提高对齐的准确性。这样设计的目的是为了避免DPO中由于Bradley-Terry模型的多解性而导致的对齐偏差。
技术框架:整体框架包括以下几个主要步骤:1) 使用目标LLM参数化EBM;2) 设计对比损失函数(EPA,Energy Preference Alignment)用于训练EBM,该损失函数通过对比正样本与强负样本和弱负样本来逼近MLE;3) 使用训练好的EBM作为奖励模型,指导LLM的对齐过程。主要模块包括EBM的构建、EPA损失函数的计算以及基于EBM的对齐策略。
关键创新:最重要的技术创新点在于使用EBM替代Bradley-Terry模型进行偏好建模。与Bradley-Terry模型不同,EBM保证了MLE的唯一性,从而避免了DPO中的多解问题。此外,EPA对比损失函数的设计也是一个创新点,它通过引入强负样本和弱负样本,更有效地逼近了EBM的MLE。
关键设计:EPA损失函数的关键设计在于对比策略。它不仅对比正样本和单个强负样本,还引入了多个自由的弱负样本。这种设计能够更全面地捕捉偏好信息,提高训练效率。具体而言,损失函数的形式是对比损失,鼓励正样本的能量值低于负样本的能量值。负样本的选择策略是关键,强负样本的选择需要一定的策略,而弱负样本则可以随机采样。
🖼️ 关键图片

📊 实验亮点
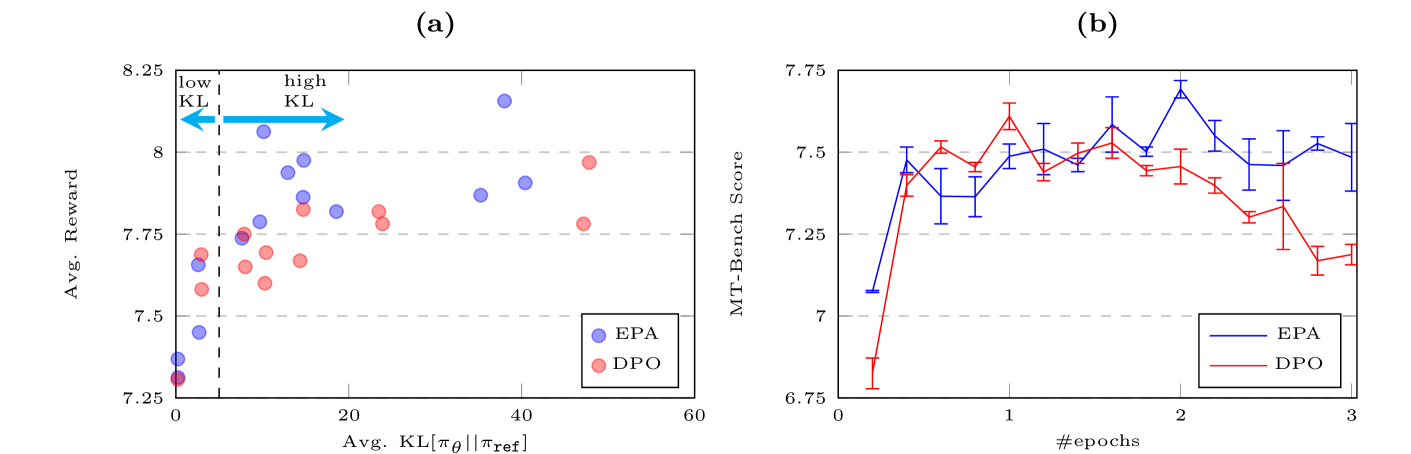
实验结果表明,与DPO相比,基于能量的偏好模型(EBM)在多个开放基准测试中始终表现出更好的性能。具体数据提升幅度未知,但结论是EBM在对齐效果上优于DPO,验证了EBM的优越性。
🎯 应用场景
该研究成果可广泛应用于大型语言模型的对齐训练,提升模型对人类偏好的理解和遵循能力。通过更准确的奖励模型,可以改善LLM在对话生成、文本摘要、代码生成等任务中的表现,使其更符合人类的期望和价值观。此外,该方法也为其他需要偏好建模的机器学习任务提供了新的思路。
📄 摘要(原文)
Since the debut of DPO, it has been shown that aligning a target LLM with human preferences via the KL-constrained RLHF loss is mathematically equivalent to a special kind of reward modeling task. Concretely, the task requires: 1) using the target LLM to parameterize the reward model, and 2) tuning the reward model so that it has a 1:1 linear relationship with the true reward. However, we identify a significant issue: the DPO loss might have multiple minimizers, of which only one satisfies the required linearity condition. The problem arises from a well-known issue of the underlying Bradley-Terry preference model: it does not always have a unique maximum likelihood estimator (MLE). Consequently,the minimizer of the RLHF loss might be unattainable because it is merely one among many minimizers of the DPO loss. As a better alternative, we propose an energy-based model (EBM) that always has a unique MLE, inherently satisfying the linearity requirement. To approximate the MLE in practice, we propose a contrastive loss named Energy Preference Alignment (EPA), wherein each positive sample is contrasted against one or more strong negatives as well as many free weak negatives. Theoretical properties of our EBM enable the approximation error of EPA to almost surely vanish when a sufficient number of negatives are used. Empirically, we demonstrate that EPA consistently delivers better performance on open benchmarks compared to DPO, thereby showing the superiority of our EBM.