RAT: Adversarial Attacks on Deep Reinforcement Agents for Targeted Behaviors
作者: Fengshuo Bai, Runze Liu, Yali Du, Ying Wen, Yaodong Yang
分类: cs.LG, cs.AI, cs.CR, cs.RO
发布日期: 2024-12-14
备注: Accepted by AAAI 2025
💡 一句话要点
RAT:针对深度强化学习智能体的目标行为对抗攻击
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 深度强化学习 对抗攻击 目标行为 鲁棒性 意图策略 机器人控制 安全关键系统
📋 核心要点
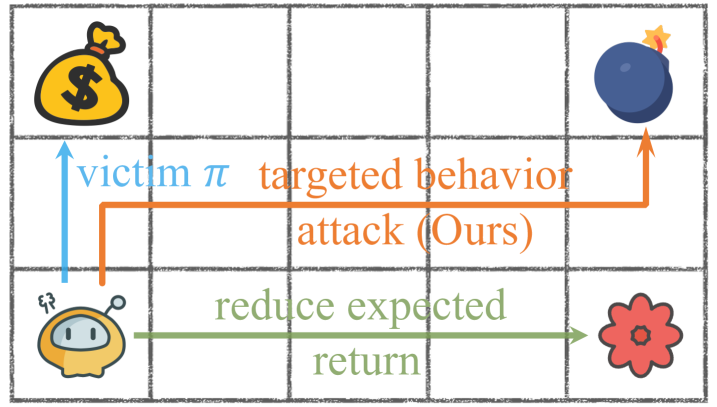
- 现有基于奖励的对抗攻击难以精确控制智能体的行为,尤其是在安全攸关的场景中,需要更精细的行为操纵。
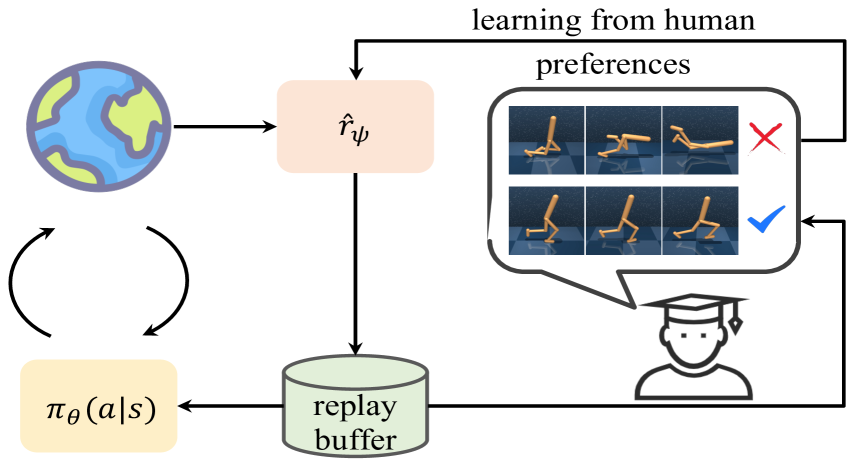
- RAT方法通过训练与人类偏好对齐的意图策略,作为对抗攻击的精确目标,并动态调整状态占用度量,实现更有效的行为操纵。
- 实验表明,RAT在诱导特定行为方面优于现有算法,并能提高智能体的鲁棒性,在MuJoCo任务中成功引导智能体学习人类偏好行为。
📝 摘要(中文)
评估深度强化学习(DRL)智能体在目标行为攻击下的表现,对于评估其鲁棒性至关重要。这类攻击旨在操纵受害者执行符合攻击者目标的特定行为,通常绕过传统的基于奖励的防御。先前的方法主要集中在减少累积奖励上;然而,奖励通常过于通用,无法有效地捕捉复杂的安全需求。因此,仅仅关注奖励减少可能导致次优的攻击策略,尤其是在需要更精确的行为操纵的安全关键场景中。为了应对这些挑战,我们提出了一种名为RAT的方法,用于通用、目标行为攻击。RAT训练一个与人类偏好明确对齐的意图策略,作为对抗者的精确行为目标。同时,对抗者操纵受害者的策略以遵循此目标行为。为了提高这些攻击的有效性,RAT动态调整回放缓冲区中的状态占用度量,从而实现更可控和有效的行为操纵。我们在机器人仿真任务上的实验结果表明,RAT在诱导特定行为方面优于现有的对抗攻击算法。此外,RAT在提高智能体鲁棒性方面显示出潜力,从而产生更具弹性的策略。我们通过引导决策转换器智能体在各种MuJoCo任务中采用与人类偏好对齐的行为来进一步验证RAT,证明了其在各种任务中的有效性。
🔬 方法详解
问题定义:论文旨在解决深度强化学习智能体在面对对抗攻击时,现有方法无法有效引导智能体产生特定目标行为的问题。现有方法主要通过降低累积奖励来攻击智能体,但奖励信号通常过于宽泛,难以精确控制智能体的行为,尤其是在需要满足复杂安全约束的场景下。因此,如何设计一种能够精确引导智能体产生目标行为的对抗攻击方法是本文要解决的核心问题。
核心思路:论文的核心思路是训练一个与人类偏好对齐的“意图策略”,作为对抗攻击的明确目标。对抗者通过操纵受害智能体的策略,使其尽可能地模仿意图策略的行为,从而实现对智能体的目标行为攻击。这种方法将对抗攻击的目标从降低奖励值转变为模仿特定行为,从而实现了更精确的行为控制。
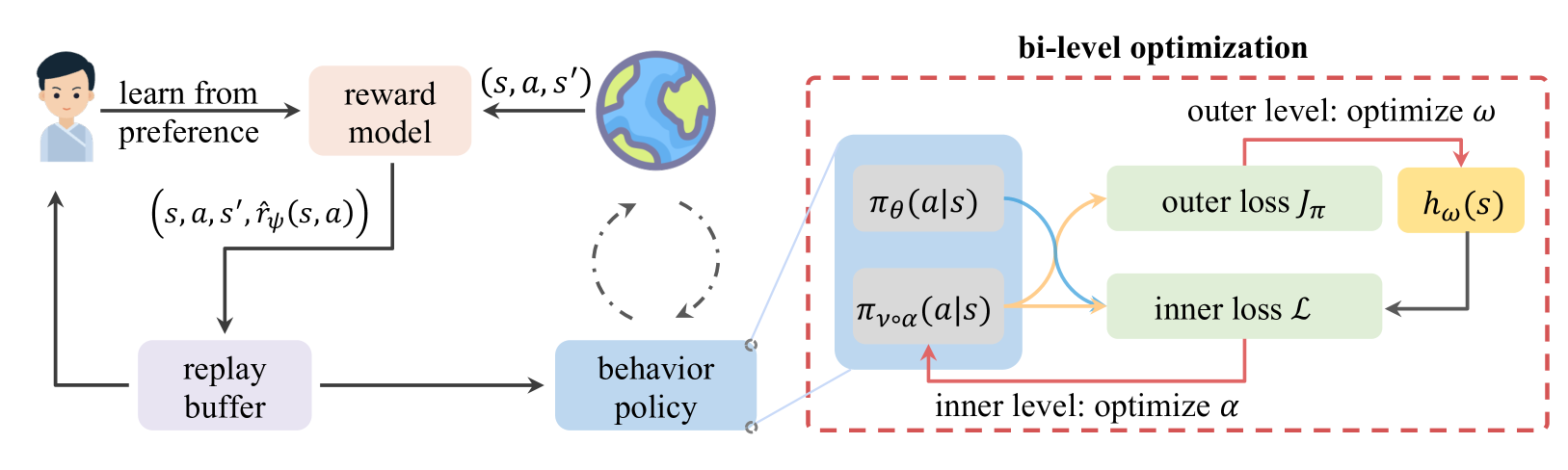
技术框架:RAT方法包含两个主要模块:意图策略训练模块和对抗攻击模块。首先,意图策略训练模块通过模仿学习或强化学习,训练一个能够产生目标行为的策略。然后,对抗攻击模块利用训练好的意图策略,通过对抗训练的方式,操纵受害智能体的策略,使其尽可能地接近意图策略的行为。为了提高攻击效果,RAT还引入了动态状态占用度量调整机制,用于调整回放缓冲区中不同状态的采样概率,从而更有效地引导智能体的行为。
关键创新:RAT方法的关键创新在于将对抗攻击的目标从降低奖励值转变为模仿特定行为。通过引入意图策略,RAT能够更精确地控制对抗攻击的目标行为,从而实现更有效的攻击。此外,动态状态占用度量调整机制能够更有效地引导智能体的行为,提高攻击的成功率。
关键设计:意图策略可以使用各种强化学习算法进行训练,例如PPO或DDPG。对抗攻击模块可以使用对抗训练的方法,例如FGSM或PGD。动态状态占用度量调整机制可以通过计算每个状态的访问频率,并根据访问频率调整采样概率来实现。损失函数通常包括两部分:一部分是受害智能体策略与意图策略之间的行为差异,另一部分是正则化项,用于防止受害智能体的策略发生剧烈变化。
🖼️ 关键图片
📊 实验亮点
实验结果表明,RAT方法在机器人仿真任务中,能够有效地引导智能体产生特定的目标行为,并且优于现有的对抗攻击算法。此外,RAT还能够提高智能体的鲁棒性,使其在面对对抗攻击时表现出更强的抵抗能力。在MuJoCo任务中,RAT成功地引导决策转换器智能体学习了与人类偏好对齐的行为。
🎯 应用场景
RAT方法可应用于评估和提高深度强化学习智能体在安全关键领域的鲁棒性,例如自动驾驶、机器人控制和金融交易。通过模拟各种目标行为攻击,可以发现智能体策略的潜在漏洞,并采取相应的防御措施。此外,RAT还可以用于引导智能体学习人类偏好行为,从而提高智能体在人机交互场景中的可用性和安全性。
📄 摘要(原文)
Evaluating deep reinforcement learning (DRL) agents against targeted behavior attacks is critical for assessing their robustness. These attacks aim to manipulate the victim into specific behaviors that align with the attacker's objectives, often bypassing traditional reward-based defenses. Prior methods have primarily focused on reducing cumulative rewards; however, rewards are typically too generic to capture complex safety requirements effectively. As a result, focusing solely on reward reduction can lead to suboptimal attack strategies, particularly in safety-critical scenarios where more precise behavior manipulation is needed. To address these challenges, we propose RAT, a method designed for universal, targeted behavior attacks. RAT trains an intention policy that is explicitly aligned with human preferences, serving as a precise behavioral target for the adversary. Concurrently, an adversary manipulates the victim's policy to follow this target behavior. To enhance the effectiveness of these attacks, RAT dynamically adjusts the state occupancy measure within the replay buffer, allowing for more controlled and effective behavior manipulation. Our empirical results on robotic simulation tasks demonstrate that RAT outperforms existing adversarial attack algorithms in inducing specific behaviors. Additionally, RAT shows promise in improving agent robustness, leading to more resilient policies. We further validate RAT by guiding Decision Transformer agents to adopt behaviors aligned with human preferences in various MuJoCo tasks, demonstrating its effectiveness across diverse tasks.